【数据挖掘竞赛】零基础入门数据挖掘-二手汽车价格预测
目录
一、导入数据
二、数据查看
可视化缺失值占比
绘制所有变量的柱形图,查看数据
查看各特征与目标变量price的相关性
三、数据处理
处理异常值
查看seller,offerType的取值
查看特征 notRepairedDamage
异常值截断
填充缺失值
删除取值无变化的特征
查看目标变量price
对price做对数log变换
四、特征构造
构造新特征:计算某品牌的销售统计量
构造新特征:使用时间
对连续型特征数据进行分桶
对数值型特征做归一化
匿名特征交叉
平均数编码
五、特征筛选
计算各列于交易价格的相关性
对类别特征进行 OneEncoder
切分特征和标签
用lightgbm筛选特征
一、导入数据
import pandas as pd
import numpy as np
#coding:utf-8
#导入warnings包,利用过滤器来实现忽略警告语句。
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
#显示所有列
pd.set_option('display.max_columns',None)
# #显示所有行
# pd.set_option('display.max_rows',None)
Train_data = pd.read_csv("二手汽车价格预测/used_car_train_20200313.csv",sep=' ')
Test_data = pd.read_csv('二手汽车价格预测/used_car_testB_20200421.csv', sep=' ')
Train_data.shape,Test_data.shape#((150000, 31), (50000, 30))
Train_data.tail()
# Test_data.head()二、数据查看
Train_data.info()Data columns (total 31 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 SaleID 150000 non-null int64 1 name 150000 non-null int64 2 regDate 150000 non-null int64 3 model 149999 non-null float64 4 brand 150000 non-null int64 5 bodyType 145494 non-null float64 6 fuelType 141320 non-null float64 7 gearbox 144019 non-null float64 8 power 150000 non-null int64 9 kilometer 150000 non-null float64 10 notRepairedDamage 150000 non-null object 11 regionCode 150000 non-null int64 12 seller 150000 non-null int64 13 offerType 150000 non-null int64 14 creatDate 150000 non-null int64 15 price 150000 non-null int64 16 v_0 150000 non-null float64 17 v_1 150000 non-null float64 18 v_2 150000 non-null float64 19 v_3 150000 non-null float64 20 v_4 150000 non-null float64 21 v_5 150000 non-null float64 22 v_6 150000 non-null float64 23 v_7 150000 non-null float64 24 v_8 150000 non-null float64 25 v_9 150000 non-null float64 26 v_10 150000 non-null float64 27 v_11 150000 non-null float64 28 v_12 150000 non-null float64 29 v_13 150000 non-null float64 30 v_14 150000 non-null float64 dtypes: float64(20), int64(10), object(1)
Train_data.duplicated().sum()#没有重复值
Train_data.isnull().sum()SaleID 0 name 0 regDate 0 model 1 brand 0 bodyType 4506 fuelType 8680 gearbox 5981 power 0 kilometer 0 notRepairedDamage 0 regionCode 0 seller 0 offerType 0 creatDate 0 price 0 v_0 0 v_1 0 v_2 0 v_3 0 v_4 0 v_5 0 v_6 0 v_7 0 v_8 0 v_9 0 v_10 0 v_11 0 v_12 0 v_13 0 v_14 0 dtype: int64
bodyType , fuelType,gearbox,model,这几个特征存在缺失值。
可视化缺失值占比
# nan可视化
missing = Train_data.isnull().sum()
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()

绘制所有变量的柱形图,查看数据
Train_data.hist(bins=50,figsize=(20,15))
plt.cla() #清除axes
图中可以看出,seller,offerType,creatDate这几个特征值分布不均匀,分别查看
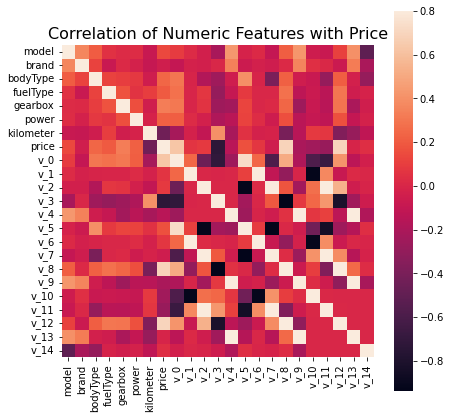
查看各特征与目标变量price的相关性
#把字符串类型的变量、以及一些无关的变量去掉,获得需要的列名
numeric_columns=Train_data.select_dtypes(exclude='object').columns
columns=[col for col in numeric_columns if col not in ['SaleID', 'name']]
#根据列名提取数据
train_set=Train_data[columns]
#计算各列于交易价格的相关性
correlation=train_set.corr()
correlation['price'].sort_values(ascending = False)
price 1.000000 v_12 0.692823 v_8 0.685798 v_0 0.628397 regDate 0.611959 gearbox 0.329075 bodyType 0.241303 power 0.219834 fuelType 0.200536 v_5 0.164317 model 0.136983 v_2 0.085322 v_6 0.068970 v_1 0.060914 v_14 0.035911 regionCode 0.014036 creatDate 0.002955 seller -0.002004 v_13 -0.013993 brand -0.043799 v_7 -0.053024 v_4 -0.147085 v_9 -0.206205 v_10 -0.246175 v_11 -0.275320 kilometer -0.440519 v_3 -0.730946 offerType NaN Name: price, dtype: float64
f , ax = plt.subplots(figsize = (7, 7))
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
三、数据处理
处理异常值
-
查看seller,offerType的取值
Train_data['seller'].value_counts()
#将seller其中的异常值1改为0
Train_data['seller'] = Train_data['seller'][Train_data['seller']==1]=0
Train_data['seller'].value_counts()
0 149999 1 1 Name: seller, dtype: int64
Train_data['offerType'].value_counts()
0 150000 Name: offerType, dtype: int64
可以看出,seller,offerType这两个特征的取值无变化,几乎倒向同一个值,可以删除。
-
查看特征 notRepairedDamage
notRepairedDamage 中存在空缺值,但空缺值用“-”表示,所以数据查看发现不了空缺值,将“-”替换成NaN。
Train_data['notRepairedDamage'].value_counts()
Train_data['notRepairedDamage'].replace('-',np.nan,inplace = True)
0.0 111361 - 24324 1.0 14315 Name: notRepairedDamage, dtype: int64
Train_data['notRepairedDamage'].value_counts()0.0 111361 1.0 14315 Name: notRepairedDamage, dtype: int64
-
异常值截断
Train_data['power'].value_counts()
0 12829
75 9593
150 6495
60 6374
140 5963
...
513 1
1993 1
19 1
751 1
549 1
Name: power, Length: 566, dtype: int64
power在题目中要求范围
| power | 发动机功率:范围 [ 0, 600 ] |
进行异常值截断
#异常值截断
Train_data['power'][Train_data['power']>600]=600
Train_data['power'][Train_data['power']<1] = 1
Train_data['v_13'][Train_data['v_13']>6] = 6
Train_data['v_14'][Train_data['v_14']>4] = 4
填充缺失值
类别型特征用众数填充缺失值
print(Train_data.bodyType.mode())
print(Train_data.fuelType.mode())
print(Train_data.gearbox.mode())
print(Train_data.model.mode())
#用众数填补空缺值
Train_data['bodyType']=Train_data['bodyType'].fillna(0)
Train_data['fuelType']=Train_data['fuelType'].fillna(0)
Train_data['gearbox']=Train_data['gearbox'].fillna(0)
Train_data['model']=Train_data['model'].fillna(0)
Train_data.isnull().sum()删除取值无变化的特征
'seller','offerType'
#删除取值没有变化的列
Train_data.head()
Train_data = Train_data.drop(['seller','offerType'],axis = 1)
Train_data.head()
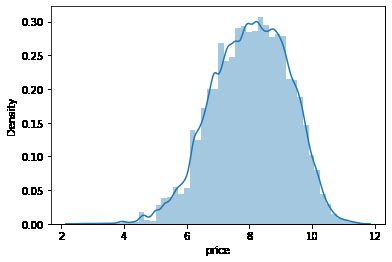
查看目标变量price
# 查看目标变量的skewness and kurtosis
sns.distplot(Train_data['price']);
print("Skewness: %f" % Train_data['price'].skew())#偏度
print("Kurtosis: %f" % Train_data['price'].kurt())#峰度
# Train_data.skew(), Train_data.kurt()Skewness: 3.346487 Kurtosis: 18.995183

## 查看目标变量的具体频数
## 绘制标签的统计图,查看标签分布
plt.hist(Train_data['price'], orientation = 'vertical',histtype = 'bar', color ='red')
plt.show() 
对price的长尾数据进行截取,做对数log变换
np.log1p ( )
数据预处理时首先可以对偏度比较大的数据用log1p函数进行转化,使其更加服从高斯分布,此步处理可能会使我们后续的分类结果得到一个好的结果.
# 目标变量进行对数变换服从正态分布
Train_data['price'] = np.log1p(Train_data['price'])
plt.hist(Train_data['price'], orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()
sns.distplot(Train_data['price']);
print("Skewness: %f" % Train_data['price'].skew())#偏度
print("Kurtosis: %f" % Train_data['price'].kurt())#峰度
Skewness: -0.261727 Kurtosis: -0.182127
四、特征构造
4.1、构造新特征:计算某品牌的销售统计量
# 计算某品牌的销售统计量
Train_gb = Train_data.groupby("brand")
all_info = {}
for kind, kind_data in Train_gb:
info = {}
kind_data = kind_data[kind_data['price'] > 0]
info['brand_amount'] = len(kind_data)
info['brand_price_max'] = kind_data.price.max()
info['brand_price_median'] = kind_data.price.median()
info['brand_price_min'] = kind_data.price.min()
info['brand_price_sum'] = kind_data.price.sum()
info['brand_price_std'] = kind_data.price.std()
info['brand_price_average'] = round(kind_data.price.sum() / (len(kind_data) + 1), 2)
all_info[kind] = info
brand_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={"index": "brand"})
Train_data = Train_data.merge(brand_fe, how='left', on='brand')
4.2、构造新特征:使用时间
一般来说汽车价格与使用时间成反比
# 使用时间:
Train_data['creatDate'] - Train_data['regDate']#一般来说汽车价格与使用时间成反比
# 数据里有时间出错的格式,errors='coerce',遇到不能转换的数据赋值为nan
Train_data['used_time'] = (pd.to_datetime(Train_data['creatDate'], format='%Y%m%d', errors='coerce') -
pd.to_datetime(Train_data['regDate'], format='%Y%m%d', errors='coerce')).dt.days
Train_data['used_time'].isnull().sum()
Train_data['used_time'].mean()#4432.082407160321
#用平均数或众数填充缺失值
Train_data['used_time'].fillna(4432,inplace = True)
Train_data['used_time'].isnull().sum()4.3、对连续型特征数据进行分桶
#对连续型数据进行分桶
#对power进行分桶
bin = [i*10 for i in range(31)]#分成30个桶
Train_data['power_bin'] = pd.cut(Train_data['power'], bin, labels=False)
Train_data[['power_bin', 'power']].head()kilometer已经分桶了
plt.hist(Train_data['kilometer'])# 删除不需要的数据
Train_data = Train_data.drop(['name','SaleID', 'regionCode'], axis=1)
Train_data.head()- 目前的数据其实已经可以给树模型使用了,所以我们导出一下
Train_data.to_csv('data_for_tree.csv', index=0)
4.5、对数值型特征做归一化
# 我们可以再构造一份特征给 LR NN 之类的模型用
# 之所以分开构造是因为,不同模型对数据集的要求不同
# 我们看下数据分布:
Train_data['power'].plot.hist() 
# 我们对其取 log,在做归一化
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
Train_data['power'] = np.log1p(Train_data['power'] + 1)
Train_data['power'] = ((Train_data['power'] - np.min(Train_data['power'])) / (np.max(Train_data['power']) - np.min(Train_data['power'])))
Train_data['power'].plot.hist()

# kilometer做过分桶处理了,所以我们可以直接做归一化
Train_data['kilometer'] = ((Train_data['kilometer'] - np.min(Train_data['kilometer'])) /
(np.max(Train_data['kilometer']) - np.min(Train_data['kilometer'])))
Train_data['kilometer'].plot.hist()
# 对之前构造的以下特征进行归一化
# 'brand_amount', 'brand_price_average', 'brand_price_max',
# 'brand_price_median', 'brand_price_min', 'brand_price_std',
# 'brand_price_sum'
# 这里不再一一举例分析了,直接做变换,
def max_min(x):
return (x - np.min(x)) / (np.max(x) - np.min(x))
Train_data['brand_amount'] = ((Train_data['brand_amount'] - np.min(Train_data['brand_amount'])) /
(np.max(Train_data['brand_amount']) - np.min(Train_data['brand_amount'])))
Train_data['brand_price_average'] = ((Train_data['brand_price_average'] - np.min(Train_data['brand_price_average'])) /
(np.max(Train_data['brand_price_average']) - np.min(Train_data['brand_price_average'])))
Train_data['brand_price_max'] = ((Train_data['brand_price_max'] - np.min(Train_data['brand_price_max'])) /
(np.max(Train_data['brand_price_max']) - np.min(Train_data['brand_price_max'])))
Train_data['brand_price_median'] = ((Train_data['brand_price_median'] - np.min(Train_data['brand_price_median'])) /
(np.max(Train_data['brand_price_median']) - np.min(Train_data['brand_price_median'])))
Train_data['brand_price_min'] = ((Train_data['brand_price_min'] - np.min(Train_data['brand_price_min'])) /
(np.max(Train_data['brand_price_min']) - np.min(Train_data['brand_price_min'])))
Train_data['brand_price_std'] = ((Train_data['brand_price_std'] - np.min(Train_data['brand_price_std'])) /
(np.max(Train_data['brand_price_std']) - np.min(Train_data['brand_price_std'])))
Train_data['brand_price_sum'] = ((Train_data['brand_price_sum'] - np.min(Train_data['brand_price_sum'])) /
(np.max(Train_data['brand_price_sum']) - np.min(Train_data['brand_price_sum'])))
Train_data.head()4.6、匿名特征交叉
#匿名特征交叉
num_cols = [0,2,3,6,8,10,12,14]
for index, value in enumerate(num_cols):
for j in num_cols[index+1:]:
Train_data['new'+str(value)+'*'+str(j)]=Train_data['v_'+str(value)]*Train_data['v_'+str(j)]
Train_data['new'+str(value)+'+'+str(j)]=Train_data['v_'+str(value)]+Train_data['v_'+str(j)]
Train_data['new'+str(value)+'-'+str(j)]=Train_data['v_'+str(value)]-Train_data['v_'+str(j)]
num_cols1 = [3,5,1,11]
for index, value in enumerate(num_cols1):
for j in num_cols1[index+1:]:
Train_data['new'+str(value)+'-'+str(j)]=Train_data['v_'+str(value)]-Train_data['v_'+str(j)]
for i in range(15):
Train_data['new'+str(i)+'*year']=Train_data['v_'+str(i)] * Train_data['used_time']
# 这份数据可以给 LR 用
Train_data.to_csv('Train_data_for_lr.csv', index=0)
Train_data.head()五、特征筛选
5.1、查看各列于交易价格的相关性
correlation=Train_data.corr()
x=correlation['price'].sort_values(ascending = False)
y = np.abs(x)>=0.01
Train_data = Train_data['y'] 5.2、对类别特征进行 OneEncoder
data = pd.get_dummies(data, columns=['model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'notRepairedDamage', 'power_bin'])
print(data.shape)
data.columns(200000, 364)
Index(['SaleID', 'name', 'regDate', 'power', 'kilometer', 'regionCode',
'creatDate', 'price', 'v_0', 'v_1',
...
'power_bin_20.0', 'power_bin_21.0', 'power_bin_22.0', 'power_bin_23.0',
'power_bin_24.0', 'power_bin_25.0', 'power_bin_26.0', 'power_bin_27.0',
'power_bin_28.0', 'power_bin_29.0'],
dtype='object', length=364)
5.3、切分特征和标签
#删除price
train_set=data.copy()
train_set.tail()
y_train=train_set['price']
train_set = train_set.drop("price",axis = 1)
x_train=train_set[[col for col in train_set.columns if col not in ['model','brand','bodyType','fuelType',
'gearbox','notRepairedDamage','creatDate',
'regDate', 'price']]]
#切分特征和标签
train_set=Train_data.copy()
# x_train=train_set[[col for col in train_set.columns if col not in ['price']]]
x_train=x_train.loc[:, x_train.columns != 'price']
y_train=train_set['price']
用lightgbm筛选特征
import lightgbm as lgb
from sklearn.model_selection import train_test_split
im
from sklearn.metrics import mean_squared_error as MSE
features = pd.get_dummies(x_train)
feature_names = list(features.columns)
features = np.array(features)
labels = np.array(y_train).reshape((-1, ))
feature_importance_values = np.zeros(len(feature_names))
task='regression'
early_stopping=True
eval_metric= 'l2'
n_iterations=10
for _ in range(n_iterations):
if task == 'classification':
model = lgb.LGBMClassifier(n_estimators=1000, learning_rate = 0.05, verbose = -1)
if task =='regression':
model = lgb.LGBMRegressor(n_estimators=1000, learning_rate = 0.05, verbose = -1)
else:
raise ValueError('Task must be either "classification" or "regression"')
#提前终止训练,需要验证集
if early_stopping:
train_features, valid_features, train_labels, valid_labels = train_test_split(features, labels, test_size = 0.15)
# Train the model with early stopping
model.fit(train_features, train_labels, eval_metric = eval_metric,eval_set = [(valid_features, valid_labels)],early_stopping_rounds = 100, verbose = -1)
gc.enable()
del train_features, train_labels, valid_features, valid_labels
gc.collect()
else:
model.fit(features, labels)
# Record the feature importances
feature_importance_values += model.feature_importances_ / n_iterations
feature_importances = pd.DataFrame({'feature': feature_names, 'importance': feature_importance_values})
#按照重要性大小对特征进行排序
feature_importances = feature_importances.sort_values('importance', ascending = False).reset_index(drop = True)
#计算特征的相对重要性,全部特征的相对重要性之和为1
feature_importances['normalized_importance'] = feature_importances['importance'] / feature_importances['importance'].sum()
#计算特征的累计重要性
#cutsum :返回给定 axis 上的累计和
feature_importances['cumulative_importance'] = np.cumsum(feature_importances['normalized_importance'])
#选取累计重要性大于0.99的特征,这些特征将会被删除掉。
drop_columns=list(feature_importances.query('cumulative_importance>0.99')['feature'])#去掉重要度低的列
x_set=x_train.copy()
x_set.drop(drop_columns,axis=1,inplace=True)
#对数据集总体概览
#显示所有行
pd.set_option("display.max_info_columns", 300) # 设置info中信息显示数量为200
x_set.info()六、建模调参
# 构建模型拟合的评价指标
from sklearn.metrics import mean_squared_error,mean_absolute_error
def model_goodness(model,x,y):
prediction=model.predict(x)
mae=mean_absolute_error(y,prediction)
mse=mean_squared_error(y,prediction)
rmse=np.sqrt(mse)
print('MAE:',mae)#绝对平均误差
print('MSE:',mse)#均方差
print('RMSE:',rmse)#均方根# 定义模型泛化能力的指标计算函数:
from sklearn.model_selection import cross_val_score
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())#先用简单线性回归模型拟合
from sklearn.linear_model import LinearRegression
lin_reg=LinearRegression()
lin_reg.fit(x_set,y_train)
model_goodness(lin_reg,x_set,y_train)
'''MAE: 0.17541397968387218
MSE: 0.07846792179703589
RMSE: 0.28012126266500353'''
随机森林
from sklearn.ensemble import RandomForestRegressor
forest_reg=RandomForestRegressor()0
forest_reg.fit(x_set,y_train)
model_goodness(forest_reg,x_set,y_train)
# 采用10折交叉验证的方法来验证模型的泛化能力
scores=cross_val_score(forest_reg,x_set,y_train,scoring='neg_mean_absolute_error',cv=10)
mae_scores=np.abs(-scores)
display_scores(mae_scores)
''MAE: 0.047468466346616035
MSE: 0.008013848284210116
RMSE: 0.08952009988941095'''存在过拟合,
'''Scores: [0.1294032 0.12707153 0.12940989 0.12829302 0.13042102 0.1285104
0.12762524 0.12703461 0.1289176 0.12968754]
Mean: 0.12863740448866307
Standard deviation: 0.0010828607409916612'''
GBDT
# GBDT
from sklearn.ensemble import GradientBoostingRegressor
gbrt=GradientBoostingRegressor()
gbrt.fit(x_set,y_train)
model_goodness(gbrt,x_set,y_train)
scores=cross_val_score(gbrt,x_set,y_train,scoring='neg_mean_absolute_error',cv=10)
mae_scores=np.abs(scores)
display_scores(mae_scores)
MAE: 0.1579591089700307
MSE: 0.06534997589709124
RMSE: 0.2556364134803398
Scores: [0.16032467 0.15964983 0.16159922 0.15899314 0.16286916 0.16034439
0.15793287 0.1580428 0.15949101 0.16185252]
Mean: 0.16010996168246888
Standard deviation: 0.0015434916175588425
XGBoost
# XGBoost
import lightgbm as lgb
import xgboost as xgb
xgb_reg= xgb.XGBRegressor()
xgb_reg.fit(x_set,y_train)
model_goodness(xgb_reg,x_set,y_train)
scores=cross_val_score(xgb_reg,x_set,y_train,scoring='neg_mean_absolute_error',cv=10)
mae_scores=np.abs(scores)
display_scores(mae_scores)
'''
MAE: 0.11684430449593118
MSE: 0.03652492452344296
RMSE: 0.1911149510724971
Scores: [0.13500033 0.1333282 0.13477914 0.13414655 0.1365417 0.13534464
0.13483075 0.13339024 0.1352027 0.13584453]
Mean: 0.1348408781266727
Standard deviation: 0.000958580534103817'''
LightGBM
#LightGBM
lgb_reg=lgb.LGBMRegressor()
lgb_reg.fit(x_set,y_train)
model_goodness(lgb_reg,x_set,y_train)
scores=cross_val_score(lgb_reg,x_set,y_train,scoring='neg_mean_absolute_error',cv=10)
mae_scores=np.abs(scores)
display_scores(mae_scores)
'''
MAE: 0.1307250662409778
MSE: 0.049472769306324126
RMSE: 0.22242474976118132
Scores: [0.13610695 0.13486826 0.13710767 0.13597915 0.13788547 0.13687976
0.13471174 0.13481778 0.13525209 0.13684043]
Mean: 0.13604493148788416
Standard deviation: 0.0010560012820324028'''
还缺个模型调参和模型融合,回头补
天池长期赛:二手车价格预测(422方案分享)
阿里天池竞赛项目——二手车交易价格预测
基于Python实现的二手车价格预测_biyezuopin的博客-CSDN博客_python二手车价格预测