ACL2022 | 成分句法分析新进展:跨领域挑战与更稳健的句法分析器
![]()
作者:张岳
单位:西湖大学 工学院教授知乎:https://zhuanlan.zhihu.com/p/580410041
编辑:深度学习自然语言处理公众号
本文介绍实验室崔乐阳,杨森和我,在ACL 2022上对成分句法分析进行的探索。
Challenges to Open-Domain Constituency Parsing
Investigating Non-local Features for Neural Constituency Parsing
对于想要从头了解句法分析任务,以及其他自然语言处理任务和方法的同学,欢迎参考我们最近发布的《自然语言处理在线课程》:
https://www.zhihu.com/education/video-course/1564218549538607104?section_id=1566029317674303488
简介
成分句法分析是自然语言处理的基础任务之一,其目标是解析出文本中内在的短语结构句法树(如下图)。
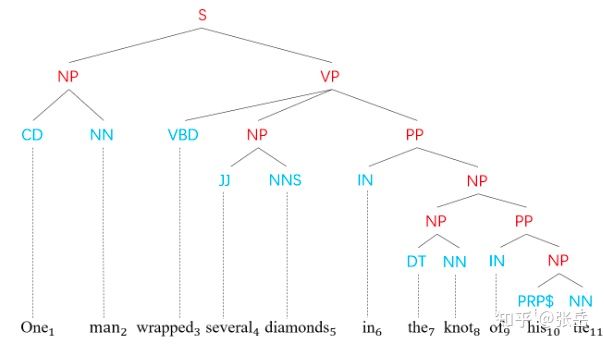 一个成分句法树的例子,其中红色为成分句法节点,蓝色为POS-tag节点。
一个成分句法树的例子,其中红色为成分句法节点,蓝色为POS-tag节点。
具体地,给定一个输入句子: ,对应的成分句法树 可以表示为一系列带 有标签的片段: ,其中 和 表示第 个成分句法片段开始和结束的 位置, 为对应的成分句法标签。
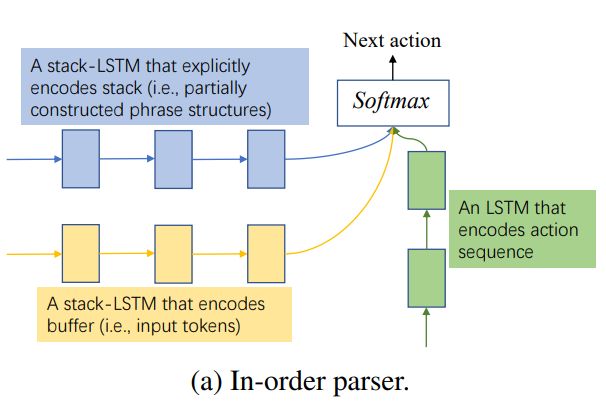 基于转移的句法分析方法
基于转移的句法分析方法 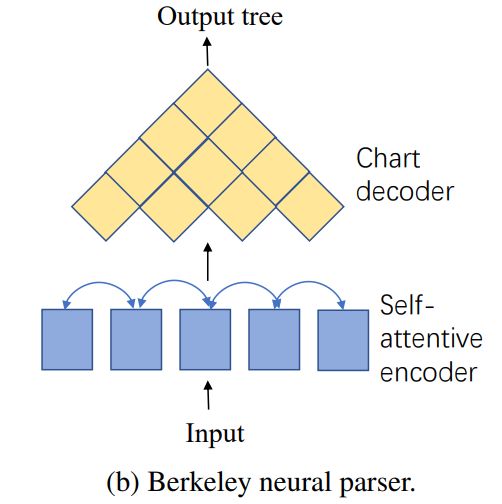 基于图的句法方法
基于图的句法方法
如上图,目前有两种主流方法进行成分句法分析:
基于转移的方法
基于图的方法
基于转移的方法通过预测转移操作序列来构建合法的成分句法树结构。转移操作序列可以被看成是对成分句法树的遍历操作。尽管基于转移的方法可以直接建模局部子树的结构,但由于每一步是单独进行局部预测的,这些局部预测可能会导致错误传播,导致性能不如基于图的直接对整个序列进行建模的方法。
基于图的方法通过一个强大的编码器对输入序列进行编码,然后使用打分函数对每个片段进行打分。解码的时候模型使用动态规划算法进行全局搜索寻找模型打分最高的树。随着深度学习和预训练语言模型的发展,成分句法分析器在英文宾大树库上已经取得超过96的 F1 值。
构建跨领域评价基准数据集
为了探究成分句法分析的跨领域能力,使成分句法分析更好地帮助开放领域下的自然语言处理下游任务,我们标注了一个多领域的成分句法测试集,其包含五个领域:对话、论坛、法律、文学、产品评论。
领域差异
我们首先设计一系列的语言学特征并计算了这些语言学特征在新闻领域PTB训练集和不同领域测试集上的相似度。越高的值表示该特征在该测试集上与PTB训练集越不相关。结果如下图所示:
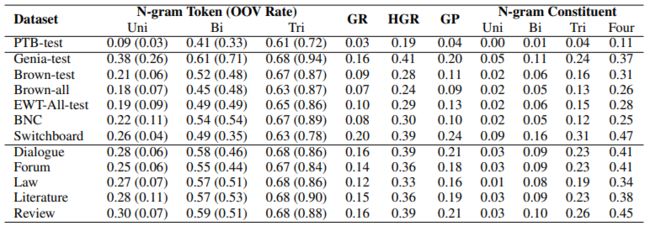 PTB(新闻领域)与其他各领域之间的领域差异,差异的计算方法为一系列语言学特征的Jensen–Shannon散度(JS-Divergence)
PTB(新闻领域)与其他各领域之间的领域差异,差异的计算方法为一系列语言学特征的Jensen–Shannon散度(JS-Divergence)
模型表现
下图展示了不同句法分析器在所有测试集上的表现。 错误率表示在使用BERT以后错误率的变化。
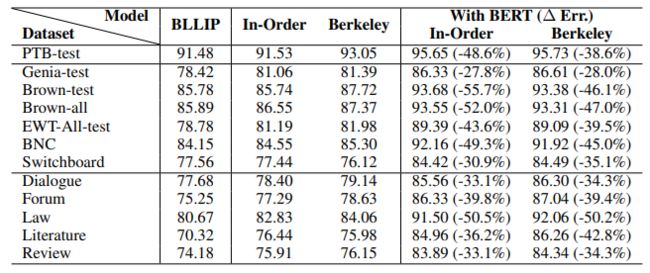 不同架构的模型在多个领域数据集上的表现
不同架构的模型在多个领域数据集上的表现
在PTB测试集上,两个使用BERT的模型均取得了超过95.5%的F1值。但在Genia、Brown、EWT上,带有BERT的模型表现降低到了86.33%(相对错误率增长233%)和93.68%(相对错误率增长45%)之间。根据上图结果中的分析,我们发现已有的跨领域数据集和PTB较为相似。与此相反的是,模型在跨领域测试集MCTB上表现甚至低于80%,相对下降率超过了387%。MCTB的五个领域中,对话和评论领域最难,基于BERT的句法分析器也只能取得低于80%的F1值。论坛和文献领域相对容易,模型表现都在85%左右。模型在法律领域上表现较好,所有模型表现都超过90%。直觉上讲,PTB上训练的模型在不同领域之间的表现与该领域与PTB的相似程度高度相关。领域与新闻领域差异越大,模型表现下降越明显。比如对话和评论中包含了很多非正式的语言,导致模型表现较差。法律与PTB的新闻领域都是标准的专业文本,风格较为相似,导致模型跨领域表现较好。
对比不同句法分析器的跨领域性能,我们发现使用BERT的in-order句法分析器在跨领域上的表现下降相对较小。这是对输出结构进行编码的模型比不对输出结构进行编码的模型在跨领域过程中更鲁邦。BLLIP和基于图的句法分析器在跨领域的表现下降相似,这说明使用离散特征的模型和基于图的模型在跨领域上鲁棒性相似。
在使用BERT的情况下,模型在论坛、法律、文献、评论这四个领域的错误率分别下降了10.0%、10.0%、13.0%、9.4%。这四个领域错误率的显著下降是因为它们的文本风格和BERT的预训练语聊非常接近。模型可以通过BERT预训练学习到的知识帮助进行跨领域句法分析。由于对话领域较为口语化与BERT的预训练语聊相差较大,导致对话领域错误率降低较少,仅为5.7%。
领域差异对模型跨领域性能的影响
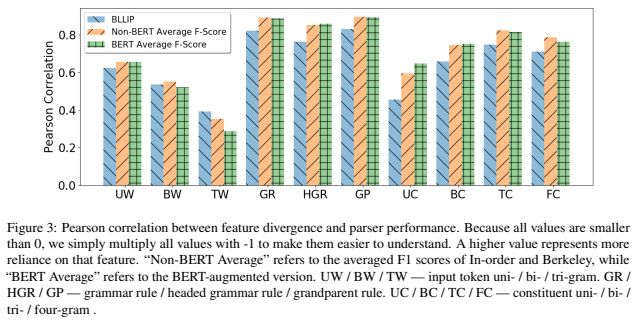 领域差异与模型跨领域性能之间的相关性
领域差异与模型跨领域性能之间的相关性
在上述基础上,我们进一步具体对不同特征对模型性能的影响进行进一步分析。上图展示了模型F1值与之前图中中JS散度的皮尔森线性相关系数。图中更长的柱表示模型更依赖该特征进行预测。
所有句法分析器都更依赖输出的结构特征比如语法规则(GR)、祖父母规则(GP)、-gram成分句法,而不是输入文本的特征比如-gram的词(UW、BW、TW)、单一成分句法(UC)等。这说明跨领域的挑战主要在于输出语法结构的差异,而不是输入文本用词的差异。
如何构建更鲁棒的句法分析器?
受益于神经网络的表征学习能力,基于图的成分句法分析器取得了优异的表现。然而,该方法并不直接对句法树的结构显示进行建模,它使用强大的神经网络编码器作为打分函数为局部字符段(Local Span)进行打分,仅依靠动态规划恢复出合法的成分句法树。我们尝试显示地将树结构信息注入到神经网络编码器中。
具体来说,如图上所示,我们把成分句法树中同一深度的个相邻节点定义为一个元非局部样式(-gram Non-local Pattern);并让模型在训练过程中额外预测元非局部样式。这样做可以让编码器在训练时注意到周围更大范围的非局部表征,从而学习到更多树结构的信息。为了进一步强化树结构信息,我们额外引入了一致性约束,让模型理解哪种成分句法可以成为哪种元非局部样式的子树,以便让模型更合法的恢复树结构。
基线模型:基于局部特征的神经句法分析器
我们在Berkeley Neural Parser的基础上验证注入子树信息的有效性。该模型使用多层transformer作为编码器(Encoder),并将输入文本的所有可能区间进行枚举、打分,随后这些区间的分数被送入一个动态规划的图解码器,以得到最高分的树结构输出。
给定输入句子 ,对应的成分句法树 可以表示为一系列带有标签的片 ,其中 和 表示第 个成分句法片段开始和结束的位置, 为对应的成分句法标签。
若有一个模型来为每个文本区间进行打分: ,则一个成分句法树 的总分数可以表示为: 。
具体到该基线模型上,它使用了BERT作为打分函数 ,并用一个基于图的动态规划算法来解码出分数最高的树结构,具体解码步骙可以参考这篇论文(A Minimal Span-Based Neural Constituency Parser)。详细来说,给定一个输入句子 ,经过BERT后得到对应的表征 ,因此,一个文本区间 的表征便可表示为 随后, 被输入进一个MLP,以得到一个分数
其中, 可以被看作是成分句法标签向量矩阵,矩阵中的每一列都对应着一个成分句法标签。 是句法表征 的特征维度, 是成分句法标签的个数。
引入编码树结构的辅助训练目标
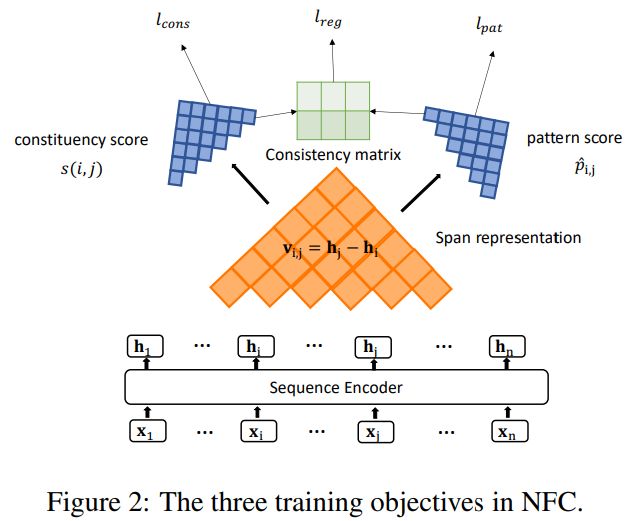 模型结构示意图,在原有的loss之外,我们增加了pattern-loss和consistency-loss来为模型的训练过程注入非局部结构化信息
模型结构示意图,在原有的loss之外,我们增加了pattern-loss和consistency-loss来为模型的训练过程注入非局部结构化信息
如上图所示,我们在训练打分函数的同时,额外引入了两个蓝色的训练目标,即pattern-loss和consistency-loss。
预测非局部样式的标签
我们引入了另一个MLP来预测前文所述的 元非局部样式:
,其中, 可以被看作 是 元非同部样式的标签向量矩阵, 是句法表征的特征维度, 是 元非同部样式标签 的个数。
预测非局部样式和局部特征之间的一致性
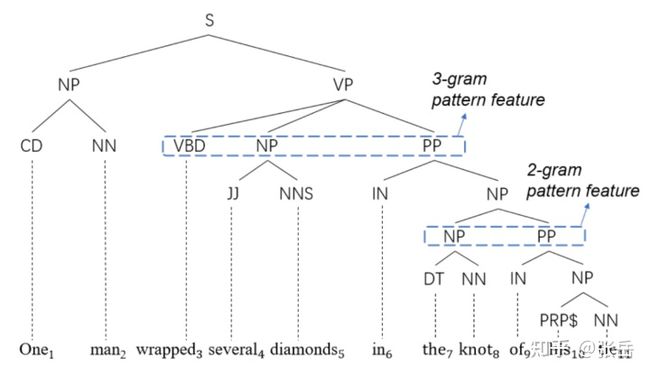 n元成分句法范式的示例
n元成分句法范式的示例
尽管前述两个训练目标(给句法标签打分、预测 元非局部样式)是基于相同的文本区间表征 ,但后续预测过程中,这二者仍旧是相互独立的。为了更好利用二者之间的依赖关系,我们提 出建模这二者之间的一致性,即:预测某个成分句法短语是否包含在某个 元非同部样式内。即预测某个成分句法短语是否可以成为某个n元非局部样式的子树。这可以看作是将先验语言学成分句法知识注入到模型中。以上图为例,NP和NNS可以作为 的子树出现在成分句法树 中,然而S或者ADJP不可以作为 的子树。
到了这一步,一个非常容易想到的方法是枚举每一对【成分句法短语, 元非局部样式】并计算匹配概率,但这一思路难以实现的。原因如下:给定一个长度为 的文本序列,所有可能的区间的数量即为 级别,而进一步进行两两匹配所产生的匹配数量更是在 级别,由此产生的额外计算量太大了。
为了解决上述问题,我们提出了一个语料库层面的一致性训练目标,具体来说,我们直接优化了 和 这两个标签向量矩阵之间的一致性联系: 其中, 是训练参数。
训练过程中,我们同时优化成分句法认练目标和两个引入的辅助训练目标。测试时,和Berkeley Neural Parser一样,我们使用模型估算 ,并用一个基于图的动态规划算法来解码出分数 最高的树结构。
实验结果
我们在新闻领域英文数据集(PTB)、新闻领域中文数据集(CTB)、多语言数据集SPMRL上进行了实验,并额外测试了新闻领域模型在跨领域测试集(GENIA,MCTB)上的表现。
 在PTB上的实验结果
在PTB上的实验结果 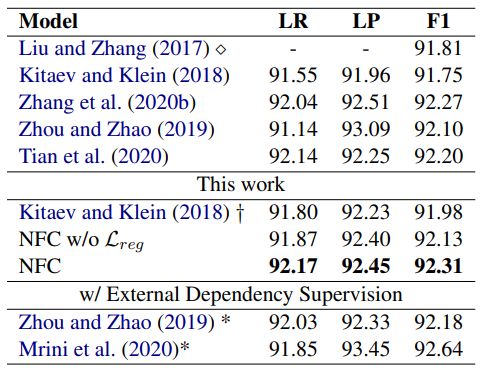 在CTB上的实验结果
在CTB上的实验结果  在跨领域场景下的测试结果
在跨领域场景下的测试结果  在多个语言上的实验结果
在多个语言上的实验结果
如结果所示,在常用的新闻领域数据集上,NFC取得了基于BERT最好的结果。在多语言实验和跨领域实验中,NFC相比基线模型也取得了提升。
论文额外分析了在引入两个辅助树结构训练目标后,模型是否学习到了更多树结构信息。我们在模型解码的成分句法树上计算同层连续预测成分句法范围的F1。
 模型预测n元成分句法范式的F1分数
模型预测n元成分句法范式的F1分数
从上图可以看出,在引入额外训练目标以后,NFC可以显著提升连续预测成分句法范围的性能,这表明NFC充分学习到了树结构的信息,显著帮助动态规划算法恢复出更合法的成分句法树。
总结
本文介绍了我们在成分句法分析上的探索。我们首先构建了高质量的跨领域成分句法测试集,并定量分析模型在跨领域时遇到的挑战。其次,我们构建了鲁棒的成分句法分析器NFC,使模型在公开领域性能显著提升。
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
COLING'22 | SelfMix:针对带噪数据集的半监督学习方法
ACMMM 2022 | 首个针对跨语言跨模态检索的噪声鲁棒研究工作
ACM MM 2022 Oral | PRVR: 新的文本到视频跨模态检索子任务
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~