4 线性分类
线性分类 { 硬分类 ( y ∈ { 0 , 1 } ) { 感知机 线性判别分析( F i s h e r D i s c r i m i n a n t A n a l y s i s ( L D A : L i n e a r D i s c r i m i n a n t A n a l y s i s ) ) 软分类 ( y ∈ ( 0 , 1 ) ) { 概率判别模型: L o g i s t i c R e g r e s s i o n 概率生成模型: { G a u s s i a n D i s c r i m i n a n t A n a l y s i s (连续) N a i v e B a y e s (离散) 线性分类 \begin{cases} 硬分类(y\in \{0,1\}) \begin{cases} 感知机\\ 线性判别分析(Fisher\ Discriminant\ Analysis(LDA:LinearDiscriminantAnalysis)) \end{cases} \\ 软分类(y\in (0,1)) \begin{cases} 概率判别模型:Logistic\ Regression \\ 概率生成模型: \begin{cases} Gaussian\ Discriminant\ Analysis(连续)\\ Naive\ Bayes(离散) \end{cases} \end{cases} \end{cases} 线性分类⎩ ⎨ ⎧硬分类(y∈{0,1}){感知机线性判别分析(Fisher Discriminant Analysis(LDA:LinearDiscriminantAnalysis))软分类(y∈(0,1))⎩ ⎨ ⎧概率判别模型:Logistic Regression概率生成模型:{Gaussian Discriminant Analysis(连续)Naive Bayes(离散)
y = f ( w T x + b ) y=f(w^Tx+b) y=f(wTx+b),其中f为激活函数
1 硬分类
分类结果是0或1
1.1 感知机
思想:错误驱动(数据分类错误的时候调整参数)
模型:
f ( x ) = s i g n ( w T x ) , x ∈ R p , w ∈ R p f(x)=sign(w^Tx),x\in\mathbb{R}^p,w\in\mathbb{R}^p f(x)=sign(wTx),x∈Rp,w∈Rp
其中 s i g n ( a ) = { + 1 , a ≥ 0 − 1 , a < 0 sign(a)=\begin{cases}+1,a\ge0\\-1,a<0\end{cases} sign(a)={+1,a≥0−1,a<0
loss function:
分对类的情况是 { y i = 1 , w T x i > 0 y i = − 1 , w T x i < 0 ⇒ y i w T x i > 0 \begin{cases}y_i=1,w^Tx_i>0\\y_i=-1,w^Tx_i<0\end{cases}\Rightarrow y_iw^Tx_i>0 {yi=1,wTxi>0yi=−1,wTxi<0⇒yiwTxi>0
因此分错类的情况是 y i w T x i < 0 y_iw^Tx_i<0 yiwTxi<0,将分错类的情况取反相加作为loss。
L ( w ) = ∑ i = 1 n ( − y i w T x i ) L(w)=\overset{n}{\underset{i=1}{\sum}}(-y_iw^Tx_i) L(w)=i=1∑n(−yiwTxi)
梯度 ∇ w L = − y i x i \nabla_wL=-y_ix_i ∇wL=−yixi
用SGD迭代求得最终w:(在线性可分的情况下)
w ( t + 1 ) ← w ( t ) − λ ∇ w L = w ( t ) + λ y i x i w^{(t+1)}\leftarrow w^{(t)}-\lambda \nabla_wL=w^{(t)}+\lambda y_ix_i w(t+1)←w(t)−λ∇wL=w(t)+λyixi
1.2 Fisher(LDA)
Linear Discriminant Analysis\Fisher Discriminant Analysis
X = ( x 1 , . . . , x n ) T = ( x 1 T ⋮ x n T ) = ( x 11 . . . x 1 p ⋮ ⋮ x n 1 . . . x n p ) n ∗ p Y = ( y 1 ⋮ y n ) n ∗ 1 X=(x_1,...,x_n)^T=\begin{pmatrix}x_1^T\\ \vdots \\ x_n^T\end{pmatrix}= \begin{pmatrix} x_{11} & ...& x_{1p}\\ \vdots & & \vdots\\ x_{n1}&...&x{np}\end{pmatrix}_{n*p} \quad Y=\begin{pmatrix}y_1\\ \vdots \\ y_n\end{pmatrix}_{n*1} X=(x1,...,xn)T=⎝ ⎛x1T⋮xnT⎠ ⎞=⎝ ⎛x11⋮xn1......x1p⋮xnp⎠ ⎞n∗pY=⎝ ⎛y1⋮yn⎠ ⎞n∗1
{ ( x i , y i ) } i = 1 n , x i ∈ R p , y i ∈ { + 1 , − 1 } \{(x_i,y_i)\}^n_{i=1},x_i\in\mathbb{R}^p,y_i\in\{+1,-1\} {(xi,yi)}i=1n,xi∈Rp,yi∈{+1,−1}
其中设+1为类1,-1为类2。他们的均值方差分别是 μ 1 , μ 2 , Σ 1 , Σ 2 \mu_1,\mu_2,\Sigma_1,\Sigma_2 μ1,μ2,Σ1,Σ2,那么:
μ = 1 n ∑ i = 1 n x i Σ = 1 n ∑ i = 1 n ( x i − μ ) ( x i − μ ) T \mu=\frac{1}{n}\overset{n}{\underset{i=1}{\sum}}x_i\\ \Sigma=\frac{1}{n}\overset{n}{\underset{i=1}{\sum}}(x_i-\mu)(x_i-\mu)^T μ=n1i=1∑nxiΣ=n1i=1∑n(xi−μ)(xi−μ)T
思想:
类内方差小,类间距大
找到一个投影方式 w T x w^Tx wTx,原数据在这个投影上每个相同类的点聚在一起,不同类之间的间距很远。如下图,右侧的投影更好。然后设定一个阈值(判别边界)来分类。
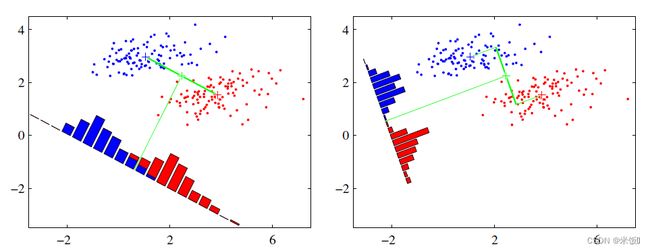
目标函数:
J ( w ) = ( μ 1 ′ − μ 2 ′ ) 2 Σ 1 ′ + Σ 2 ′ w ^ = a r g m a x w J ( w ) J(w)=\frac{(\mu_1'-\mu_2')^2}{\Sigma_1'+\Sigma_2'}\\ \hat{w}=arg\underset{w}{max}\ J(w) J(w)=Σ1′+Σ2′(μ1′−μ2′)2w^=argwmax J(w)
经过投影后,新的均值和方差:
μ ′ = 1 n ∑ i = 1 n w T x i = w T ∗ 1 n ∑ i = 1 n x i = w T μ Σ ′ = 1 n ∑ i = 1 n ( w T x i − μ ′ ) ( w T x i − μ ′ ) T = 1 n ∑ i = 1 n ( w T x i − w T μ ) ( w T x i − w T μ ) T = 1 n ∑ i = 1 n w T ( x i − μ ) ( x i − μ ) T w = w T [ 1 n ∑ i = 1 n ( x i − μ ) ( x i − μ ) T ] w = w T Σ w \mu'=\frac{1}{n}\overset{n}{\underset{i=1}{\sum}}w^Tx_i=w^T*\frac{1}{n}\overset{n}{\underset{i=1}{\sum}}x_i=w^T\mu\\ \begin{aligned} \Sigma'&=\frac{1}{n}\overset{n}{\underset{i=1}{\sum}}(w^Tx_i-\mu')(w^Tx_i-\mu')^T\\ &=\frac{1}{n}\overset{n}{\underset{i=1}{\sum}}(w^Tx_i-w^T\mu)(w^Tx_i-w^T\mu)^T\\ &=\frac{1}{n}\overset{n}{\underset{i=1}{\sum}}w^T(x_i-\mu)(x_i-\mu)^Tw\\ &=w^T[\frac{1}{n}\overset{n}{\underset{i=1}{\sum}}(x_i-\mu)(x_i-\mu)^T]w\\ &=w^T\Sigma w \end{aligned} μ′=n1i=1∑nwTxi=wT∗n1i=1∑nxi=wTμΣ′=n1i=1∑n(wTxi−μ′)(wTxi−μ′)T=n1i=1∑n(wTxi−wTμ)(wTxi−wTμ)T=n1i=1∑nwT(xi−μ)(xi−μ)Tw=wT[n1i=1∑n(xi−μ)(xi−μ)T]w=wTΣw
带入目标函数:
J ( w ) = ( w T μ 1 − w T μ 2 ) 2 w T Σ 1 w + w T Σ 2 w = w T ( μ 1 − μ 2 ) ( μ 1 − μ 2 ) T w w T ( Σ 1 + Σ 2 ) w \begin{aligned} J(w)&=\frac{(w^T\mu_1-w^T\mu_2)^2}{w^T\Sigma_1 w+w^T\Sigma_2 w}\\ &=\frac{w^T(\mu_1-\mu_2)(\mu_1-\mu_2)^Tw}{w^T(\Sigma_1 +\Sigma_2) w} \end{aligned} J(w)=wTΣ1w+wTΣ2w(wTμ1−wTμ2)2=wT(Σ1+Σ2)wwT(μ1−μ2)(μ1−μ2)Tw
令 S b = ( μ 1 − μ 2 ) ( μ 1 − μ 2 ) , S w = Σ 1 + Σ 2 S_b=(\mu_1-\mu_2)(\mu_1-\mu_2),S_w=\Sigma_1 +\Sigma_2 Sb=(μ1−μ2)(μ1−μ2),Sw=Σ1+Σ2
J ( w ) = w T S b w w T S w w J(w)=\frac{w^TS_bw}{w^TS_w w} J(w)=wTSwwwTSbw
对w求偏导
∂ J ( w ) ∂ w = 2 S b w ( w T S w w ) − 2 ( w T S b w ) S w w ( w T S w w ) 2 = 0 S b w ( w T S w w ) = ( w T S b w ) S w w \frac{\partial J(w)}{\partial w}=\frac{2S_bw(w^TS_w w)-2(w^TS_b w)S_ww}{(w^TS_w w)^2}=0\\ S_bw(w^TS_w w)=(w^TS_b w)S_ww \begin{aligned} \end{aligned} ∂w∂J(w)=(wTSww)22Sbw(wTSww)−2(wTSbw)Sww=0Sbw(wTSww)=(wTSbw)Sww
其中 S b , S w S_b,S_w Sb,Sw维度是p*p, w T w^T wT维度是1*p。因此 w T S b w , w T S w w w^TS_b w,w^TS_w w wTSbw,wTSww是标量。把标量放在一起有:
w T S w w w T S b w S b w = S w w \frac{w^TS_w w}{w^TS_b w}S_bw=S_ww wTSbwwTSwwSbw=Sww
这里是求投影的方向,不需要考虑投影的大小,也就是w的系数不重要,因此:
w = w T S w w w T S b w S w − 1 S b w ∝ S w − 1 S b w w=\frac{w^TS_w w}{w^TS_b w}S_w^{-1}S_bw \varpropto\ S_w^{-1}S_bw w=wTSbwwTSwwSw−1Sbw∝ Sw−1Sbw
将 S b S_b Sb带入:
w ∝ S w − 1 ( μ 1 ′ − μ 2 ′ ) ( μ 1 ′ − μ 2 ′ ) T w w\varpropto\ S_w^{-1}(\mu_1'-\mu_2')(\mu_1'-\mu_2')^Tw w∝ Sw−1(μ1′−μ2′)(μ1′−μ2′)Tw
其中 μ ′ \mu' μ′维度p*1, w w w维度p *1,因此 ( μ 1 ′ − μ 2 ′ ) T w (\mu_1'-\mu_2')^Tw (μ1′−μ2′)Tw也是标量,所以:
w ∝ S w − 1 ( μ 1 ′ − μ 2 ′ ) w\varpropto\ S_w^{-1}(\mu_1'-\mu_2') w∝ Sw−1(μ1′−μ2′)
2 软分类
分类结果是(0,1)之间的概率
2.1 概率判别模型
根据 P ( Y ∣ X ) P(Y|X) P(Y∣X)直接建模,例如 y ∈ { 0 , 1 } y\in\{0,1\} y∈{0,1},那么求出 p ( y = 1 ∣ x ) , p ( y = 0 ∣ x ) p(y=1|x),p(y=0|x) p(y=1∣x),p(y=0∣x)比较大小即可。求的结果是判别边界。
2.1.1 逻辑回归
概率判别模型
sigmoid function: σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1

sigmoid将结果映射到(0,1),逻辑回归将结果映射为概率。
p 1 = P ( y = 1 ∣ x ) = 1 1 + e − ( w T x ) p 0 = P ( y = 0 ∣ x ) = 1 − P ( y = 1 ∣ x ) = e − ( w T x ) 1 + e − ( w T x ) p_1=P(y=1|x)=\frac{1}{1+e^{-(w^Tx)}}\\ p_0=P(y=0|x)=1-P(y=1|x)=\frac{e^{-(w^Tx)}}{1+e^{-(w^Tx)}} p1=P(y=1∣x)=1+e−(wTx)1p0=P(y=0∣x)=1−P(y=1∣x)=1+e−(wTx)e−(wTx)
概率判别模型:
P ( y ∣ x ) = p 1 y p 0 1 − y , y ∈ { 0 , 1 } P(y|x)=p_1^yp_0^{1-y},y\in\{0,1\} P(y∣x)=p1yp01−y,y∈{0,1}
概率为:
L ( w ) = ∏ i = 1 N P ( y i ∣ x i ) L(w)=\prod_{i=1}^NP(y_i|x_i) L(w)=i=1∏NP(yi∣xi)
取对数:

上述过程中:
l o g p 1 1 − p 1 = l o g 1 1 + e − ( w T x + b ) e − ( w T x + b ) 1 + e − ( w T x + b ) = l o g 1 e − ( w T x + b ) = w T x + b log\frac{p_1}{1-p_1} = log\frac{\frac{1}{1+e^{-(w^Tx+b)}}}{\frac{e^{-(w^Tx+b)}}{1+e^{-(w^Tx+b)}}} = log\frac{1}{e^{-(w^Tx+b)}}=w^Tx+b log1−p1p1=log1+e−(wTx+b)e−(wTx+b)1+e−(wTx+b)1=loge−(wTx+b)1=wTx+b
可以看到中间过程(第三行)和交叉熵是一样的,只是差一个负号:(交叉熵求的是函数最小值时的w或者说是p)

用MLE求解w
w ^ = a r g m a x w L ( w ) = a r g m a x w ∑ i = 1 N [ y i ( w T x i ) − l o g ( 1 + e w T x i ) ] \begin{aligned} \hat w&=arg\underset{w}{max}L(w)\\ &=arg\underset{w}{max}\sum_{i=1}^{N}[y_i(w^Tx_i)-log(1+e^{w^Tx_i})]\\ \end{aligned} w^=argwmaxL(w)=argwmaxi=1∑N[yi(wTxi)−log(1+ewTxi)]
为了方便求解,一般将上式除样本数n来减少梯度爆炸出现的概率,并乘-1转化为求对小值问题,然后使用梯度下降:(求导略)
J ( w ) = m i n ( − 1 n ∑ i = 1 N [ y i ( w T x i ) − l o g ( 1 + e w T x i ) ] ) J(w) = min(-\frac1n \sum_{i=1}^{N}[y_i(w^Tx_i)-log(1+e^{w^Tx_i})]) J(w)=min(−n1i=1∑N[yi(wTxi)−log(1+ewTxi)])
2.2 概率生成模型
P ( y ∣ x ) p o s t e r i o r = P ( x ∣ y ) P ( y ) P ( x ) ∝ P ( x ∣ y ) l i k e l i h o o d P ( y ) p r i o r = P ( x , y ) \underset{posterior}{P(y|x)}=\frac{P(x|y)P(y)}{P(x)}\varpropto{\underset{likelihood}{P(x|y)}\underset{prior}{P(y)}}=P(x,y) posteriorP(y∣x)=P(x)P(x∣y)P(y)∝likelihoodP(x∣y)priorP(y)=P(x,y)
y ^ = a r g m a x y ∈ ( 0 , 1 ) P ( y ∣ x ) = a r g m a x y P ( x ∣ y ) P ( y ) \hat{y}=arg\underset{y\in(0,1)}{max}P(y|x)=arg\underset{y}{max}P(x|y)P(y) y^=argy∈(0,1)maxP(y∣x)=argymaxP(x∣y)P(y)
对联合概率建模,关注数据的原始分布
2.2.1 Gaussian Discriminant Analysis
假设:(条件概率分布同方差)
y ∼ B e r n o u l l i ( p ) ⇒ y 1 0 P ϕ 1 − ϕ y\sim Bernoulli(p)\Rightarrow \begin{array}{c|lcr} y & 1& 0 \\ \hline P & \phi & 1-\phi \\ \end{array} y∼Bernoulli(p)⇒yP1ϕ01−ϕ
x ∣ y = 1 ∼ N ( μ 1 , Σ ) x|y=1 \sim N(\mu_1,\Sigma) x∣y=1∼N(μ1,Σ)
x ∣ y = 0 ∼ N ( μ 2 , Σ ) x|y=0 \sim N(\mu_2,\Sigma) x∣y=0∼N(μ2,Σ)
C 1 = { x i ∣ y i = 1 , i = 1 , . . . n } C_1=\{x_i|y_i=1,i=1,...n\} C1={xi∣yi=1,i=1,...n}
C 2 = { x i ∣ y i = 0 , i = 1 , . . . n } C_2=\{x_i|y_i=0,i=1,...n\} C2={xi∣yi=0,i=1,...n}
∣ C 1 ∣ = n 1 , ∣ C 2 ∣ = n 2 ,则 n 1 + n 2 = n |C_1|=n_1,|C_2|=n_2,则n_1+n_2=n ∣C1∣=n1,∣C2∣=n2,则n1+n2=n
即满足条件:
P ( Y ) = ϕ y ( 1 − ϕ ) 1 − y , P ( X ∣ Y ) = N ( μ 1 , Σ ) y N ( μ 2 , Σ ) 1 − y P(Y)=\phi^y(1-\phi)^{1-y},P(X|Y)=N(\mu_1,\Sigma)^yN(\mu_2,\Sigma)^{1-y} P(Y)=ϕy(1−ϕ)1−y,P(X∣Y)=N(μ1,Σ)yN(μ2,Σ)1−y
由 P ( y ∣ x ) ∝ P ( x ∣ y ) P ( y ) {P(y|x)}\varpropto{{P(x|y)}{P(y)}} P(y∣x)∝P(x∣y)P(y)
那么log-likelihood:
θ ^ = a r g m a x θ L ( θ ) , 其中 θ = ( ϕ , μ 1 , μ 2 , Σ ) L ( θ ) = l o g ∏ i = 1 n P ( y i ∣ x i ) = ∑ i = 1 n [ l o g P ( x i ∣ y i ) + l o g P ( y i ) ] = ∑ i = 1 n [ l o g N ( μ 1 , Σ ) y i N ( μ 2 , Σ ) 1 − y i + l o g ϕ y i ( 1 − ϕ ) 1 − y i ] = ∑ i = 1 n [ y i l o g N ( μ 1 , Σ ) ‾ ① + ( 1 − y i ) l o g N ( μ 2 , Σ ) ‾ ② + y i l o g ϕ + ( 1 − y i ) l o g ( 1 − ϕ ) ‾ ③ ] \hat{\theta}=arg\underset{\theta}{max}L(\theta),其中\theta=(\phi,\mu_1,\mu_2,\Sigma)\\\\ \begin{aligned} L(\theta) &=log\overset{n}{\underset{i=1}{\prod}}P(y_i|x_i)\\ &=\overset{n}{\underset{i=1}{\sum}}[logP(x_i|y_i)+logP(y_i)]\\ &=\overset{n}{\underset{i=1}{\sum}}[logN(\mu_1,\Sigma)^{y_i}N(\mu_2,\Sigma)^{1-{y_i}}+log\phi^{y_i}(1-\phi)^{1-{y_i}}]\\ &=\overset{n}{\underset{i=1}{\sum}}[\underset{①}{\underline{y_ilogN(\mu_1,\Sigma)}}+\underset{②}{\underline{(1-{y_i})logN(\mu_2,\Sigma)}}+\underset{③}{\underline{y_ilog\phi+(1-{y_i})log(1-\phi)}}] \end{aligned} θ^=argθmaxL(θ),其中θ=(ϕ,μ1,μ2,Σ)L(θ)=logi=1∏nP(yi∣xi)=i=1∑n[logP(xi∣yi)+logP(yi)]=i=1∑n[logN(μ1,Σ)yiN(μ2,Σ)1−yi+logϕyi(1−ϕ)1−yi]=i=1∑n[①yilogN(μ1,Σ)+②(1−yi)logN(μ2,Σ)+③yilogϕ+(1−yi)log(1−ϕ)]
- 求参数 ϕ \phi ϕ
只需考虑③, ϕ ^ = a r g m a x ϕ ③ \hat{\phi}=arg\underset{\phi}{max}③ ϕ^=argϕmax③
∂ L ( θ ) ∂ ϕ = ∑ i = 1 n [ y i ϕ − 1 − y i 1 − ϕ ] = 0 ∑ i = 1 n [ y i ( 1 − ϕ ) − ϕ ( 1 − y i ) ] = 0 ∑ i = 1 n [ y i − y i ϕ − ϕ + y i ϕ ] = 0 ∑ i = 1 n [ y i − ϕ ] = 0 ϕ = 1 n ∑ i = 1 n y i = n 1 n \frac{\partial L(\theta)}{\partial \phi}= \overset{n}{\underset{i=1}{\sum}}[\frac{y_i}{\phi}-\frac{1-y_i}{1-\phi}]=0\\ \begin{aligned} & \overset{n}{\underset{i=1}{\sum}}[y_i(1-\phi)-\phi(1-y_i)]=0\\ & \overset{n}{\underset{i=1}{\sum}}[y_i-y_i\phi-\phi+y_i\phi]=0\\ & \overset{n}{\underset{i=1}{\sum}}[y_i-\phi]=0\\ & \phi=\frac{1}{n}\overset{n}{\underset{i=1}{\sum}}y_i=\frac{n_1}{n} \end{aligned} ∂ϕ∂L(θ)=i=1∑n[ϕyi−1−ϕ1−yi]=0i=1∑n[yi(1−ϕ)−ϕ(1−yi)]=0i=1∑n[yi−yiϕ−ϕ+yiϕ]=0i=1∑n[yi−ϕ]=0ϕ=n1i=1∑nyi=nn1 - 求参数 μ \mu μ
对 μ 1 \mu_1 μ1:
只需考虑①, μ 1 ^ = a r g m a x μ 1 ① \hat{\mu_1}=arg\underset{\mu_1}{max}① μ1^=argμ1max①
多维正态分布:
N ( μ , Σ ) = 1 ( 2 π ) p 2 ∣ Σ ∣ 1 2 e x p { − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) } N(\mu,\Sigma)=\frac{1}{(2\pi)^{\frac{p}{2}}|\Sigma|^{\frac{1}{2}}}exp\{-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)\} N(μ,Σ)=(2π)2p∣Σ∣211exp{−21(x−μ)TΣ−1(x−μ)}
对于①:
① = ∑ i = 1 n y i l o g N ( μ 1 , Σ ) = ∑ i = 1 n [ y i l o g 1 ( 2 π ) p 2 ∣ Σ ∣ 1 2 ‾ e x p { − 1 2 ( x i − μ 1 ) T Σ − 1 ( x i − μ 1 ) } ] ⇓ 系数不影响 令 △ = ∑ i = 1 n [ y i ( − 1 2 ( x i − μ 1 ) T Σ − 1 ( x i − μ 1 ) ] = − 1 2 ∑ i = 1 n [ y i ( x i T Σ − 1 x i − x i T Σ − 1 μ 1 − μ 1 T Σ − 1 x i ‾ 互为转置,乘积为标量可合并 + μ 1 T Σ − 1 μ 1 ) ] = − 1 2 ∑ i = 1 n [ y i ( x i T Σ − 1 x i 常数 − 2 μ 1 T Σ − 1 x i + μ 1 T Σ − 1 μ 1 ) ] \begin{aligned} ① &=\overset{n}{\underset{i=1}{\sum}}y_ilogN(\mu_1,\Sigma)\\ &=\overset{n}{\underset{i=1}{\sum}}[y_ilog \underline{\frac{1}{(2\pi)^{\frac{p}{2}}|\Sigma|^{\frac{1}{2}}}}exp\{-\frac{1}{2}(x_i-\mu_1)^T\Sigma^{-1}(x_i-\mu_1)\}]\\ &\Downarrow \text{系数不影响}\\ 令\triangle&=\overset{n}{\underset{i=1}{\sum}}[y_i(-\frac{1}{2}(x_i-\mu_1)^T\Sigma^{-1}(x_i-\mu_1)]\\ &=-\frac{1}{2}\overset{n}{\underset{i=1}{\sum}}[y_i(x_i^T\Sigma^{-1}x_i-\underset{互为转置,乘积为标量可合并}{\underline{x_i^T\Sigma^{-1}\mu_1-\mu_1^T\Sigma^{-1}x_i}}+\mu_1^T\Sigma^{-1}\mu_1)]\\ &=-\frac{1}{2}\overset{n}{\underset{i=1}{\sum}}[y_i(\underset{常数}{x_i^T\Sigma^{-1}x_i}-2\mu_1^T\Sigma^{-1}x_i+\mu_1^T\Sigma^{-1}\mu_1)] \end{aligned} ①令△=i=1∑nyilogN(μ1,Σ)=i=1∑n[yilog(2π)2p∣Σ∣211exp{−21(xi−μ1)TΣ−1(xi−μ1)}]⇓系数不影响=i=1∑n[yi(−21(xi−μ1)TΣ−1(xi−μ1)]=−21i=1∑n[yi(xiTΣ−1xi−互为转置,乘积为标量可合并xiTΣ−1μ1−μ1TΣ−1xi+μ1TΣ−1μ1)]=−21i=1∑n[yi(常数xiTΣ−1xi−2μ1TΣ−1xi+μ1TΣ−1μ1)]
对 △ 求导 \triangle求导 △求导
∂ △ ∂ μ 1 = − 1 2 ∑ i = 1 n [ y i ( − 2 Σ − 1 x i + 2 Σ − 1 μ 1 ) ] = 0 ∑ i = 1 n [ y i ( Σ − 1 μ 1 − Σ − 1 x i ) ] = 0 ∑ i = 1 n [ y i μ 1 − y i x i ] = 0 μ 1 = ∑ i = 1 n y i x i ∑ i = 1 n y i = ∑ i = 1 n y i x i n 1 \begin{aligned} \frac{\partial \triangle}{\partial \mu_1} &=-\frac{1}{2}\overset{n}{\underset{i=1}{\sum}}[y_i(-2\Sigma^{-1}x_i+2\Sigma^{-1}\mu_1)]=0\\ &\overset{n}{\underset{i=1}{\sum}}[y_i(\Sigma^{-1}\mu_1-\Sigma^{-1}x_i)]=0\\ &\overset{n}{\underset{i=1}{\sum}}[y_i\mu_1-y_ix_i]=0\\ & \mu_1=\frac{\overset{n}{\underset{i=1}{\sum}}y_ix_i}{\overset{n}{\underset{i=1}{\sum}}y_i}=\frac{\overset{n}{\underset{i=1}{\sum}}y_ix_i}{n_1} \end{aligned} ∂μ1∂△=−21i=1∑n[yi(−2Σ−1xi+2Σ−1μ1)]=0i=1∑n[yi(Σ−1μ1−Σ−1xi)]=0i=1∑n[yiμ1−yixi]=0μ1=i=1∑nyii=1∑nyixi=n1i=1∑nyixi
同理可得
μ 2 = ∑ i = 1 n ( 1 − y i ) x i n 2 \mu_2=\frac{\overset{n}{\underset{i=1}{\sum}}(1-y_i)x_i}{n_2} μ2=n2i=1∑n(1−yi)xi - 求参数 Σ \Sigma Σ
需同时考虑①②,即 Σ ^ = a r g m a x μ 1 ① + ② \hat{\Sigma}=arg\underset{\mu_1}{max}①+② Σ^=argμ1max①+②
为把 y i y_i yi去掉,分别考虑 C 1 , C 2 C_1,C_2 C1,C2对应集合的情况即可
① + ② = ∑ x i ∈ C 1 l o g N ( μ 1 , Σ ) + ∑ x i ∈ C 2 l o g N ( μ 2 , Σ ) ①+②=\underset{x_i\in C_1}{\sum}logN(\mu_1,\Sigma)+\underset{x_i\in C_2}{\sum}logN(\mu_2,\Sigma) ①+②=xi∈C1∑logN(μ1,Σ)+xi∈C2∑logN(μ2,Σ)
∑ i = 1 n l o g N ( μ , Σ ) = ∑ i = 1 n l o g 1 ( 2 π ) p 2 ∣ Σ ∣ 1 2 e x p { − 1 2 ( x i − μ ) T Σ − 1 ( x i − μ ) } = − p 2 ∑ i = 1 n l o g 2 π ‾ 常数 − 1 2 ∑ i = 1 n l o g ∣ Σ ∣ − 1 2 ∑ i = 1 n ( x i − μ ) T Σ − 1 ( x i − μ ) = C − 1 2 n l o g ∣ Σ ∣ − 1 2 ∑ i = 1 n ( x i − μ ) T Σ − 1 ( x i − μ ) \begin{aligned} \overset{n}{\underset{i=1}{\sum}}logN(\mu,\Sigma) &=\overset{n}{\underset{i=1}{\sum}}log\frac{1}{(2\pi)^{\frac{p}{2}}|\Sigma|^{\frac{1}{2}}}exp\{-\frac{1}{2}(x_i-\mu)^T\Sigma^{-1}(x_i-\mu)\}\\ &=\underset{常数}{\underline{-\frac{p}{2}\overset{n}{\underset{i=1}{\sum}}log2\pi}}-\frac{1}{2}\overset{n}{\underset{i=1}{\sum}}log|\Sigma|-\frac{1}{2}\overset{n}{\underset{i=1}{\sum}}(x_i-\mu)^T\Sigma^{-1}(x_i-\mu)\\ &=C-\frac{1}{2}nlog|\Sigma|-\frac{1}{2}\overset{n}{\underset{i=1}{\sum}}(x_i-\mu)^T\Sigma^{-1}(x_i-\mu)\\ \end{aligned} i=1∑nlogN(μ,Σ)=i=1∑nlog(2π)2p∣Σ∣211exp{−21(xi−μ)TΣ−1(xi−μ)}=常数−2pi=1∑nlog2π−21i=1∑nlog∣Σ∣−21i=1∑n(xi−μ)TΣ−1(xi−μ)=C−21nlog∣Σ∣−21i=1∑n(xi−μ)TΣ−1(xi−μ)
其中 ( x i − μ ) T Σ − 1 ( x i − μ ) (x_i-\mu)^T\Sigma^{-1}(x_i-\mu) (xi−μ)TΣ−1(xi−μ)结果是标量,且有以下公式:
t r ( a ) = a , a 是标量 ∂ t r ( A B ) ∂ A = B T ∂ ∣ A ∣ ∂ A = ∣ A ∣ A − 1 t r ( A B ) = t r ( B A ) ⇒ t r ( A B C ) = t r ( C A B ) = t r ( B C A ) \begin{align} &tr(a)=a,a是标量\\ &\frac{\partial tr(AB)}{\partial A}=B^T\\ &\frac{\partial|A|}{\partial A}=|A|A^{-1}\\ tr(AB)=tr(BA)&\Rightarrow tr(ABC)=tr(CAB)=tr(BCA) \end{align} tr(AB)=tr(BA)tr(a)=a,a是标量∂A∂tr(AB)=BT∂A∂∣A∣=∣A∣A−1⇒tr(ABC)=tr(CAB)=tr(BCA)
因此:
∑ i = 1 n ( x i − μ ) T Σ − 1 ( x i − μ ) = ∑ i = 1 n t r ( ( x i − μ ) T Σ − 1 ( x i − μ ) ) 根据(1) = ∑ i = 1 n t r ( ( x i − μ ) T ( x i − μ ) Σ − 1 ) 根据(4) = t r ( ∑ i = 1 n ( x i − μ ) T ( x i − μ ) ‾ 样本方差 S = 1 n ∑ i = 1 n ( x i − μ ) T ( x i − μ ) Σ − 1 ) = t r ( n S Σ − 1 ) = n t r ( S Σ − 1 ) \begin{aligned} &\quad\overset{n}{\underset{i=1}{\sum}}(x_i-\mu)^T\Sigma^{-1}(x_i-\mu)\\ &=\overset{n}{\underset{i=1}{\sum}}tr((x_i-\mu)^T\Sigma^{-1}(x_i-\mu))\qquad\text{根据(1)}\\ &=\overset{n}{\underset{i=1}{\sum}}tr((x_i-\mu)^T(x_i-\mu)\Sigma^{-1})\qquad\text{根据(4)}\\ &=tr(\underset{样本方差S=\frac{1}{n}\overset{n}{\underset{i=1}{\sum}}(x_i-\mu)^T(x_i-\mu)}{\underline{\overset{n}{\underset{i=1}{\sum}}(x_i-\mu)^T(x_i-\mu)}}\Sigma^{-1})\\ &=tr(nS\Sigma^{-1}) &=n\ tr(S\Sigma^{-1}) \end{aligned} i=1∑n(xi−μ)TΣ−1(xi−μ)=i=1∑ntr((xi−μ)TΣ−1(xi−μ))根据(1)=i=1∑ntr((xi−μ)T(xi−μ)Σ−1)根据(4)=tr(样本方差S=n1i=1∑n(xi−μ)T(xi−μ)i=1∑n(xi−μ)T(xi−μ)Σ−1)=tr(nSΣ−1)=n tr(SΣ−1)
原式:
∑ i = 1 n l o g N ( μ , Σ ) = − 1 2 n l o g ∣ Σ ∣ − 1 2 n t r ( S Σ − 1 ) + C \overset{n}{\underset{i=1}{\sum}}logN(\mu,\Sigma)=-\frac{1}{2}nlog|\Sigma|-\frac{1}{2}n\ tr(S\Sigma^{-1})+C i=1∑nlogN(μ,Σ)=−21nlog∣Σ∣−21n tr(SΣ−1)+C
① + ② = − 1 2 n 1 l o g ∣ Σ ∣ − 1 2 n 1 t r ( S 1 Σ − 1 ) − 1 2 n 2 l o g ∣ Σ ∣ − 1 2 n 2 t r ( S 2 Σ − 1 ) + C = − 1 2 ( n l o g ∣ Σ ∣ ‾ ( 3 ) + n 1 t r ( S 1 Σ − 1 ) + n 2 t r ( S 2 Σ − 1 ) ‾ ( 2 ) , S 对称, S T = S ) + C \begin{aligned} ①+②&=-\frac{1}{2}n_1log|\Sigma|-\frac{1}{2}n_1\ tr(S_1\Sigma^{-1})-\frac{1}{2}n_2log|\Sigma|-\frac{1}{2}n_2\ tr(S_2\Sigma^{-1})+C\\ &=-\frac{1}{2}(\underset{(3)}{\underline{nlog|\Sigma|}}+\underset{(2),S对称,S^T=S}{\underline{n_1\ tr(S_1\Sigma^{-1})+n_2\ tr(S_2\Sigma^{-1})}})+C \end{aligned} ①+②=−21n1log∣Σ∣−21n1 tr(S1Σ−1)−21n2log∣Σ∣−21n2 tr(S2Σ−1)+C=−21((3)nlog∣Σ∣+(2),S对称,ST=Sn1 tr(S1Σ−1)+n2 tr(S2Σ−1))+C
求导:
∂ ① + ② ∂ Σ = − 1 2 ( n 1 ∣ Σ ∣ ∣ Σ ∣ Σ − 1 − n 1 S 1 T Σ − 2 − n 2 S 2 T Σ − 2 ) = − 1 2 ( n Σ − 1 − n 1 S 1 Σ − 2 − n 2 S 2 Σ − 2 ) = 0 n Σ − n 1 S 1 − n 2 S 2 = 0 Σ ^ = 1 n ( n 1 S 1 + n 2 S 2 ) \begin{aligned} \frac{\partial ①+②}{\partial \Sigma} &=-\frac{1}{2}(n\frac{1}{|\Sigma|}|\Sigma|{\Sigma^{-1}}-n_1S_1^T\Sigma^{-2}-n_2S_2^T\Sigma^{-2})\\ &=-\frac{1}{2}(n{\Sigma^{-1}}-n_1S_1\Sigma^{-2}-n_2S_2\Sigma^{-2})=0\\ &n\Sigma-n_1S_1-n_2S_2=0\\ &\hat{\Sigma}=\frac{1}{n}(n_1S_1+n_2S_2) \end{aligned} ∂Σ∂①+②=−21(n∣Σ∣1∣Σ∣Σ−1−n1S1TΣ−2−n2S2TΣ−2)=−21(nΣ−1−n1S1Σ−2−n2S2Σ−2)=0nΣ−n1S1−n2S2=0Σ^=n1(n1S1+n2S2)
2.2.2 Naive Bayes
思想:
条件独立性假设(每个属性之间相互独立)
目的是简化运算
y ^ = a r g m a x y P ( y ∣ x ) = a r g m a x y P ( x ∣ y ) P ( y ) P ( x ∣ y ) = ∏ j = 1 p P ( x j ∣ y ) , 这里 x j 是属性 \hat{y}=arg\underset{y}{max}P(y|x)=arg\underset{y}{max}P(x|y)P(y)\\ P(x|y)=\overset{p}{\underset{j=1}{\prod}}P(x_j|y), 这里x_j是属性 y^=argymaxP(y∣x)=argymaxP(x∣y)P(y)P(x∣y)=j=1∏pP(xj∣y),这里xj是属性