PyTorch数据集标准化-Torchvision.Transforms.Normalize()(pytorch系列-31)
PyTorch数据集归一化- torchvision.transforms.Normalize()
在本集中,我们将学习如何规范化数据集。我们将看到如何在代码中执行数据集归一化,还将看到归一化如何影响神经网络训练过程。
数据归一化
数据归一化的概念是一个通用概念,指的是将数据集的原始值转换为新值的行为。新值通常是相对于数据集本身进行编码的,并以某种方式进行缩放。
特征缩放
出于这个原因,有时数据归一化的另一个名称是特征缩放。这个术语指的是,在对数据进行归一化时,我们经常会将给定数据集的不同特征转化为相近的范围。
在这种情况下,我们不仅仅是考虑一个值的数据集,还要考虑一个具有多个特征的元素的数据集,及每个特征的值。
举例来说,假设我们要处理的是一个人的数据集,我们的数据集中有两个相关的特征,年龄和体重。在这种情况下,我们可以观察到,这两个特征集的大小或尺度是不同的,即体重平均大于年龄。
在使用机器学习算法进行比较或计算时,这种幅度上的差异可能是个问题。因此,这可能是我们希望通过特征缩放将这些特征的值缩放到一些相近尺度的原因之一。
规范化示例
当我们对数据集进行归一化时,我们通常会对相对于数据集的每个特定值进行某种形式的信息编码,然后重新缩放数据。考虑下面这个例子:
假设我们有一个正数集合 S 。现在,假设我们从集合s 随机选择一个 x 值并思考:这个 x 值是集合s中最大的数嘛 ?
在这种情况下,答案是我们不知道。我们只是没有足够的信息来回答问题。
但是,现在假设我们被告知 集合 S 通过将每个值除以集合内的最大值进行归一化。通过此标准化过程,已对值最大的信息进行了编码,并对数据进行了重新缩放。
集合中最大的成员是 1,并且数据已按比例缩放到间隔 [0,1]。
什么是标准化
数据标准化是一种特殊的归一化技术。有时称为z-score标准化。z-score标准化(也称为标准分数(Z分数))是每个数据点的转换值。
为了使用标准化对数据集进行归一化,我们取每个值 x 在数据集内部并将其转换为其对应的z值使用以下公式:

对数据集中每个 x值进行如上计算后,我们又有一个新的标准化数据集 z。平均值和标准差值是相对于整个数据集而言的。
假设给定的集合S中有n个数字。
集合S的均值由以下等式给出:

集合 S的标准差由以下等式给出:

我们已经看到,通过除以最大值进行归一化的效果是如何将最大值转化为1 ,这个标准化过程将数据集的平均值转化为0,标准差转化为1。
需要注意的是,当我们对数据集进行归一化时,我们通常会将这些操作按特征分组。这意味着平均值和标准差值是相对于每个被归一化的特征集而言的。如果我们处理的是图像,特征是RGB颜色通道,所以我们对每个颜色通道进行归一化时,要考虑到每个图像中所有像素的平均值和标准差,计算出相应颜色通道的平均值和标准差。
用代码规范化数据集
让我们开始一个代码示例。第一步是初始化我们的数据集,因此在本示例中,我们将使用到目前为止在该系列中一直使用的Fashion MNIST数据集。
train_set = torchvision.datasets.FashionMNIST(
root='./data'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
PyTorch 允许我们使用刚才看到的标准化过程对数据集进行标准化,将每个颜色通道的平均值和标准差传递给 Normalize() 变换。
torchvision.transforms.Normalize(
[meanOfChannel1, meanOfChannel2, meanOfChannel3]
, [stdOfChannel1, stdOfChannel2, stdOfChannel3]
)
由于我们的数据集里面的图像只有一个通道,所以我们只需要传入单个平均值和标准差。为了做到这一点,我们需要首先计算这些值。有时候这些值可能会在线程的某个阶段生成,所以我们可以通过这种方式获得。当然我们也可以直接手动计算。
有两种方法可以做到。一种是简单的方法,一种是较难的方法。如果数据集足够小,可以一次性装入内存,简单的方法可以实现。否则,我们必须对数据进行迭代,这就稍微有点难度了。
计算mean和std—简便方法
简单的方法很容易。我们要做的就是使用数据加载器加载数据集,并获得包含所有数据的单个批处理张量。为此,我们将批次大小设置为等于训练集长度。
loader = DataLoader(train_set, batch_size=len(train_set), num_workers=1)
data = next(iter(loader))
data[0].mean(), data[0].std()
(tensor(0.2860), tensor(0.3530))
在这里,我们可以通过简单地使用相应的PyTorch张量方法来获得平均值和标准差。
计算mean与std—困难方法
困难的方法之所以困难,是因为我们需要手动实现均值和标准差的公式,然后对较小的数据集进行迭代。
首先,我们创建一个批量较小的数据加载器。
loader = DataLoader(train_set, batch_size=1000, num_workers=1)
然后,我们计算 n 值或总像素数:
num_of_pixels = len(train_set)* 28 * 28
请注意28*28是我们数据集中的图像的高度和宽度。现在,我们通过遍历每批像素求和像素值,并用该总和除以像素总数来计算平均值。
total_sum = 0
for batch in loader: total_sum += batch[0].sum()
mean = total_sum / num_of_pixels
接下来,我们通过遍历每批来计算平方误差的总和,这使我们能够通过将平方误差的总和除以像素总数并求平方根来计算标准差。
sum_of_squared_error = 0
for batch in loader:
sum_of_squared_error += ((batch[0] - mean).pow(2)).sum()
std = torch.sqrt(sum_of_squared_error / num_of_pixels)
结果:
mean, std
(tensor(0.2860), tensor(0.3530))
使用mean和std值
我们的任务是使用这些值将数据集中的像素值转换为相应的标准化值。为此,我们仅在这次将标准化转换传递给转换合成时才生成新的train_set。
train_set_normal = torchvision.datasets.FashionMNIST(
root='./data'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
, transforms.Normalize(mean, std)
])
)
注意,变换的顺序在构成中很重要。图像被加载为Python PIL对象,所以我们必须在Normalize()变换之前添加ToTensor()变换,因为Normalize()变换需要一个张量作为输入。
现在,我们的数据集已经有了一个 Normalize() 变换,当数据加载器加载数据时,数据将被归一化。请记住,对于每张图像,下面的变换将应用于图像中的每个像素。

这样做的效果是,我们的数据相对于数据集的平均值和标准差进行了重新缩放。让我们通过重新计算这些值来看看实际情况。
loader = DataLoader(
train_set_normal
, batch_size=len(train_set)
, num_workers=1
)
data = next(iter(loader))
data[0].mean(), data[0].std()
(tensor(1.2368e-05), tensor(1.0000))
我们的平均值不是0,而标准偏差值为1 。
使用规范化数据进行训练
现在让我们看看使用和不使用标准化数据的训练如何影响训练过程。为了这个测试,我们会在每种条件下运行20个周期。
让我们创建一个训练集的字典,我们可以在整个课程中建立的框架中使用它来运行测试。
trainsets = {
'not_normal': train_set
,'normal': train_set_normal
}
现在,我们可以将这两个train_sets添加到我们的配置中,并在运行循环中访问值。
params = OrderedDict(
lr = [.01]
, batch_size = [1000]
, num_workers = [1]
, device = ['cuda']
, trainset = ['not_normal', 'normal']
)
m = RunManager()
for run in RunBuilder.get_runs(params):
device = torch.device(run.device)
network = Network().to(device)
loader = DataLoader(
trainsets[run.trainset]
, batch_size=run.batch_size
, num_workers=run.num_workers
)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, loader)
for epoch in range(20):
m.begin_epoch()
for batch in loader:
images = batch[0].to(device)
labels = batch[1].to(device)
preds = network(images) # Pass Batch
loss = F.cross_entropy(preds, labels) # Calculate Loss
optimizer.zero_grad() # Zero Gradients
loss.backward() # Calculate Gradients
optimizer.step() # Update Weights
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
m.save('results')
训练结果
让我们按准确性对结果进行排序。
pd.DataFrame.from_dict(m.run_data).sort_values('accuracy',ascending = False)
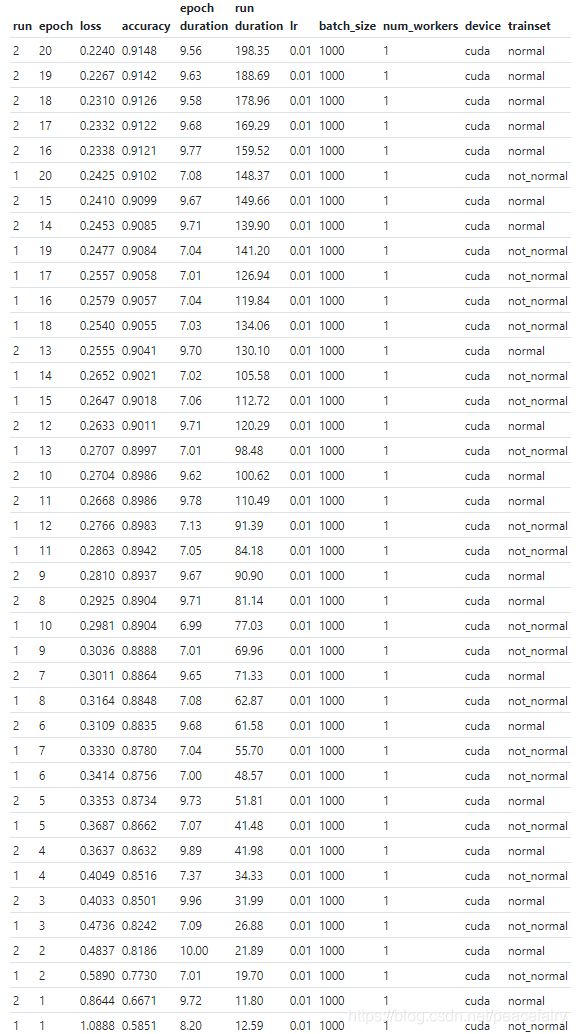
在这里,我们可以看到,在多次周期迭代之后,我们的网络在使用归一化数据时有更高的准确性。有时被称为网络的快速收敛。
需要注意的是,并不总是归一化的数据更好。一个好的经验法则是在有疑问的时候,两种方式都要尝试。
另外,你听说过批量归一化吗?我们会批量归一化或批量规范化就是在网络的各层输出激活上,在网络的各层里面进行的这个同样的过程。
在本集中,我们将学习如何规范化数据集。我们将看到如何在代码中执行数据集归一化,还将看到归一化如何影响神经网络训练过程。
英文原文链接是:https://editor.csdn.net/md?articleId=108020179