keras快速入门——函数式(Functional)模型
Keras 函数式 API 是定义复杂模型(如多输出模型、有向无环图,或具有共享层的模型)的方法。
输入输出均为张量,以张量为参数,并返回一个张量
1.全连接网络中函数式模型
from keras.layers import Input, Dense
from keras.models import Model
# 这部分返回一个张量
inputs = Input(shape=(784,))
# 层的实例是可调用的,它以张量为参数,并且返回一个张量
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x)
# 这部分创建了一个包含输入层和三个全连接层的模型
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels) # 开始训练2.所有的模型都可调用,就像网络层一样
利用函数式 API,可以轻易地重用训练好的模型:可以将任何模型看作是一个层,然后通过传递一个张量来调用它。注意,在调用模型时,您不仅重用模型的结构,还重用了它的权重。
这种方式能允许我们快速创建可以处理序列输入的模型。只需一行代码,你就将图像分类模型转换为视频分类模型
from keras.layers import TimeDistributed
# 输入张量是 20 个时间步的序列,
# 每一个时间为一个 784 维的向量
input_sequences = Input(shape=(20, 784))
# 这部分将我们之前定义的模型应用于输入序列中的每个时间步。
# 之前定义的模型的输出是一个 10-way softmax,
# 因而下面的层的输出将是维度为 10 的 20 个向量的序列。
processed_sequences = TimeDistributed(model)(input_sequences)3.多输入多输出的函数式模型
我们试图预测 Twitter 上的一条新闻标题有多少转发和点赞数。模型的主要输入将是新闻标题本身,即一系列词语,但是为了增添趣味,我们的模型还添加了其他的辅助输入来接收额外的数据,例如新闻标题的发布的时间等。 该模型也将通过两个损失函数进行监督学习。较早地在模型中使用主损失函数,是深度学习模型的一个良好正则方法。
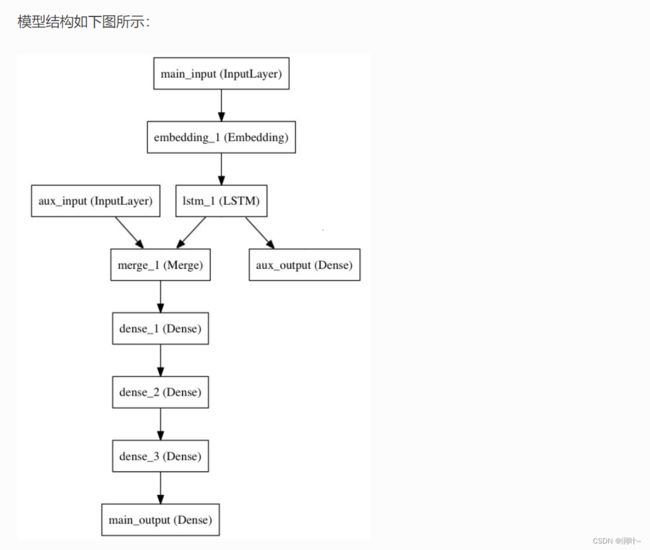
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model
#主要输入接收新闻标题本身,即一个整数序列(每个整数编码一个词)。
# 这些整数在 1 到 10,000 之间(10,000 个词的词汇表),且序列长度为 100 个词。
#标题输入:接收一个含有 100 个整数的序列,每个整数在 1 到 10000 之间。
# 注意我们可以通过传递一个 "name" 参数来命名任何层。
from tqdm import keras
main_input = Input(shape=(100,), dtype='int32', name='main_input')
# Embedding 层将输入序列编码为一个稠密向量的序列,
# 每个向量维度为 512。
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# LSTM 层把向量序列转换成单个向量,
# 它包含整个序列的上下文信息
lstm_out = LSTM(32)(x)
#在这里,我们插入辅助损失,
# 使得即使在模型主损失很高的情况下,LSTM 层和 Embedding 层都能被平稳地训练。
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
#此时,我们将辅助输入数据与 LSTM 层的输出连接起来,输入到模型中:
auxiliary_input = Input(shape=(5,), name='aux_input')
#############################多输入连接
x = keras.layers.concatenate([lstm_out, auxiliary_input])
# 堆叠多个全连接网络层
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# 最后添加主要的逻辑回归层
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
#然后定义一个具有两个输入和两个输出的模型:
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
#现在编译模型,并给辅助损失分配一个 0.2 的权重。如果要为不同的输出指定不同的 loss_weights 或 loss,可以使用列表或字典。
# 在这里,我们给 loss 参数传递单个损失函数,这个损失将用于所有的输出。
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2])
#我们可以通过传递输入数组和目标数组的列表来训练模型:
model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32)
#由于输入和输出均被命名了(在定义时传递了一个 name 参数)
# ,我们也可以通过以下方式编译模型:
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2})
# 然后使用以下方式训练:
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': labels, 'aux_output': labels},
epochs=50, batch_size=32)
4.共享视觉模型
该模型在两个输入上重复使用同一个图像处理模块,以判断两个 MNIST 数字是否为相同的数字
from keras.layers import Conv2D, MaxPooling2D, Input, Dense, Flatten
from keras.models import Model
# 首先,定义视觉模型
digit_input = Input(shape=(27, 27, 1))
x = Conv2D(64, (3, 3))(digit_input)
x = Conv2D(64, (3, 3))(x)
x = MaxPooling2D((2, 2))(x)
out = Flatten()(x)
vision_model = Model(digit_input, out)
# 然后,定义区分数字的模型
digit_a = Input(shape=(27, 27, 1))
digit_b = Input(shape=(27, 27, 1))
# 视觉模型将被共享,包括权重和其他所有
out_a = vision_model(digit_a)
out_b = vision_model(digit_b)
concatenated = keras.layers.concatenate([out_a, out_b])
out = Dense(1, activation='sigmoid')(concatenated)
classification_model = Model([digit_a, digit_b], out)5.视觉问答模型
当被问及关于图片的自然语言问题时,该模型可以选择正确的单词作答。
它通过将问题和图像编码成向量,然后连接两者,在上面训练一个逻辑回归,来从词汇表中挑选一个可能的单词作答。
from keras.layers import Conv2D, MaxPooling2D, Flatten
from keras.layers import Input, LSTM, Embedding, Dense
from keras.models import Model, Sequential
# 首先,让我们用 Sequential 来定义一个视觉模型。
# 这个模型会把一张图像编码为向量。
vision_model = Sequential()
vision_model.add(Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=(224, 224, 3)))
vision_model.add(Conv2D(64, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
vision_model.add(Conv2D(128, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
vision_model.add(Conv2D(256, (3, 3), activation='relu'))
vision_model.add(Conv2D(256, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Flatten())
# 现在让我们用视觉模型来得到一个输出张量:
image_input = Input(shape=(224, 224, 3))
encoded_image = vision_model(image_input)
# 接下来,定义一个语言模型来将问题编码成一个向量。
# 每个问题最长 100 个词,词的索引从 1 到 9999.
question_input = Input(shape=(100,), dtype='int32')
embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=100)(question_input)
encoded_question = LSTM(256)(embedded_question)
# 连接问题向量和图像向量:
merged = keras.layers.concatenate([encoded_question, encoded_image])
# 然后在上面训练一个 1000 词的逻辑回归模型:
output = Dense(1000, activation='softmax')(merged)
# 最终模型:
vqa_model = Model(inputs=[image_input, question_input], outputs=output)
# 下一步就是在真实数据上训练模型。