GAN简介及其常见应用
转自:https://www.toutiao.com/a6665986672145990156/
很长一段时间,只有人类有能力创造,人工智能唯一的好处是解决回归,分类和聚类等问题,但随着生成网络的引入,人工智能研究人员能够使机器生成相同的内容或与人类同行相比质量更高。
什么是GANs?
生成性对抗网络(GANs)是蒙特利尔大学(University of Montreal)的伊恩•古德费洛(Ian Goodfellow)和其他研究人员(包括约舒亚•本吉奥)在2014年6月提出的一种新型神经结构。GANs被称为十年来最有趣的想法。
GANs基于对抗性训练的理念。它们基本上由两个相互竞争的神经网络组成。这种竞争力有助于他们模仿任何数据分布。他们模仿数据的能力使他们就像一个机器人艺术家,因为一旦成功训练,GANs就能够创作艺术品,歌曲,图像,甚至视频。
GANs有什么特别之处?
为了理解GANs为何与众不同,让我们理解生成和判别算法的概念。
判别算法的主要目的是对输入数据进行分类,即如果我们给它们一组特定的特征,我们将试图找出这些特征所属的标签或类别,即判别算法帮助我们将特征映射到标签。
另一方面,生成算法的工作方式与判别算法完全不同,因为它试图创建输入数据,即我们为它提供了一组不会对其进行分类的特征,而是尝试创建一个适合某个标签。
因此,GANs是生成模型的一个特例,它能够以更好的方式预测特征,因为对抗性训练解释了为什么它们在AI社区中被大肆宣传。
GANs如何工作?
GAN由两个神经网络组成,一个称为生成器,另一个称为判别器。生成器或生成模型尝试捕获数据分布,判别器或判别模型估计样本来自训练数据而不是G的概率。即,生成器试图创建与训练集和判别器尝试相同的样本区分生成器正在创建的内容和训练集中的原始样本。在训练期间,生成器试图更好地愚弄判别器并且判别器试图捕获由生成器生成的假货,因此训练过程被称为对抗训练。
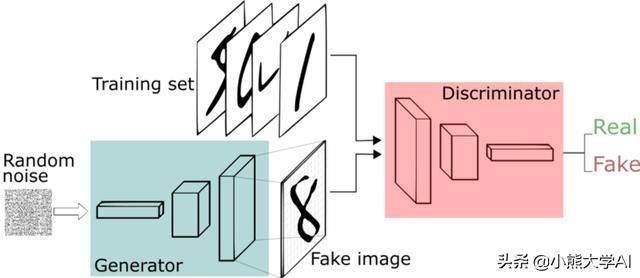
让我们举一个使用GAN生成手写数字的例子,最初,随机噪声将提供给生成器,生成器将尝试生成一个数字,然后判别器将决定它接收到的输入是否是假的。在该过程开始时,由生成器生成的样本并不会很好并且很容易被判别器轻易地丢弃,随着训练的继续生成器将越来越好地生成数字,同时判别器也将变得更好。在训练过程中,我们将开始生成假的字符,这些字符将类似于人类写的字符。
训练GAN时要记住的要点
生成器和判别器应针对静态对手进行训练,这意味着在训练生成器时,保持判别器不变并在训练判别器时保持生成器不变。这有助于更好地理解梯度。
GAN的每个网络都可以压倒另一个网络。如果生成器太好,它将持续利用判别器中的弱点导致漏报。如果判别器太好了,它将返回非常接近0或1的值,使得生成器难以读取梯度。
GANs可以应用于哪里?
GANs有能力解决医疗保健,汽车美术等众多行业的问题。在本节中,我们将了解对抗网络的一些用例以及用于该应用程序的GAN架构。
单幅图像超分辨率
我们经常面临低分辨率图像的问题,因为它们不清楚,GANs帮助我们从单个低分辨率图像创建高分辨率图像。
对于这个问题,使用了一个名为SRGAN的GAN ,我们可以看到SRGAN如何能够在下图中创建最高分辨率的图像

尽管存在许多方法,但是当图像超分辨率时恢复更精细的纹理细节的问题仍然存在。 SRGAN是第一个能够为4倍放大因子推断照片真实感自然图像的框架。它使用感知损失函数,其包括对抗性损失和内容损失。对抗性损失使用经过训练以区分超分辨图像和原始照片真实图像的判别器网络将解决方案推送到自然图像集。
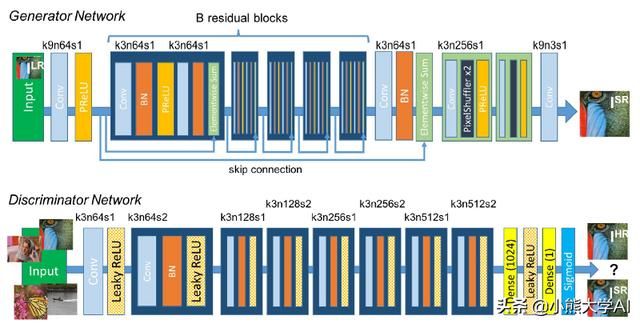
生成器和判别器的结构
以上显示了生成器和判别器的结构。其中k表示内核大小,n表示特征映射的数量, s表示卷积层的步幅。在SRGAN中,训练生成器以产生高分辨率图像,并且训练判别器以区分原始图像和高分辨率图像。
对象检测
在CVPR 2017中,提出了两种利用GANs进行对象检测的技术。
感知GAN
PGANs是专门用于检测小对象,就像以前的对象检测策略一样,检测小对象因其分辨率低和噪声表示而众所周知地具有挑战性。PGANs将小对象的表示形式更改为“超解析”
实现与大对象类似的特征,因此对检测更具判别力。它的生成器学会将感知到的小对象的不良表示转移到超分辨率对象中,这些超分辨对象与真正的大对象非常相似,足以欺骗竞争的判别器。同时,其判别器与生成器竞争以识别所生成的表示并强加一个额外的感知需求生成的表示。
对小目标的检测必须有利于对生成器的目的。
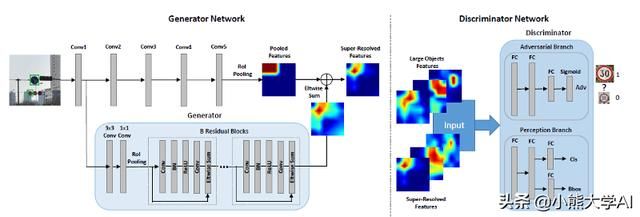
通过对手生成强烈积极的一面
该技术试图使对象检测器对遮挡和变形不变。该技术创建具有遮挡和变形的图像。我们训练了一个GAN,它能生成对象检测器难以分类的示例。在此技术之前,我们依赖于数据集,希望它可能具有被遮挡的图像,如果遮挡的示例较少则会训练探测器,这意味着探测器将无法进行正确的分类。

文本到图像合成
从文本描述中合成高质量的图像是计算机视觉中的挑战性问题。由现有的文本到图像方法生成的样本可以粗略地反映给定描述的含义,但是它们不能包含必要的细节和生动的对象部分。这个应用程序的最佳网络是StackGAN或堆叠生成对抗网络,它根据文本描述生成256x256的逼真照片般的图像。

StackGAN在多个阶段工作:
在阶段1中,GAN根据给定的文本描述绘制对象的原始形状和颜色,从而产生低分辨率图像
在阶段2中,GAN将阶段1和文本描述的结果作为输入,并生成具有真实感细节的高分辨率图像。它能够纠正阶段1结果中的缺陷,并通过细化过程添加引人注目的细节。
医疗应用
GANs在医学领域非常有用,因为它经过对抗性训练,可以用于图像分析、异常检测甚至新药的发现。他们以前所未有的现实水平合成图像的能力也使人们希望在这些生成模型的帮助下可以解决医学领域中标记数据的长期稀缺性。我们来看看在这种情况下如何使用GANs。
用于异常检测的AnoGAN
创建模型以检测与疾病进展和治疗监测相关的异常是具有挑战性的。模型通常基于大量带注释的数据,用于自动检测。高注释工作量和对已知标记的词汇的限制限制了这些方法的能力。因此,使用监督学习检测异常是可行的,但不能提供有用的结果。
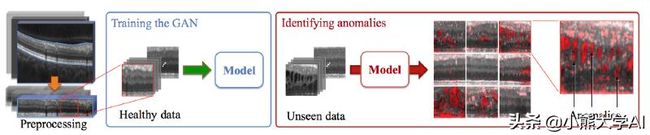
为了应对上述挑战,我们采用了一种无监督的方法,使用GANs,专门设计的AnoGAN来检测医学领域的异常。AnoGAN是一种深度卷积生成对抗网络,用于学习多种正常的解剖变异性,伴随着基于从图像空间到潜在空间的映射的新型异常评分方案。应用于新数据,模型标记异常,并对图像块进行评分,表明它们适合学习的分布。
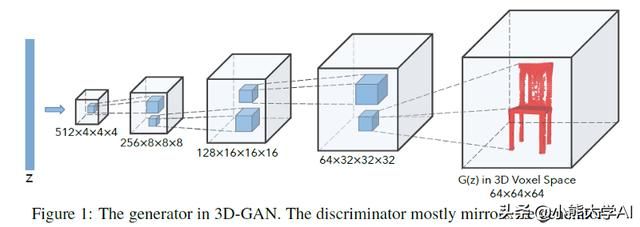
生成3D对象
3D对象生成可以找到各种应用,例如用于增强3D对象识别的数据集,也可以用于3D面部重建,其可以用于使面部识别系统越来越强大。3D生成对抗网络或3D-GAN用于使用体积卷积网络和生成对抗网络从概率空间生成3D对象。
使用3D-GAN的好处:
使用对抗性标准而不是传统的启发式标准,使得生成器能够隐式捕获对象结构并合成高质量的3D对象
该生成器建立从低维概率空间到3D对象空间的映射,以便我们可以在没有参考图像或CAD模型的情况下对对象进行采样,并探索3D对象多样性。
对抗性判别器提供了强大的3D形状描述符,在没有监督的情况下学习,在3D对象识别中具有广泛的应用。
高分辨率图像合成
高分辨率图像合成是图像分割的逆过程。在这里,我们使用语义映射来生成高分辨率图像。这对于生成用于训练自动驾驶车辆的视频非常有用,而不是自己制作视频。用于这种类型的图像合成。

Pix2pix是一种条件GAN。对于该任务,生成器G的目标是将语义标签映射转换为具有真实感的图像,而判别器D旨在将真实图像与翻译的图像区分开。pix2pix方法采用U-Net作为生成器。
以及patch-based的完全卷积网络作为判别器。判别器的输入是语义标签映射和对应图像的通道顺序连接。我们可以通过使用粗到精生成器,multi-scale判别器架构和强大的对抗性学习目标函数来提高真实感和分辨率。
视频生成
视频生成是图像生成的延伸,这是一个巨大的挑战,因为我们必须在生成过程中考虑视频的时间维度,因为理解对象运动和场景动态是视频生成核心问题,这对视频生成提出了很大的挑战。由于记忆和训练稳定性的限制,随着视频分辨率/时长的增加,生成变得越来越具有挑战性。视频生成过程可以通过两种方式进行,一种是提供文本作为创建相应视频的特性,另一种是提供视频并生成视频的下一帧。为了实现生成器具有时空卷积结构的生成对抗网络,它将场景的前景从背景中分离出来。

我们为网络提供了一个100维高斯噪声输入,它有两个独立的数据流,一个用于分阶时空卷积的运动前景路径,另一个用于分阶空间卷积的静态背景路径,两者都对输入数据进行上采样。将这两个路径组合以使用来自运动路径的掩模来创建所生成的视频。
与GANs的竞争
GANs不是唯一属于生成模型类的模型,其他深度学习模型(如变分自编码器和自回归模型)也是生成模型的好示例,用于模拟数据的分布。
这些生成算法具有不同的基本工作,对于GANs而言,训练过程就像生成器和判别器之间的竞争,而变分自编码器允许我们在概率图形模型的框架中形成生成训练样本的问题,我们最大化了数据的对数可能性的最低范围。在PixelRNN的自回归模型的情况下,对网络进行训练以模拟每个单独像素的条件分布到前一像素的条件分布进行建模。