Multi-Modal 3D Object Detection in Autonomous Driving: a Survey(自动驾驶中的多模态3D目标检测综述)论文笔记
原文链接:https://arxiv.org/pdf/2106.12735.pdf
1.引言
1.1 单一传感器3D目标检测
基于图像的3D目标检测。低费用换来满意的性能。但存在遮挡、高计算成本、易受极端天气影响等问题。
基于激光雷达的3D目标检测。激光雷达提供更丰富的几何信息,性能比图像好;但其昂贵而笨重、分辨率和刷新率低、有效范围小(远处点极为稀疏)、极端天气下不能工作。
基于其他传感器的3D目标检测。雷达提供速度、测量距离远、便宜、不受天气影响,但数据集少、稀疏、易受反射影响、难以获得上下文感知信息和形状信息;红外摄像机不易受环境影响、测量距离远、便宜。
1.2 多模态融合的3D目标检测
多传感器在时间和空间上都是不同步的。时间上,各传感器采样周期不同;空间上,各传感器朝向角度不同。此外,进行多模态融合时,还要考虑其他问题:
(1)多传感器对准和数据对齐;
(2)信息损失:减小计算量时不可避免;
(3)跨模态数据增广:数据增广用于减轻因为训练数据不足引起的过拟合;
(4)数据集和评价指标:目前缺少大型公开、类间平衡、标注准确的多模态数据集;不存在专门评价多模态融合有效性的指标。
2.背景
2.1 摄像机3D目标检测
摄像机分类:(1)单目相机能反映形状和纹理,有利于车道和路标检测,但缺少深度信息;(2)立体相机有更高的点密度,提供密集深度图;多视角相机提供多个视角的图像和更精确的深度图,但费用和计算量会很高。(3)ToF摄像机通过测量红外线发射-接收时间差来估计深度,精度、价格和计算量都低于立体相机。
早期使用定向梯度直方图(HOG)或局部二值模式(LBP)来提取特征,后来使用CNN网络。
三种RGB图像表达方法:

(1)特征图(激活图)是图像在给定滤波器时各像素的激活值,即卷积层的输出;

(2)掩膜(mask):语义分割时使用;

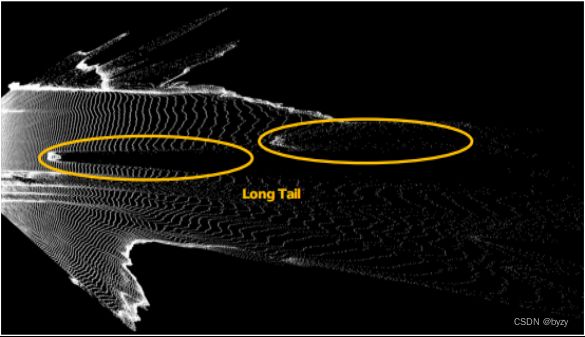
(3)伪激光雷达:估计深度图后将图像投影到3D空间,按照处理激光雷达的方法处理。点比分辨率最高的激光雷达点云仍高一个数量级,但由于深度估计误差存在长尾问题。
2.2 激光雷达3D目标检测
激光雷达可获得全方位的环境信息;因其主动性,可以提供更可靠的检测;费用高。
三种表达:(1)体素:可以用3D CNN处理,但存在信息损失、空体素、3D卷积效率低的问题。(2)点:保留更多信息,但通常计算昂贵。(3)视图:投影到2D平面,使用高效的2D CNN处理。鸟瞰图(BEV)物体无遮挡,物体有尺度不变性,但投影损失信息;range view(RV)是激光雷达的自然表达,无信息损失;密集紧凑性使其适合2D CNN,但没有物体尺度不变性。
处理方法:
(1)体素:3D CNN耗时,且不能抓取多尺度局部特征。
VoxelNet抓取有判别力的体素特征来加速;SECOND使用稀疏卷积进一步减少耗时。
体素方法由于其量化误差,性能存在上限。
(2)点:使用PointNet和PointNet++等方法提取空间几何特征。
PV-RCNN(属于点与体素表达融合方法)使用稀疏卷积和体素SA层学习强力特征。
激光雷达点数多,处理耗时,一般先下采样。
(3)视图:
PointPillars将3D点云转化为柱体的集合,加速训练。
2.3 雷达3D目标检测
雷达便宜且对极端天气鲁棒,可以测量速度。小巧轻便、空间分辨率高、抗干扰能力强。
雷达输出有3种层次:时间-频率谱的原始数据;对原始数据应用聚类算法得到的簇;对簇使用目标跟踪算法得到的轨迹。从前往后数据稀疏性和抽象性依次增加。对原始雷达数据使用2次FFT可以得到距离-角度热图,热图中信号强的位置有物体的概率高。
相比激光雷达,雷达点云噪声更多、更不精确,所以不能直接用激光雷达处理方法。
2.4 讨论
激光雷达3D目标检测比图像更精确,但点云缺少对分类重要的纹理信息;距离远时激光雷达密度低。需要多传感器融合。
3.数据集
- KITTI,评价指标mAP。
- nuScenes,评价指标NDS,是mAP和各种误差的加权平均,其中mAP阈值基于边界框的中心误差计算,各种误差包括平移、尺寸、朝向、速度和其他属性的误差。
- Waymo,评价指标APH,类似AP的计算,但考虑了边界框的朝向精度。支持domain adaptation,即从一个domain中学习,然后转移到另一个domain。可以解决昂贵的标注问题。
目前的3D数据集存在规模小、类间不平衡的问题。
4.多模态3D目标检测网络
考虑3个融合因素:融合位置(特征融合和决策融合)、融合输入(数据表达)和融合粒度。
4.1 特征融合
特征融合层次性地融合多模态特征用于预测结果;多模态数据通过各自的特征提取网络得到特征,融合后通过神经网络输出检测结果。

4.1.1 融合输入表达
(1)点云视图&图像特征图:
- MV3D:输入点云BEV、前视图FV以及图像特征图,使用3D提案网络生成3D提案。通过RoI池化操作将不同视图的提案和特征调整为相同大小并整合。
- SCANet:输入BEV到编码-解码提案网络,使用空间-通道注意力抓取不同尺度的空间上下文信息,使用扩展空间上采样恢复空间信息。
- AVOD:裁剪缩放BEV和图像后抓取特征并融合。证明了BEV和图像足以解释3D空间信息。
- FuseSeg:使用RV和点云-图像校准来建立点和像素的关系,利用两个模态的信息检测。
(2) 点云体素&图像特征图:
- Contfuse:将图像特征从前视图(FV)转换到BEV,然后使用连续卷积来融合BEV图像特征和点云体素。
- MVX-Net:将VoxelNet产生的非空体素特征投影到图像,然后使用预训练的网络为被投影体素提取图像特征。然后图像特征与体素特征拼接以获取更精确的3D边界框。该方法有效利用了多模态信息,减小了FP和FN。
- MoCa:通过剪切点云和图像中的物体作为patch,并(无重叠地)粘贴到不同场景中,提升了MVX-Net的性能。
- PointAugmenting:使用预训练的2D检测模型提取逐点CNN特征,装饰相应的点云;此外occlusion-aware的点滤波算法在训练阶段将虚拟物体粘贴到图像和点云中,这也提高了性能。
- 3D-CVF:使用空间attention map来根据每个模态对检测的贡献来加权它们。带注意力的逐体素融合生成了相机-激光雷达的强联合特征,进一步减少了信息损失。但仍存在不可忽视的量化误差。
(3)激光雷达点&图像特征图:
早期方法使用粗粒度的RoI级融合。这些方法使用2D检测器生成2D区域提案,以减小3D目标检测器的RoI。通常假设一个种子区域只包含一个物体,因此级联网络受限于2D检测器的性能。
- PI-RCNN:迈出了逐点融合的第一步。该方法在点上直接使用连续卷积,并从图像特征图中检索含有更多语义信息的图像特征。
- LI融合层:使用点云特征估计相应图像特征的重要性,减少了遮挡和深度不确定性的影响。但由于相应于每个点的特征都是插值得到的,该方法受限于边缘特征模糊。也许可以使用2D语义分割替代2D特征提取来实现一一对应。
(4)激光雷达点&图像掩膜:
- IPOD:对图像进行语义分割,输出掩膜被投影到3D点云以区分前景和背景点。然后原始点云和前景点云被PointNet++分类和回归。虽然可以直接使用原始点云进行上述操作,但由于级联网络,召回率存在上限。
- PointPainting:逐点融合。将点云投影到图像上,将分割分数附加到原始激光雷达点上。缺点是大量点可能没有图像的相应像素(属于图像的被遮挡区域)。
(5)点云体素&图像掩膜:
- CenterPointV2:使用CenterPoint检测网络。点云被处理为体素,使用逐点融合策略为每个激光雷达点标注图像的实例分割结果(由Cascade RCNN产生)。还使用了翻转和旋转增广,并使用5个模型的集成来得到最终结果。
- HorizonLiDAR3D:改进了AFDet,组合5个激光雷达的点云以充分利用信息。该方法设计了更强的基于体素的网络,并使用密集化和point painting(将点云投影到图像,收集基于图像的感知信息,为点增加额外属性)增强点云。
(6)点云体素&点云视图&图像特征图:
不同的数据表达有不同的优势,如点云的不同视图有互补的特性。
- 可以使用注意力机制估计各视图的重要性,以实现自适应融合。
(7)点云体素&图像特征图&伪激光雷达:
- MMF:利用多重相关任务进行精确的3D目标检测。提出端到端可学习的结构,进行2D和3D目标检测、地面估计和深度补全。缺点是整个网络复杂而耗时。
4.1.2 融合粒度
包含RoI、逐体素、逐点和逐像素融合。
(1)RoI融合:
融合在RoI级别、通过如RoI池化等操作发生。另一操作是利用几何关系,从2D RoI得到3D棱台,然后使用3D检测器来处理棱台。RoI融合通常在提案细化前进行。
该融合方法粒度粗糙,不适合进行精细的检测(如图像的矩形RoI含有许多背景噪声,融合这些噪声不利于检测)。
(2)逐体素融合:
通常,体素化的点云数据被投影到图像平面,然后在2D RoI中进行特征提取,并体素级地拼接池化后的图像特征。
该方法存在“特征模糊”问题,即可能一个点关联多个图像像素或一个像素关联多个点。因此插值通常被用于对齐点云BEV和RGB特征图。
相比RoI融合,逐体素融合更精细,且可以为空体素整合图像信息。
(3)逐点融合:
使用已知的校准矩阵将3D点投影到图像上,然后使用预训练的2D CNN,并在点的级别上拼接图像特征或掩膜。该方法不会造成“特征模糊”。
通过融合图像的高级语义信息和点,可以解决图像和点云分辨率不匹配的问题。
逐点融合可以有效提高性能,但相比于逐体素融合存储消耗大,且图像和点云高度耦合。
(4)逐像素融合:
Range图像是旋转激光雷达在2D空间的自然表达,保留了所有信息。可以在2D平面上,将RGB图像与之逐像素地融合。可以使用2D CNN提取特征,然后实现像素之间的特征对齐。
注意range图像仍比RGB图像的分辨率低。
4.2 决策融合
决策融合组合各模态结果来产生最终结果。各模态被独立分开处理,然后进行融合。

决策融合可更好地利用现有模型处理每个模态。缺点是不能利用网络中间层的丰富特征。
- CLOCs:利用2D和3D检测结果中几何和语义的一致性,自动从训练数据中学习概率相关性。该方法将2D和3D提案编码为稀疏张量,并对非空元素使用2D CNN获取预测融合分数。
与特征融合相比,决策融合的pipeline更简单,无需处理对齐精度和视图差异问题。
4.3 摄像机-激光雷达融合方法总结
多模态方法在点云相对稀疏时更有用。
4.4 与其余传感器的融合
- 可将雷达检测结果投影到图像平面以促进遥远目标的检测。
- 可以使用雷达检测结果生成3D提案,然后投影到图像平面,联合进行2D目标检测和深度估计。
- CenterFusion:首先使用中心点检测网络在图像上检测目标(通过确定目标中心点实现),然后使用基于棱台的方法关联雷达检测结果与相应的目标中心点。
- RadarNet:使用特征融合方法学习雷达和激光雷达的联合表达,然后决策融合机制用于利用雷达的径向速度。
多个相同传感器数据的融合也是有用的。但目前多激光雷达融合方法都是简单的拼接点云(如HorizonLiDAR3D),而没有其余特殊处理。
5 开放性挑战和可能的解决方案
5.1 多传感器校准和数据对齐
5.1.1 多传感器校准
位于不同传感器坐标系中的多传感器数据需要对齐。对于激光雷达和摄像机,可以通过计算一个3D到2D的转换矩阵(基于相机和激光雷达的内外参)来建立前者到后者的映射。
传统校准方法使用校准目标来推导相机内外参。这种方法繁琐且有误差,且在初始校准后,汽车的振动可能导致误差随时间积累。可以将相机和激光雷达作为整体组装,最大程度地防止二者的相对位移。
另一方法是在线校准,可在无人干涉的情况下连续地自动校准各传感器。
5.1.2 数据对齐
激光雷达点位于连续的真实世界坐标系;图像像素位于离散的图像坐标系。激光雷达点与图像像素对齐时,总会存在量化误差。可以使用双线性插值提高性能。
不同场景下,点云和RGB图像有不同的重要性。例如黑暗条件下更需依赖激光雷达点云,遥远物体的检测更需依赖图像。因此最好的方法是根据场景动态加权,但目前的方法都没有这样做。
5.2 融合时的信息损失
信息损失主要取决于融合粒度,通常越细粒度的融合信息损失越小。
为促进融合性能,可以使用神经结构搜索(NAS)来确定神经元数量、层数和其他超参数的值。也可设计损失函数监督融合,例如EPNet中的CE损失用于促进分类分数和IoU的一致性。
5.3 多模态数据增广
对单一模态常用的数据增广对融合任务同样有效,包括物体剪切和粘贴、随机翻转、缩放、旋转等。但为了实现多模态数据增广,需要建立数据元素(如点和像素)之间的映射。
- 目前的方法中,有同时裁剪图像和点云的真实物体,然后一致地粘贴到其余场景中,防止多模态数据之间的不对准。
5.4 数据集和指标
5.4.1 数据集
目前的3D数据集存在规模小、类间不平衡、标注错误的问题。
可以使用弱监督或无监督融合方法来在大型无标签数据集上训练;也可生成合成数据集,但目前的工作均在图像领域,且合成数据集和真实世界的数据集之间存在domain gap。
5.4.2 指标
现有指标都基于最终检测性能,缺少明确评估多模态融合有效性的指标。需要关注:由融合引入的额外计算;网络鲁棒性(如基于概率的检测质量)以及key performance indicators。