带你玩转 3D 检测和分割 (三):有趣的可视化
小伙伴们好呀,3D 检测和分割系列文章继续更新啦,在第一篇文章中我们带领大家了解了整个框架的大致流程,第二篇文章我们给大家解析了 MMDetection3D 中的坐标系和核心组件 Box,今天我们将带大家看看 3D 场景中的可视化组件 Visualizer,如何在多个模态数据上轻松可视化并且自由切换?为什么在可视化的时候经常出现一些莫名其妙的问题?
接下来就让我们进入今天的正题吧~
在 MMDetection3D 的官方可视化文档中我们已经提供了如何进行可视化的一些指令和效果,这篇文章我们将从代码层级介绍可视化的细节过程,带大家一探究竟。

可视化代码解析
在线可视化 Visualizer
MMDetection3D 基于 Open3D 构建了一个在线 Visualizer,用于在有 GUI 界面的情况下提供实时可视化结果,Open3D 提供了非常丰富的功能。相关代码位于 mmdet3d/core/visualizer/open3d_vis.py 。
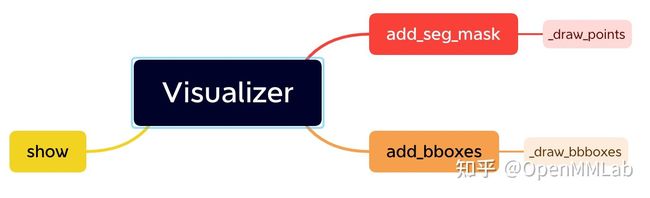
MMDetection3D 目前只使用了 Open3D 的部分 API 进行可视化,同时也非常容易实现可视化功能的扩展,目前 Visualizer 支持绘制 3D 框的 add_bboxes,绘制点云分类结果的 add_seg_mask,以及统一的 show 显示方法。在这一节中我们不具体介绍 Open3D 的各个 API 的具体作用,而是带大家来看看如何使用 Open3D 的 API 完成需求,包括实现自己的自定义的可视化需求。
#---------------- mmdet3d/core/visualizer/open3d_vis.py ----------------#
class Visualizer(object):
r"""Online visualizer implemented with Open3d."""
def __init__(self,
points,
bbox3d=None,
save_path=None,
points_size=2,
point_color=(0.5, 0.5, 0.5),
bbox_color=(0, 1, 0),
points_in_box_color=(1, 0, 0),
rot_axis=2,
center_mode='lidar_bottom',
mode='xyz'):
super(Visualizer, self).__init__()
assert 0 <= rot_axis <= 2
# 调用 Open3D 的 API 来初始化 visualizer
self.o3d_visualizer = o3d.visualization.Visualizer()
self.o3d_visualizer.create_window()
# 创建坐标系帧
mesh_frame = geometry.TriangleMesh.create_coordinate_frame(
size=1, origin=[0, 0, 0])
self.o3d_visualizer.add_geometry(mesh_frame)
# 设定点云尺寸
self.points_size = points_size
# 设定点云颜色
self.point_color = point_color
# 设定 3D 框颜色
self.bbox_color = bbox_color
# 设定 3D 框内点云的颜色
self.points_in_box_color = points_in_box_color
self.rot_axis = rot_axis
self.center_mode = center_mode
self.mode = mode
self.seg_num = 0
# 绘制点云
if points is not None:
self.pcd, self.points_colors = _draw_points(
points, self.o3d_visualizer, points_size, point_color, mode)
def add_bboxes(self, bbox3d, bbox_color=None, points_in_box_color=None):
"""Add bounding box to visualizer."""
if bbox_color is None:
bbox_color = self.bbox_color
if points_in_box_color is None:
points_in_box_color = self.points_in_box_color
_draw_bboxes(bbox3d, self.o3d_visualizer, self.points_colors, self.pcd,
bbox_color, points_in_box_color, self.rot_axis,
self.center_mode, self.mode)
def add_seg_mask(self, seg_mask_colors):
"""Add segmentation mask to visualizer via per-point colorization."""
self.seg_num += 1
offset = (np.array(self.pcd.points).max(0) -
np.array(self.pcd.points).min(0))[0] * 1.2 * self.seg_num
mesh_frame = geometry.TriangleMesh.create_coordinate_frame(
size=1, origin=[offset, 0, 0]) # create coordinate frame for seg
self.o3d_visualizer.add_geometry(mesh_frame)
seg_points = copy.deepcopy(seg_mask_colors)
seg_points[:, 0] += offset
_draw_points(
seg_points, self.o3d_visualizer, self.points_size, mode='xyzrgb')
def show(self, save_path=None):
"""Visualize the points cloud."""
self.o3d_visualizer.run()
if save_path is not None:
self.o3d_visualizer.capture_screen_image(save_path)
self.o3d_visualizer.destroy_window()
return 如上述代码所示,在检测任务中,关于 3D 框的绘制主要是通过调用 add_bboxes 方法,我们可以在绘制 3D 框的时候,通过 bbox_color 和 points_in_box_color 分别设定框的颜色以及包含在框内的点云的颜色,而其最终调用的还是 _draw_bboxes 方法。而 add_seg_masks 则是用来绘制分割结果,其中传入的 seg_mask_colors 是带颜色 (rgb) 信息的点云。需要注意的是,我们在绘制点云分割结果的时候,不会在原点云上进行颜色的更新,因为如果同时在原点云上绘制预测结果和真值标签往往会有重叠现象,所以我们对每一个分割结果的点云图都会沿 x 轴设置较大的偏移量,单个场景会生成多个分割结果图,而最终对每个分割结果图都会调用 _draw_points 方法进行绘制。当完成所有的绘制之后,就可以调用 show 方法启动 Visualizer,显示场景绘制结果。除此以外,我们也可以很轻松地通过给 Visualizer 添加方法实现自己的需求。
我们可以先来看看如何绘制点云:
#---------------- mmdet3d/core/visualizer/open3d_vis.py ----------------#
import open3d as o3d
from open3d import geometry
def _draw_points(points,
vis,
points_size=2,
point_color=(0.5, 0.5, 0.5),
mode='xyz'):
# 获取 Open3D Visualizer 的渲染设置,更改点云尺寸
vis.get_render_option().point_size = points_size
if isinstance(points, torch.Tensor):
points = points.cpu().numpy()
points = points.copy()
# 构建 Open3D 中提供的 gemoetry 点云类
pcd = geometry.PointCloud()
# 如果传入的点云 points 只包含位置信息 xyz
# 根据指定的 point_color 为每个点云赋予相同的颜色
if mode == 'xyz':
pcd.points = o3d.utility.Vector3dVector(points[:, :3])
points_colors = np.tile(np.array(point_color), (points.shape[0], 1))
# 如果传入的点云 points 本身还包含颜色信息(通常是分类预测结果或者标签)
# 直接从 points 获取点云的颜色信息
elif mode == 'xyzrgb':
pcd.points = o3d.utility.Vector3dVector(points[:, :3])
points_colors = points[:, 3:6]
# 将颜色归一化到 [0, 1] 用于 Open3D 绘制
if not ((points_colors >= 0.0) & (points_colors <= 1.0)).all():
points_colors /= 255.0
else:
raise NotImplementedError
# 为点云着色
pcd.colors = o3d.utility.Vector3dVector(points_colors)
# 将点云加入到 Visualizer 中
vis.add_geometry(pcd)
return pcd, points_colors 以上就是绘制点云的过程,当我们了解了如何绘制点云后,我们就可以实现自己的需求了,比如有社区用户希望能够给点云的强度进行染色,当然我们可以直接加在 _draw_points 方法内,但是为了演示更清晰,这里我们可以在 Visiualizer 内实现一个 render_points_intensity 方法做演示:
#---------------- mmdet3d/core/visualizer/open3d_vis.py ----------------#
import open3d as o3d
from open3d import geometry
def render_points_intensity(self, points, vis):
# 假设传入的 points 包含 x-y-z-intensity 四个维度
# 自定义一个 colormap
colormap = np.array([[128, 130, 120],
[235, 0, 205],
[0, 215, 0],
[235, 155, 0]]) / 255.0
points = points.copy()
# 构建 Open3D 中提供的 gemoetry 点云类
pcd = geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(points[:, :3])
points_intensity = points[:, 3] # intensity
points_colors = [colormap[int(points_intensity[i]) % colormap.shape[0]] for i in range(points_intensity.shape[0])]
pcd.colors = o3d.utility.Vector3dVector(points_colors) # 根据 intensity 为点云着色
# 将点云加入到 Visualizer 中
vis.add_geometry(pcd)
还有比如在社区用户的反馈中,想在可视化时调整场景的背景颜色,我们可以很简单地添加一个 change_bg_color 方法:
def change_bg_color(self, bg_colors):
"""Change back ground color of Visualizer"""
# 获取渲染配置
opt = self.o3d_visualizer.get_render_option()
# 将场景背景颜色设为指定颜色
opt.background_color = bg_colors
接下来我们具体来看看如何在点云中绘制 3D 框 _draw_bboxes:
#---------------- mmdet3d/core/visualizer/open3d_vis.py ----------------#
def _draw_bboxes(bbox3d,
vis,
points_colors,
pcd=None,
bbox_color=(0, 1, 0),
points_in_box_color=(1, 0, 0),
rot_axis=2,
center_mode='lidar_bottom',
mode='xyz'):
in_box_color = np.array(points_in_box_color)
for i in range(len(bbox3d)):
center = bbox3d[i, 0:3]
dim = bbox3d[i, 3:6]
yaw = np.zeros(3)
yaw[rot_axis] = -bbox3d[i, 6]
# 在 Open3D 中需要将 yaw 朝向角转为旋转矩阵
rot_mat = geometry.get_rotation_matrix_from_xyz(yaw)
# 底部中心点转为几何中心店
if center_mode == 'lidar_bottom':
center[rot_axis] += dim[
rot_axis] / 2
elif center_mode == 'camera_bottom':
center[rot_axis] -= dim[
rot_axis] / 2
box3d = geometry.OrientedBoundingBox(center, rot_mat, dim)
line_set = geometry.LineSet.create_from_oriented_bounding_box(box3d)
line_set.paint_uniform_color(bbox_color)
# 在 Visualizer 中绘制 Box
vis.add_geometry(line_set)
# 更改 3D Box 中的点云颜色
if pcd is not None and mode == 'xyz':
indices = box3d.get_point_indices_within_bounding_box(pcd.points)
points_colors[indices] = in_box_color
# 更新点云颜色
if pcd is not None:
pcd.colors = o3d.utility.Vector3dVector(points_colors)
vis.update_geometry(pcd) 需要注意 MMDetection3D 中在 3D 视角可视化时的 bbox3d 是 (x, y, z, x_size, y_size, z_size, yaw) 格式的,同时在 3D 视角可视化的时候都是会被转换到深度坐标系,而且 x, y, z 表示的是底部中心点位置,而并不是几何中心点位置。所以在用 Open3D 可视化的时候需要从底部中心点转换为几何中心点。
使用 MeshLab 可视化
对于 MeshLab 来说,可视化需要提供相应的 obj 文件,文件内包含点云信息、分割结果、检测结果等等。而在目前 MMDetection3D 中,我们提供下述方法,可以将模型输出结果转换为 obj 文件。
#---------------- mmdet3d/core/visualizer/show_result.py ----------------#
def _write_obj(points, out_filename):
"""Write points into ``obj`` format for meshlab visualization."""
N = points.shape[0]
fout = open(out_filename, 'w')
# 保存点云的时候如果有颜色信息也会进行保存
for i in range(N):
if points.shape[1] == 6:
c = points[i, 3:].astype(int)
fout.write(
'v %f %f %f %d %d %d\n' %
(points[i, 0], points[i, 1], points[i, 2], c[0], c[1], c[2]))
else:
fout.write('v %f %f %f\n' %
(points[i, 0], points[i, 1], points[i, 2]))
fout.close()
def _write_oriented_bbox(scene_bbox, out_filename):
"""Export oriented (around Z axis) scene bbox to meshes."""
def heading2rotmat(heading_angle):
rotmat = np.zeros((3, 3))
rotmat[2, 2] = 1
cosval = np.cos(heading_angle)
sinval = np.sin(heading_angle)
rotmat[0:2, 0:2] = np.array([[cosval, -sinval], [sinval, cosval]])
return rotmat
# 将 MMDetection3D 内部格式的 3D 框转换为 trimesh 格式
def convert_oriented_box_to_trimesh_fmt(box):
ctr = box[:3]
lengths = box[3:6]
trns = np.eye(4)
trns[0:3, 3] = ctr
trns[3, 3] = 1.0
trns[0:3, 0:3] = heading2rotmat(box[6])
box_trimesh_fmt = trimesh.creation.box(lengths, trns)
return box_trimesh_fmt
if len(scene_bbox) == 0:
scene_bbox = np.zeros((1, 7))
# 利用 trimesh 构建场景
scene = trimesh.scene.Scene()
for box in scene_bbox:
scene.add_geometry(convert_oriented_box_to_trimesh_fmt(box))
mesh_list = trimesh.util.concatenate(scene.dump())
# 保存为 obj 文件
trimesh.io.export.export_mesh(mesh_list, out_filename, file_type='obj')
return _write_points 和 _write_oriented_bbox 分别用来保存点云(及其分割结果)和 3D Box 为 obj 文件,在实际使用的时候只需要将生成的 obj 文件导入到 MeshLab 即可。
可视化三件套

可视化本身依赖于 Open3D 和 MeshLab,前面介绍了如果将模型输出结果分别转换到 Open3D 和 MeshLab 需要的格式或者文件。而 MMDetection3D 则根据可视化任务需求封装了三种可视化方法,分别是 show_result 可视化点云场景 3D 框、show_seg_result 可视化点云 3D 分割结果、show_multi_modality_result 将 3D 框投影到 2D 图像进行可视化,这三个方法我们可以称之为【可视化三件套】,因为其实在大部分场景下,都是在使用这三种方法,这一点我们看后续的内容就会有体会了。相关代码见 mmdet3d/core/visualizer/show_result.py。
点云场景 3D 框可视化 show_result

show_result 本质就是调用 Visualizer 进行可视化,同时生成可以导入 MeshLab 的 obj 结果文件。我们只需要提供点云数据 points、预测 3D 框 pred_bboxes 和 3D 框 label gt_bboxes 即可,这里需要注意的是这三者都是可选的,并不一定必须提供,此外提供的 3D 框必须是在深度坐标系下。
![]()
点云场景分割可视化 show_seg_result
和 show_result 类似,本质也是调用 Visualizer 进行可视化,同时生成可以导入 MeshLab 的结果文件。

图片 3D 框投影可视化 show_multi_modality_result
与前两者不同,现在 3D 视角进行可视化需要借助 Open3D 或者 MeshLab 辅助显示,而 3D 框投影可视化本质和 2D 检测可视化是相同的,都是在图片上进行绘制。此种情况下不需要将 3D 框转换到深度坐标系,我们为不同坐标系的 3D 框分别进行相应的投影操作,在draw_depth_bbox3d_on_img、draw_lidar_bbox3d_on_img 和 draw_camera_bbox3d_on_img 中实现。

#---------------- mmdet3d/core/visualizer/show_result.py ----------------#
def show_multi_modality_result(img,
gt_bboxes,
pred_bboxes,
proj_mat,
out_dir,
filename,
box_mode='lidar',
img_metas=None,
show=False,
gt_bbox_color=(61, 102, 255),
pred_bbox_color=(241, 101, 72)):
# 根据传入 3D 框所处的坐标系调用对应的投影方法,获取投影框
if box_mode == 'depth':
draw_bbox = draw_depth_bbox3d_on_img
elif box_mode == 'lidar':
draw_bbox = draw_lidar_bbox3d_on_img
elif box_mode == 'camera':
draw_bbox = draw_camera_bbox3d_on_img
else:
raise NotImplementedError(f'unsupported box mode {box_mode}')
result_path = osp.join(out_dir, filename)
mmcv.mkdir_or_exist(result_path)
if show:
show_img = img.copy()
if gt_bboxes is not None:
show_img = draw_bbox(
gt_bboxes, show_img, proj_mat, img_metas, color=gt_bbox_color)
if pred_bboxes is not None:
show_img = draw_bbox(
pred_bboxes,
show_img,
proj_mat,
img_metas,
color=pred_bbox_color)
mmcv.imshow(show_img, win_name='project_bbox3d_img', wait_time=0)
if img is not None:
mmcv.imwrite(img, osp.join(result_path, f'{filename}_img.png'))
if gt_bboxes is not None:
gt_img = draw_bbox(
gt_bboxes, img, proj_mat, img_metas, color=gt_bbox_color)
mmcv.imwrite(gt_img, osp.join(result_path, f'{filename}_gt.png'))
if pred_bboxes is not None:
pred_img = draw_bbox(
pred_bboxes, img, proj_mat, img_metas, color=pred_bbox_color)
mmcv.imwrite(pred_img, osp.join(result_path, f'{filename}_pred.png')) 不同需求场景的可视化
刚才我们介绍了【可视化三件套】,现在我们就来看看 MMDetection3D 如何使用这三件套。实际上在 MMDetection3D 中存在多种可视化的需求场景,而各种需求在我们官方的文档也有相关运行命令的介绍:

Demo 可视化
在 demo 可视化的时候,通过使用训练好的模型得到推理结果后,直接根据需要使用可视化三件套。这种情况下通常输入是某个点云场景 bin 文件或者一张图片。
推理过程中可视化
对于某个模型,在某个数据集的验证集/测试集推理的时候可视化推理结果,调用的是该模型内部实现的 model.show_results 方法,在 MMDetection3D 中,我们为三种模型的基类分别实现了相应的可视化方法 show_results。
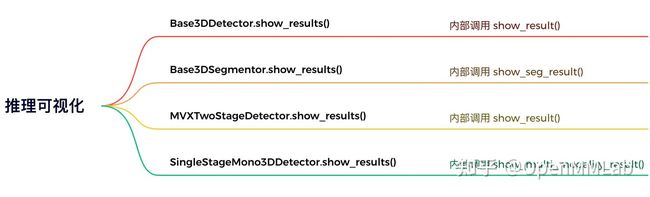
点云 3D 检测(多模态 3D 检测)模型推理的时候,其可视化方法 show_results 调用的是三件套中的 show_result,点云分割模型调用的则是 show_seg_result,单目 3D 检测模型调用的是 show_multi_modality_result。同时这些检测模型的 model.show_results 方法基本都提供了 score_thr 参数,用户可以更改该参数调整推理结果可视化时的检测框的阈值,获得更好的可视化效果。
结果可视化
MMDetection3D 提供了 tools/misc/visualize_results.py 脚本,用于可视化检测结果。通常来说,模型完成测试集/验证集的推理后,通常会生成保存检测结果的 pkl 格式的文件,该 pkl 文件的内部的具体存储格式则因数据集而异,所以通常对于每个数据集类,也会实现对应的 dataset.show 方法,我们可以来看看 KITTI 数据集:
# -------------- mmdet3d/datasets/kitti_dataset.py ----------------- #
def show(self, results, out_dir, show=True, pipeline=None):
assert out_dir is not None, 'Expect out_dir, got none.'
pipeline = self._get_pipeline(pipeline)
for i, result in enumerate(results):
if 'pts_bbox' in result.keys():
result = result['pts_bbox']
data_info = self.data_infos[i]
pts_path = data_info['point_cloud']['velodyne_path']
file_name = osp.split(pts_path)[-1].split('.')[0]
points, img_metas, img = self._extract_data(
i, pipeline, ['points', 'img_metas', 'img'])
points = points.numpy()
# 在 3D 空间可视化的时候需要将 3D 框转换到深度坐标系
points = Coord3DMode.convert_point(points, Coord3DMode.LIDAR,
Coord3DMode.DEPTH)
gt_bboxes = self.get_ann_info(i)['gt_bboxes_3d'].tensor.numpy()
show_gt_bboxes = Box3DMode.convert(gt_bboxes, Box3DMode.LIDAR,
Box3DMode.DEPTH)
pred_bboxes = result['boxes_3d'].tensor.numpy()
show_pred_bboxes = Box3DMode.convert(pred_bboxes, Box3DMode.LIDAR,
Box3DMode.DEPTH)
show_result(points, show_gt_bboxes, show_pred_bboxes, out_dir,
file_name, show)
# 多模态可视化, 在图片上可视化投影 3D 框
if self.modality['use_camera'] and 'lidar2img' in img_metas.keys():
img = img.numpy()
img = img.transpose(1, 2, 0)
show_pred_bboxes = LiDARInstance3DBoxes(
pred_bboxes, origin=(0.5, 0.5, 0))
show_gt_bboxes = LiDARInstance3DBoxes(
gt_bboxes, origin=(0.5, 0.5, 0))
show_multi_modality_result(
img,
show_gt_bboxes,
show_pred_bboxes,
img_metas['lidar2img'],
out_dir,
file_name,
box_mode='lidar',
show=show) 由于 pkl 文件只会保存检测到的 3D 框的信息,所以我们需要借助于数据集本身通过 pipeline 的方式获取点云(或者图片信息),如果数据集载入了图片信息,即 self.modality['use_camera'] 为 True,同时数据集本身的 meta info 包含 lidar2img 的投影矩阵,就可以将点云模型检测得到的结果投影到 2D 图片上可视化投影框。除此以外,由于调用了 show_result 方法,如果有 GIU 界面可以选择使用 Visualizer 可视化结果,同时会生成 obj 文件,从而导入 MeshLab 进行可视化。
数据集及标签可视化
训练自己的数据集时,怎么查看自己的数据和标签 box 是不是对应的?某一天突发奇想:想试试看一个新的数据增强方法能不能涨点,那怎么可以方便地验证这个数据增强的 pipeline 写得对不对呢? 在训练过程中我喂给模型的数据到底长什么样子呢?
MMDetection3D 提供 tools/misc/browse_dataset.py 脚本,browse_dataset 可以对 datasets 吐出的数据进行可视化检查,看下是否有错误。用法其实非常的简单,只需要传入数据集配置相关的 config 就可以了。而在具体的实现过程中,browse_dataset 脚本本身也是直接调用的可视化三件套,根据需求进行可视化,这里我们截取部分代码分析:
# -------------- tools/misc/browse_dataset.py ----------------- #
# 设定可视化 mode
vis_task = args.task # 'det', 'seg', 'multi_modality-det', 'mono-det'
progress_bar = mmcv.ProgressBar(len(dataset))
for input in dataset:
if vis_task in ['det', 'multi_modality-det']:
# show 3D bboxes on 3D point clouds
show_det_data(input, args.output_dir, show=args.online)
if vis_task in ['multi_modality-det', 'mono-det']:
# project 3D bboxes to 2D image
show_proj_bbox_img(
input,
args.output_dir,
show=args.online,
is_nus_mono=(dataset_type == 'NuScenesMonoDataset'))
elif vis_task in ['seg']:
# show 3D segmentation mask on 3D point clouds
show_seg_data(input, args.output_dir, show=args.online)
progress_bar.update() 我们在可视化数据集的时候需要在命令行指定 task,包括 det、multi_modality-det、mono-det、seg 四种。
To Do 项
MMDetection3D 在设计可视化工具的过程中,主要是满足各个任务和模态可视化的基本需求进行统一。而在实际使用的过程中,往往会有一些更加有趣的可视化需求,这里我们尝试提出一些可行的方案,也欢迎感兴趣的小伙伴贡献自己的力量,让 MMDetection3D 可视化功能越来越强大 ~
特征图注意力可视化
对于单目 3D 检测来说,其特征图可视化基本可以参照 MMDetection,对于点云 3D 检测来说,大部分的可视化需求集中在 voxel 上,每个 voxel 需要跟其他的 voxel 计算相似度,本质上是 self-attention,如果想在 MMDetection3D 通过 MMCV 的 hook 机制进行中间结果的可视化目前来说并不容易,MMCV 提供的高级 hook 只能在迭代或者训练 epoch 之前或之后调用,如果要可视化内部特征图而不是最终输出,则可能需要修改模型的 forward 方法以返回特征图,然后使用 MMCV 中的 hook。
推理过程中多模态可视化
MMDetection3D 已经在数据集 / 推理结果可视化中支持了多模态可视化(即 3D 框同时在点云空间和对应的图片上投影可视化),而前面提到过推理过程中的可视化主要依靠的是对应模型的 model.show_results 方法,我们只需要重写模型的 show_results 方法即可,具体的写法和前面的结果可视化中多模态可视化方法类似。对于点云 3D 检测模型,我们可以将模型检测的结果投影到图片上,相反,对于单目 3D 检测模型,我们则可以将由图片得到的检测结果直接在对应的点云场景中可视化。需要注意的是,在进行多模态可视化的时候,以经典多模态检测方法 MVXNet 为例,config 文件中关于 input_modality 需要进行如下设置:
input_modality = dict(use_lidar=True, use_camera=True) 3D 框 BEV XYWHR 视角可视化
MMDetection3D 目前并不支持 BEV 视角可视化,如果希望在 BEV 视角可视化使用 nuScenes devkit,当然我们也非常希望社区用户参与进来,参考 nuScenes devkit 的实现让 MMDetection3D 也能支持 BEV 视角可视化 ~~
综上,我们从代码层面介绍了一些 MMDetection3D 中可视化的相关内容,同时也带大家看看如何利用 Open3D 来满足更多的可视化需求。MMDetection3D 之后也会进行可视化代码的相关重构,更多的可视化后端比如 mayavi 和 wandb 等等也会在考虑范围内。接下来的文章我们会带大家仔细了解各个数据集,看看 MMDetection3D 中如何进行各个数据的预处理等等,敬请期待~
看到这里,小伙伴们是不是很想亲自体验 MMDetection3D 的强大功能呢?戳下方链接赶紧体验起来叭~
https://github.com/open-mmlab/mmdetection3dgithub.com/open-mmlab/mmdetection3d