yolov4-tiny通过pytorch导出不带split算子的onnx
前言
最近一直忙于模型移植板端,用了不少厂家的sdk,发现挺多厂家的sdk都处于起步阶段,缺少一些技术支持,比如不支持五维向量,不支持一些onnx算子,不支持过深的模型结构,我最爱的Yolov5,v6,v7等高精度目标检测模型都无法移植上去,那就只能把眼光放回几年前尝试移植yolov3tiny和yolov4tiny,结果发现这玩意它要么darknet转onnx,要么是非官方实现的pytorch转onnx,转了之后还要求版本,算子,才能移植。
比如yolov3tiny网上下载的预训练权重本身就有问题(虽然之后修复但因为未知原因仍然没法移植过去),而yolov4tiny的问题在于不支持split算子,所以本文我来分享一下修改yolov4tiny的结构从而导出能移植的onnx,免得后来人又像我一样浪费几天时间折腾。
注:修改onnx有两种方式,导出前改和导出后改,在这里不推荐导出后改,难改也容易出问题,另外网上的onnx可视化修改工具我也试过了,十个里八个修改错误,基本没用。
准备
onnx
onnxsim
pytorch
这些前置要求请根据自己的环境配置。
我这里onnx1.12.0,torch1.11.0+cpu,onnxsim0.4.10。
1.下载yolov4的pytorch版源码和对应pth文件。
git clone https://github.com/bubbliiiing/yolov4-tiny-pytorch
进github页面里附带的百度网盘地址:
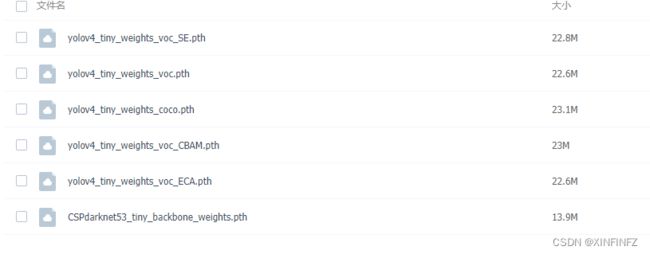
下载yolov4_tiny_weights_coco.pth即可。这里给不懂pytorch的说明一下,pth需配合模型网络代码才能成功加载,你如果只load pth只有一串字典。。
2.下载解压后打开目录下predict.py文件:
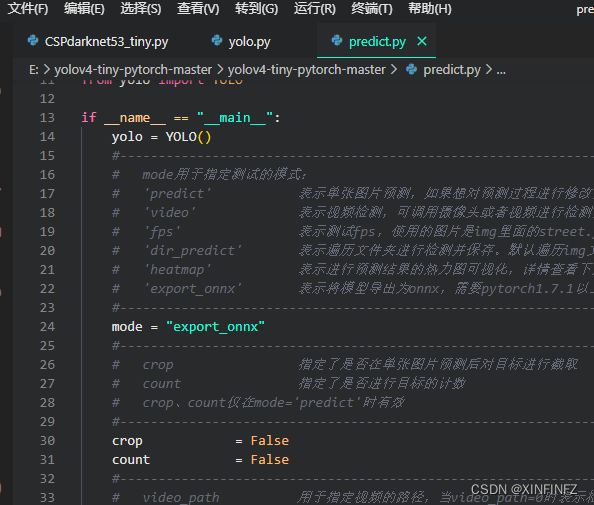
把mode里的值修改为export_onnx,就可以运行python predict.py产生onnx了
3.打开同一目录下yolo.py文件,查看或修改如下:
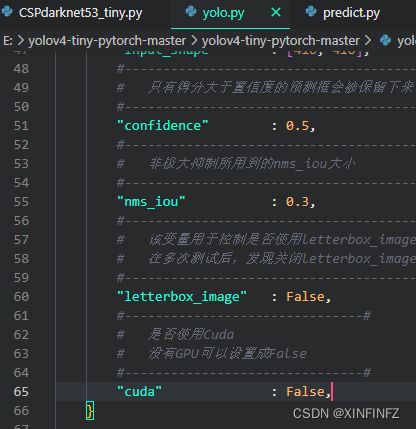
如果你没有显卡或者说没有安装cuda,把cuda设为False,这里默认是True。
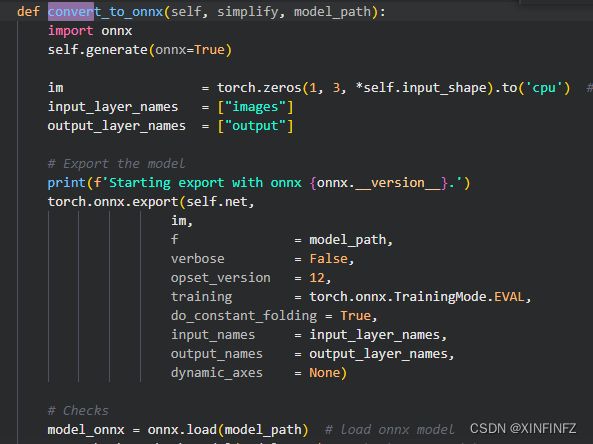
这里是控制torch导出onnx的行为,其中最重要的是opset_version,请根据你所需要的算子版本来,这里默认是12,我需要的也是12,就不改了。此外默认是开启onnxsim简化的,这个简化很重要,能避免torch导出一些不必要的算子。
4.修改nets文件夹里的CSPdarknet53_tiny.py:
经过查找,这里面残差块的torch.split函数导致torch导出onnx时产生了split算子:
c = self.out_channels
# 对特征层的通道进行分割,取第二部分作为主干部分。
x = torch.split(x, c//2, dim = 1)[1]
# 对主干部分进行3x3卷积
x = self.conv2(x)
在netron里表现如下:
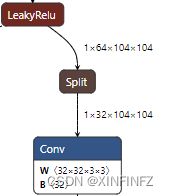
就是沿着第二个维度分成两半然后取第二部分。这其实和torch.chunk函数表现是相同的。
所以我们修改代码如下:
c = self.out_channels
# 对特征层的通道进行分割,取第二部分作为主干部分。
x = torch.chunk(x, 2, dim=1)[1]
# 对主干部分进行3x3卷积
x = self.conv2(x)
5.最后导出,命令行里运行python predict.py,并在model_data文件夹下用netron查看模型。
这里先展示没有开启onnxsim,导出的模型图,你会发现整了多余的shape和gather算子:
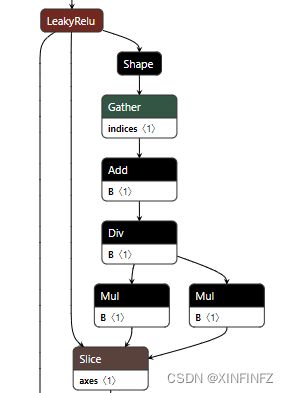
如果按照默认设置开启了onnxsim,就可以导出正确的模型结构图:
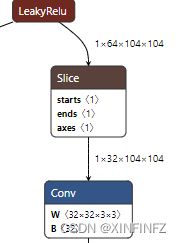
发现split已经完美变成了Slice,达到了我们的目的。
总结
我估计可能有看完的读者会问,既然如此为啥不直接用onnx的api来删除然后插入一个Slice算子呢?之前也讲过了,不仅很复杂,而且你插入之后onnx它不认!与其继续折腾不如在导出前就修改网络结构,只要明白torch和onnx算子的对应关系还是很容易做到的。另外这里预告一下,下一篇文章将介绍如何修改darknet转onnx的结构使得yolov3tiny.onnx能够正确运行,那个东西在github上被提了一堆issue反映shape inference error,但原始作者没有回答。