Pytorch模型量化实践并以ResNet18模型量化为例(附代码)
更多、更及时内容欢迎微信公众号:小窗幽记机器学习 围观,后续会进一步整理模型推理加速和部署方面的相关内容。
文章目录
- 量化基础知识
-
- 映射函数
- 量化参数
- 校准(Calibration)
- Affine和Symmetric Quantization Schemes
- Per-Tensor Per-Channel Quantization Schemes
- 后端引擎(Backend Engine)
- QConfig
- Pytorch中的量化
-
- **动态量化**(Post-Training Dynamic/Weight-only Quantization)
- **静态量化**(Post-Training Static Quantization (PTQ))
- **感知量化**[Quantization-aware Training (QAT)]
- 灵敏性分析
- 以resnet18为例
- 使用建议
更多、更及时内容欢迎微信公众号:小窗幽记机器学习 围观,后续会进一步整理模型推理加速和部署方面的相关内容。
量化基础知识
量化的本质是信息压缩,在深度学习中一般是降低参数精度。DNN中的参数过载使得其有更多的自由度或者说更多的选择来进行信息压缩。量化后的模型更小、运行效率更高,进而能够支持更高的吞吐量。较小的模型内存占用和能耗较低,是边缘部署的关键。
映射函数
所谓的映射函数是将 float类型转为integer的映射操作,
常用的映射函数是线性变换 Q ( r ) = round ( r / S + Z ) Q(r)=\operatorname{round}(r / S+Z) Q(r)=round(r/S+Z), 其中 r {r} r为输入, S , Z S, Z S,Z是量化参数。逆变换: r ~ = ( Q ( r ) − Z ) ⋅ S \tilde{r}=(Q(r)-Z) \cdot S r~=(Q(r)−Z)⋅S, r ~ ≠ r \tilde{r} \ne r r~=r,其中的偏差表示量化误差。
量化参数
映射函数主要由缩放系数(scaling factor) S S S和zero-point Z Z Z组成。
S S S是输入范围和输出范围的比值:
S = β − α β q − α q S=\frac{\beta-\alpha}{\beta_{q}-\alpha_{q}} S=βq−αqβ−α
其中 [ α , β ] [\alpha, \beta] [α,β]是裁剪的输入范围,即允许的输入范围。 [ α q , β q ] [\alpha_{q},\beta_{q}] [αq,βq]是量化后的输出范围。比如,8-bit的量化,其输出范围 β q − α q < = ( 2 8 − 1 ) \beta_{q}-\alpha_{q} <=( 2^8-1) βq−αq<=(28−1)。
Z Z Z是一个偏置项,以确保输入空间中的0在映射后的量化空间中也是0:
Z = − ( α S − α q ) Z=-\left(\frac{\alpha}{S}-\alpha_{q}\right) Z=−(Sα−αq)
校准(Calibration)
选择输入裁剪范围的过程被称为校准。最简单的方法(也是Pytorch中默认选项)是直接将 α \alpha α和 β \beta β取最小值和最大值。TensorRT还支持使用熵最小化(KL散度)、均方误差最小化,或者输入范围的百分位数。
在Pytorch中的torch.quantization.observer模块集成了各种校准策略,可以根据实际需要选择最合适的策略。
import torch
from torch.quantization.observer import MinMaxObserver, MovingAverageMinMaxObserver, HistogramObserver
C, L = 3, 4
normal = torch.distributions.normal.Normal(0,1)
inputs = [normal.sample((C, L)), normal.sample((C, L))]
print(inputs)
observers = [MinMaxObserver(), MovingAverageMinMaxObserver(), HistogramObserver()]
for obs in observers:
for x in inputs: obs(x)
print(obs.__class__.__name__, obs.calculate_qparams())
输出如下:
[tensor([[-2.0369, -1.4840, 0.6457, -1.1184],
[-0.0678, 1.7360, 0.1488, -1.3551],
[-0.7111, -0.3592, 0.8379, 0.6078]]), tensor([[ 1.1579, 0.2877, 2.6896, -0.7351],
[ 0.2124, 0.2675, 0.0679, 0.5265],
[-1.0505, -0.3171, -1.1585, 2.4082]])]
MinMaxObserver (tensor([0.0185]), tensor([110], dtype=torch.int32))
MovingAverageMinMaxObserver (tensor([0.0148]), tensor([137], dtype=torch.int32))
HistogramObserver (tensor([0.0121]), tensor([114], dtype=torch.int32))
Affine和Symmetric Quantization Schemes
仿射量化(也称为不对称量化)策略将输入范围。仿射策略是更严格的范围剪裁,这种策略对量化非负激活(如果输入张量非负那么不需要输入的范围包含负值)是有用的。此时 α = m i n ( r ) \alpha=min(r) α=min(r)和 β = m a x ( r ) \beta=max(r) β=max(r)。仿射量化策略当用于weight张量的时候会带来更多的推理计算。
对称量化策略的中心输入为0,从而避免计算零点偏移量。 − α = β = m a x ( ∣ m a x ( r ) ∣ , ∣ m i n ( r ) ∣ ) -\alpha=\beta=max(|max(r)|,|min(r)|) −α=β=max(∣max(r)∣,∣min(r)∣)。此时非负激活的量化效果可能较差,因为剪裁范围包括从未出现在输入中的值。
import torch
import numpy as np
import matplotlib.pyplot as plt
act = torch.distributions.pareto.Pareto(1, 10).sample((1,1024))
weights = torch.distributions.normal.Normal(0, 0.12).sample((3, 64, 7, 7)).flatten()
def get_symmetric_range(x):
beta = torch.max(x.max(), x.min().abs())
return -beta.item(), beta.item()
def get_affine_range(x):
return x.min().item(), x.max().item()
def plot(plt, data, scheme):
boundaries = get_affine_range(data) if scheme == 'affine' else get_symmetric_range(data)
a, _, _ = plt.hist(data, density=True, bins=100)
ymin, ymax = np.quantile(a[a>0], [0.25, 0.95])
plt.vlines(x=boundaries, ls='--', colors='purple', ymin=ymin, ymax=ymax)
plt.figure(dpi=200)
fig, axs = plt.subplots(2,2)
plot(axs[0, 0], act, 'affine')
axs[0, 0].set_title("Activation, Affine-Quantized")
plot(axs[0, 1], act, 'symmetric')
axs[0, 1].set_title("Activation, Symmetric-Quantized")
plot(axs[1, 0], weights, 'affine')
axs[1, 0].set_title("Weights, Affine-Quantized")
plot(axs[1, 1], weights, 'symmetric')
axs[1, 1].set_title("Weights, Symmetric-Quantized")
plt.show()

PS:需要特别注意Pytorch版本!!! 本文实验使用的Pytorch版本==1.12.0+cpu
在Pytorch中可以在初始化Observer的时候指定仿射或对称策略。需要注意的是,并不是所有Observer类型都支持这两种策略。
import torch
from torch.quantization.observer import MinMaxObserver, MovingAverageMinMaxObserver, HistogramObserver
C, L = 3, 4
normal = torch.distributions.normal.Normal(0,1)
inputs = [normal.sample((C, L)), normal.sample((C, L))]
for qscheme in [torch.per_tensor_affine, torch.per_tensor_symmetric]:
obs = MovingAverageMinMaxObserver(qscheme=qscheme)
for x in inputs: obs(x)
print(f"Qscheme: {qscheme} | {obs.calculate_qparams()}")
运行结果如下:
Qscheme: torch.per_tensor_affine | (tensor([0.0117]), tensor([117], dtype=torch.int32))
Qscheme: torch.per_tensor_symmetric | (tensor([0.0126]), tensor([128]))
Per-Tensor Per-Channel Quantization Schemes
量化参数即可以基于整个网络层全部权重张量(即Per-Tensor),也可以基于每个通道单独计算。在整个网络层权重张量中,相同的剪切范围应用于一层中的所有通道,而Per-Channel的量化方式则每个通道单独计算量化参数。
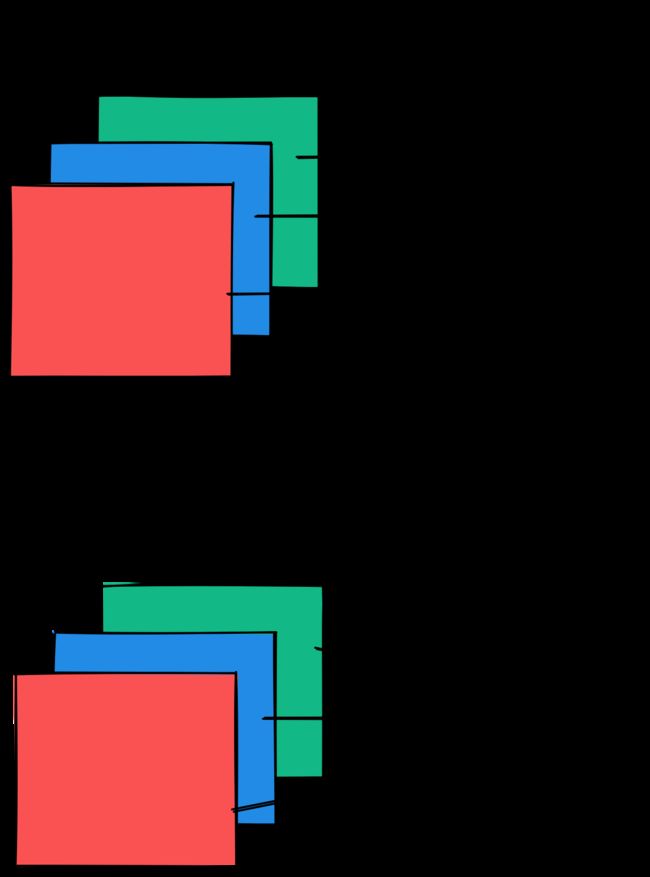
对于权重量化,symmetric-per-channel量化提供更好的精度;per-tensor量化表现欠佳,可能是因为batch-norm折叠跨通道的卷积权值的方差较高。
import torch
from torch.quantization.observer import MinMaxObserver, MovingAverageMinMaxObserver, HistogramObserver
from torch.quantization.observer import MovingAveragePerChannelMinMaxObserver
C, L = 3, 4
normal = torch.distributions.normal.Normal(0,1)
inputs = [normal.sample((C, L)), normal.sample((C, L))]
obs = MovingAveragePerChannelMinMaxObserver(ch_axis=0) # calculate qparams for all `C` channels separately
for x in inputs: obs(x)
print(obs.calculate_qparams())
运行结果:
(tensor([0.0072, 0.0039, 0.0068]), tensor([ 83, 176, 83], dtype=torch.int32))
后端引擎(Backend Engine)
目前,量化操作符在x86机器上通过FBGEMM后端运行,在ARM机器上使用QNNPACK原语。现有的后端引擎尚未(2022年7月21日)支持gpu(通过TensorRT和cuDNN),但是官方表示也快了(coming soon)。更多有关将量化扩展到自定义后端引擎可以参考:RFC-0019。
使用示例如下:
backend = 'fbgemm' if x86 else 'qnnpack'
qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
QConfig
QConfig存储Observer和用于量化激活和权重的量化方案。
确保传递的是Observer类(而不是实例),或者可以返回Observer实例的可调用对象。使用with_args()覆盖默认参数。使用示例如下:
from torch.quantization.observer import MinMaxObserver, MovingAverageMinMaxObserver
from torch.quantization.observer import MovingAveragePerChannelMinMaxObserver
my_qconfig = torch.quantization.QConfig(
activation=MovingAverageMinMaxObserver.with_args(qscheme=torch.per_tensor_affine),
weight=MovingAveragePerChannelMinMaxObserver.with_args(qscheme=torch.qint8)
)
Pytorch中的量化
Pytorch的量化,从不同角度可以有不同的分法。
- 如果从量化的灵活程度或者自动化程度,可以分为2种:Eager Mode 和 FX Graph Mode。
- 如果从输入的量化激活(layer outputs)所对应的量化参数是否预先计算或者对每个输入重新计算,那么可以分为2种:静态量化或者动态量化。
- 如果从是否需要再训练量化参数的角度,那么可以分为2种:quantization-aware training(感知训练) 和 post-training quantization(训练后量化)。
早在 pytorch1.3 发布的时候,官方就推出了量化功能,但当时官方重点是在后端的量化推理引擎(FBGEMM 和 QNNPACK)上,对于 pytorch 前端的接口设计很粗糙。官方把这个第一代的量化方式称为 Eager Mode Quantization。Pytorch1.8 发布后,官方推出一个 torch.fx 的工具包,可以动态地对 forward 流程进行跟踪,并构建出模型的图结构。而随着 fx 的推出,由于可以动态地 trace 出网络的图结构,因此就可以针对网络模型动态地添加一些量化节点。官方称这种新的量化方式为 FX Graph Mode Quantization。FX Graph模式将符合条件的模块进行自动融合、插入Quant/DeQuant stubs、校准模型并返回一个量化模块。所有这些方法都只适用于符号可跟踪(symbolic traceable)的网络。后面的示例包含使用Eager Mode和FX Graph Mode进行比较的调用。
在DNNs中,能够进行量化的是FP32权重(layer参数)和激活(layer输出)。量化权重可以减小模型尺寸,量化的激活通常会加快推理速度。例如,50层的ResNet网络有~ 2600万个权重参数,在前向传递中计算~ 1600万个激活。
动态量化(Post-Training Dynamic/Weight-only Quantization)
动态量化(PDQ)模型的权重是预先量化的。在推理过程中,激活被实时量化(“动态”)。这是所有方法中最简单的一种,它在torch. quantized.quantize_dynamic中只有一行API调用。但是目前只支持线性层和递归(LSTM, GRU, RNN)层的动态量化。
优点:
- 可产生更高的精度,因为每个输入的裁剪范围被精确校准
- 对于LSTMs和transformers这样的模型,动态量化是首选。在这些模型中,从内存中写入或检索模型的权重占主导带宽
缺点:
- 在运行时对每一层的激活进行校准和量化会增加计算开销。
具体代码示例如下:
import torch
from torch import nn
# toy model
m = nn.Sequential(
nn.Conv2d(2, 64, (8,)),
nn.ReLU(),
nn.Linear(16,10),
nn.LSTM(10, 10))
m.eval()
## EAGER MODE
from torch.quantization import quantize_dynamic
model_quantized = quantize_dynamic(
model=m, qconfig_spec={nn.LSTM, nn.Linear}, dtype=torch.qint8, inplace=False
)
## FX MODE
from torch.quantization import quantize_fx
qconfig_dict = {"": torch.quantization.default_dynamic_qconfig} # An empty key denotes the default applied to all modules
model_prepared = quantize_fx.prepare_fx(m, qconfig_dict)
model_quantized = quantize_fx.convert_fx(model_prepared)
静态量化(Post-Training Static Quantization (PTQ))
静态量化PTQ也是预先量化模型权重,但不是实时校准激活,而是使用验证数据预校准和固定(“静态”)的裁剪范围。大约100个min-batches的代表性数据足以校准observers。为了方便起见,下面的例子在校准时使用了随机数据,所以仅仅为了示例而已。

模块融合将多个顺序模块(如:[Conv2d, BatchNorm, ReLU])合并为一个模块。 融合模块意味着编译器只需要运行一个内核,而无需多个。这可以通过减少量化误差来加快速度和提高准确性。
优点:
- 静态量化比动态量化具有更快的推理速度,因为它消除了层之间的float<->int转换开销。
缺点:
- 静态量化模型可能需要定期重新校准,以保持对分布漂移的鲁棒性。
静态量化示例代码如下,包括EAGER模式和FX模式:
EAGER模式下的静态量化:
# Static quantization of a model consists of the following steps:
# Fuse modules
# Insert Quant/DeQuant Stubs
# Prepare the fused module (insert observers before and after layers)
# Calibrate the prepared module (pass it representative data)
# Convert the calibrated module (replace with quantized version)
import torch
from torch import nn
backend = "fbgemm" # running on a x86 CPU. Use "qnnpack" if running on ARM.
m = nn.Sequential(
nn.Conv2d(2, 64, 3),
nn.ReLU(),
nn.Conv2d(64, 128, 3),
nn.ReLU()
)
## EAGER MODE
"""Fuse
- Inplace fusion replaces the first module in the sequence with the fused module, and the rest with identity modules
"""
torch.quantization.fuse_modules(m, ['0', '1'], inplace=True) # fuse first Conv-ReLU pair
torch.quantization.fuse_modules(m, ['2', '3'], inplace=True) # fuse second Conv-ReLU pair
"""Insert stubs"""
m = nn.Sequential(torch.quantization.QuantStub(),
*m,
torch.quantization.DeQuantStub())
"""Prepare"""
m.qconfig = torch.quantization.get_default_qconfig(backend)
torch.quantization.prepare(m, inplace=True)
"""Calibrate
- This example uses random data for convenience. Use representative (validation) data instead.
"""
with torch.inference_mode():
for _ in range(10):
x = torch.rand(1, 2, 28, 28)
m(x)
"""Convert"""
torch.quantization.convert(m, inplace=True)
# print("M=",m)
# print("M[1]=",m[1])
"""Check"""
print(m[1].weight().element_size()) # 1 byte instead of 4 bytes for FP32
FX 模式下的静态量化:
## FX GRAPH
from torch.quantization import quantize_fx
m.eval()
qconfig_dict = {"": torch.quantization.get_default_qconfig(backend)}
m=nn.Sequential(
nn.Conv2d(2,64,3),
nn.ReLU(),
nn.Conv2d(64, 128, 3),
nn.ReLU()
)
model_to_quantize = m
# Prepare
model_prepared = quantize_fx.prepare_fx(model_to_quantize, qconfig_dict)
# Calibrate - Use representative (validation) data.
with torch.inference_mode():
for _ in range(10):
x = torch.rand(1, 2, 28, 28)
model_prepared(x)
# quantize
model_quantized = quantize_fx.convert_fx(model_prepared)
PS:直观对比EAGER模式和FX模式的代码量,可以看出FX模式真香!
感知量化[Quantization-aware Training (QAT)]
PTQ方法适用于大型模型,但在较小的模型中精度会受到影响。当然,这是由于将FP32的模型调整到INT8会造成数值精度的损失(下图a)。QAT通过在训练损失中包含量化误差来解决这一问题,从而训练出一个INT8-first模型。

所有的权重和偏差都以FP32存储,反向传播照常发生。然而,在前向传递中,量化是通过FakeQuantize模块进行内部模拟。它们之所以被称为假的,是因为它们对数据进行量化后立即去量化,添加了类似于量化推理过程中可能遇到的量化噪声。因此,最终的损失即为预期内的量化误差。在此基础上进行优化可以使模型识别出损失函数中更宽的区域,并识别出FP32参数,从而将其量化到INT8中而不会出现显著偏差。
优点:
- QAT的准确度高于PTQ
- Qparams可以在模型训练期间学习,以获得更细粒度的准确性(参见LearnableFakeQuantize)
缺点:
- 模型在QAT中再训练的计算成本可达几百个epoch
# QAT follows the same steps as PTQ, with the exception of the training loop before you actually convert the model to its quantized version
import torch
from torch import nn
backend = "fbgemm" # running on a x86 CPU. Use "qnnpack" if running on ARM.
m = nn.Sequential(
nn.Conv2d(2,64,8),
nn.ReLU(),
nn.Conv2d(64, 128, 8),
nn.ReLU()
)
"""Fuse"""
torch.quantization.fuse_modules(m, ['0','1'], inplace=True) # fuse first Conv-ReLU pair
torch.quantization.fuse_modules(m, ['2','3'], inplace=True) # fuse second Conv-ReLU pair
"""Insert stubs"""
m = nn.Sequential(torch.quantization.QuantStub(),
*m,
torch.quantization.DeQuantStub())
"""Prepare"""
m.train()
m.qconfig = torch.quantization.get_default_qconfig(backend)
torch.quantization.prepare_qat(m, inplace=True)
"""Training Loop"""
n_epochs = 10
opt = torch.optim.SGD(m.parameters(), lr=0.1)
loss_fn = lambda out, tgt: torch.pow(tgt-out, 2).mean()
for epoch in range(n_epochs):
x = torch.rand(10,2,24,24)
out = m(x)
loss = loss_fn(out, torch.rand_like(out))
opt.zero_grad()
loss.backward()
opt.step()
"""Convert"""
m.eval()
torch.quantization.convert(m, inplace=True)
灵敏性分析
并不是所有层对量化的反应都是一样的,有些层对精确的下降比其他层更敏感。确定能够最大限度降低精度的最佳层组合非常耗时,因此可以进行一次灵敏度分析,以确定哪些层是最敏感的,并在这些层上保持FP32的精度。在相关学者的实验中,只跳过2个卷积层(在MobileNet v1中总共28个传输层),就能获得接近fp32的精度。使用FX图形模式,可以很容易地创建自定义qconfig:
# ONE-AT-A-TIME SENSITIVITY ANALYSIS
for quantized_layer, _ in model.named_modules():
print("Only quantizing layer: ", quantized_layer)
# The module_name key allows module-specific qconfigs.
qconfig_dict = {"": None,
"module_name":[(quantized_layer, torch.quantization.get_default_qconfig(backend))]}
model_prepared = quantize_fx.prepare_fx(model, qconfig_dict)
# calibrate
model_quantized = quantize_fx.convert_fx(model_prepared)
# evaluate(model)
另一种方法是比较FP32和INT8层的统计数据,常用的度量标准是信噪比(信噪比)和均方误差。这种比较分析也有助于指导进一步的优化。
PyTorch在Numeric Suite下提供了帮助进行这种分析的工具。从完整教程了解更多关于使用Numeric Suite的信息。
# extract from https://pytorch.org/tutorials/prototype/numeric_suite_tutorial.html
import torch.quantization._numeric_suite as ns
def SQNR(x, y):
# Higher is better
Ps = torch.norm(x)
Pn = torch.norm(x-y)
return 20*torch.log10(Ps/Pn)
wt_compare_dict = ns.compare_weights(fp32_model.state_dict(), int8_model.state_dict())
for key in wt_compare_dict:
print(key, compute_error(wt_compare_dict[key]['float'], wt_compare_dict[key]['quantized'].dequantize()))
act_compare_dict = ns.compare_model_outputs(fp32_model, int8_model, input_data)
for key in act_compare_dict:
print(key, compute_error(act_compare_dict[key]['float'][0], act_compare_dict[key]['quantized'][0].dequantize()))
以resnet18为例
完整代码如下:
# -*- coding: utf-8 -*-
# @Time : 2022/8/01 14:44
# @Author : JasonLiu
# @FileName: pytorch_int8.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import copy
import torchvision
from torchvision import transforms
from torchvision.models.resnet import resnet50, resnet18
from torch.quantization.quantize_fx import prepare_fx, convert_fx
from torch.ao.quantization.fx.graph_module import ObservedGraphModule
from torch.quantization import get_default_qconfig
from torch import optim
import os
import time
def evaluate_model(model, test_loader, device=torch.device("cpu"), criterion=None):
t0 = time.time()
model.eval()
model.to(device)
running_loss = 0
running_corrects = 0
for inputs, labels in test_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
if criterion is not None:
loss = criterion(outputs, labels).item()
else:
loss = 0
# statistics
running_loss += loss * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
eval_loss = running_loss / len(test_loader.dataset)
eval_accuracy = running_corrects / len(test_loader.dataset)
t1 = time.time()
print(f"eval loss: {eval_loss}, eval acc: {eval_accuracy}, cost: {t1 - t0}")
return eval_loss, eval_accuracy
def train_model(model, train_loader, test_loader, device):
"""
fintune 一个准备去量化,并且校准的模型
"""
# The training configurations were not carefully selected.
learning_rate = 1e-2
num_epochs = 20
criterion = nn.CrossEntropyLoss()
model.to(device)
# It seems that SGD optimizer is better than Adam optimizer for ResNet18 training on CIFAR10.
optimizer = optim.SGD(
model.parameters(), lr=learning_rate, momentum=0.9, weight_decay=1e-5
)
# optimizer = optim.Adam(model.parameters(), lr=learning_rate, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
for epoch in range(num_epochs):
# Training
model.train()
running_loss = 0
running_corrects = 0
for inputs, labels in train_loader:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
train_loss = running_loss / len(train_loader.dataset)
train_accuracy = running_corrects / len(train_loader.dataset)
# Evaluation
model.eval()
eval_loss, eval_accuracy = evaluate_model(
model=model, test_loader=test_loader, device=device, criterion=criterion
)
print("Epoch: {:02d} Train Loss: {:.3f} Train Acc: {:.3f} Eval Loss: {:.3f} Eval Acc: {:.3f}".format(
epoch, train_loss, train_accuracy, eval_loss, eval_accuracy))
return model
def prepare_dataloader(num_workers=8, train_batch_size=128, eval_batch_size=256):
train_transform = transforms.Compose(
[
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]
)
test_transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]
)
train_set = torchvision.datasets.CIFAR10(
root="data", train=True, download=True, transform=train_transform
)
# We will use test set for validation and test in this project.
# Do not use test set for validation in practice!
test_set = torchvision.datasets.CIFAR10(
root="data", train=False, download=True, transform=test_transform
)
train_sampler = torch.utils.data.RandomSampler(train_set)
test_sampler = torch.utils.data.SequentialSampler(test_set)
train_loader = torch.utils.data.DataLoader(
dataset=train_set,
batch_size=train_batch_size,
sampler=train_sampler,
num_workers=num_workers,
)
test_loader = torch.utils.data.DataLoader(
dataset=test_set,
batch_size=eval_batch_size,
sampler=test_sampler,
num_workers=num_workers,
)
return train_loader, test_loader
def quant_fx(model):
"""
使用Pytorch中的FX模式对模型进行量化
"""
model.eval()
qconfig = get_default_qconfig("fbgemm") # 默认是静态量化
qconfig_dict = {
"": qconfig,
# 'object_type': []
}
model_to_quantize = copy.deepcopy(model)
prepared_model = prepare_fx(model_to_quantize, qconfig_dict)
print("prepared model: ", prepared_model)
quantized_model = convert_fx(prepared_model)
print("quantized model: ", quantized_model)
torch.save(model.state_dict(), "r18.pth")
torch.save(quantized_model.state_dict(), "r18_quant.pth")
def calib_quant_model(model, calib_dataloader):
"""
校准函数
"""
assert isinstance(
model, ObservedGraphModule
), "model must be a perpared fx ObservedGraphModule."
model.eval()
with torch.inference_mode():
for inputs, labels in calib_dataloader:
model(inputs)
print("calib done.")
def quant_calib_and_eval(model):
# test only on CPU
model.to(torch.device("cpu"))
model.eval()
qconfig = get_default_qconfig("fbgemm")
qconfig_dict = {
"": qconfig,
# 'object_type': []
}
model2 = copy.deepcopy(model)
model_prepared = prepare_fx(model2, qconfig_dict)
model_int8 = convert_fx(model_prepared)
model_int8.load_state_dict(torch.load("r18_quant.pth"))
model_int8.eval()
a = torch.randn([1, 3, 224, 224])
o1 = model(a)
o2 = model_int8(a)
diff = torch.allclose(o1, o2, 1e-4)
print(diff)
print(o1.shape, o2.shape)
print(o1, o2)
# get_output_from_logits(o1)
# get_output_from_logits(o2)
train_loader, test_loader = prepare_dataloader()
print("model:")
evaluate_model(model, test_loader)
print("Not calibration model_int8:")
evaluate_model(model_int8, test_loader)
# calib quant model
model2 = copy.deepcopy(model)
model_prepared = prepare_fx(model2, qconfig_dict)
model_int8 = convert_fx(model_prepared)
torch.save(model_int8.state_dict(), "r18.pth")
model_int8.eval()
model_prepared = prepare_fx(model2, qconfig_dict)
calib_quant_model(model_prepared, test_loader) # 对模型进行校准
model_int8 = convert_fx(model_prepared)
torch.save(model_int8.state_dict(), "r18_quant_calib.pth")
print("Do calibration model_int8:")
evaluate_model(model_int8, test_loader)
if __name__ == "__main__":
# 然后训练一波模型
train_loader, test_loader = prepare_dataloader()
# first finetune model on cifar, we don't have imagnet so using cifar as test
model = resnet18(pretrained=True)
model.fc = nn.Linear(512, 10)
if os.path.exists("r18_row.pth"):
model.load_state_dict(torch.load("r18_row.pth", map_location="cpu"))
else:
train_model(model, train_loader, test_loader, torch.device("cuda"))
print("train finished.")
torch.save(model.state_dict(), "r18_row.pth")
# 模型量化
quant_fx(model)
# 对比是否 calibration 的影响
quant_calib_and_eval(model)
运行结果如下:
model:
eval loss: 0.0, eval acc: 0.8501999974250793, cost: 8.789356231689453
Not calibration model_int8:
eval loss: 0.0, eval acc: 0.16680000722408295, cost: 4.30501914024353
calib done.
Do calibration model_int8:
eval loss: 0.0, eval acc: 0.8482999801635742, cost: 4.916393041610718
可以看出加入校准后,精度迅速恢复。
使用建议
- 大模型(10M+参数)对量化误差具有更强的鲁棒性。
- 基于FP32 checkpoint的模型量化比从零开始训练INT8模型会有更好的准确性
- 分析模型运行时并非总是必要的,但可以帮助识别推理过程的瓶颈层。
- 动态量化是最简单的,常为首选方案,特别是当模型有许多线性或RNN层。换句话说,动态量化常用以NLP领域的模型。而静态量化一般用在CV领域,主要针对CNN网络。
- 使用对称的每通道量化一般搭配
MinMaxobservers 量化权重。使用affine-per-tensor 量化一般搭配MovingAverageMinMaxobservers 的量化激活。 - 使用像SQNR这样的指标来识别哪些层最容易出现量化错误。从而关闭这些层的量化。
- 使用QAT微调约10%的原始训练计划,退火学习率计划从初始训练学习率的1%开始。