关系抽取(三)实体关系联合抽取:TPlinker
参考:
- NLP系列之封闭域联合抽取:CasRel、TPLinker、PRGC、PURE、OneRel,实在是太卷了! - 知乎 (zhihu.com)
- NLP 关系抽取 — 概念、入门、论文、总结
TPlinker
论文:PLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
代码:https://github.com/131250208/TPlinker-joint-extraction
论文解读(作者):关系重叠?实体嵌套?曝光偏差?这个模型统统都搞得定! (qq.com)
关系抽取之TPLinker解读加源码分析
TPLinker的创新
(1)TPLinker是一种关系抽取的新范
(2)TPLinker是单阶段抽取模型,
(3)TPLinker实体和关系公用同一个解码,同时避免偏差暴露,同时抽取实体和关系,并不是先抽实体再抽关系,累加实体抽取错误的误差,保证了训练和预测的一致性。
(4)TPLinker模型可以处理SingleEntityOverlap (SEO), and EntityPairOverlap (EPO) ,同时可以处理实体嵌套问题
基本思想
Pipeline 的方法一般先做实体识别,再对实体对进行关系分类。这类方法忽略了实体与关系之间的联系,而且存在误差累积的问题。
为了充分利用实体与关系的交互信息和依赖关系,联合抽取的思路应运而生,即在一个模型中同时对实体和关系进行统一抽取。较早的联合抽取方法,如 NovelTagging,没法解决关系重叠的问题。当一个或一对实体同时出现在多个关系时,单纯的序列标注就不再管用了,例如:
| 文本 |
关系 |
|
| 单实体重叠 |
周星驰主演了《喜剧之王》和《大话西游》。 |
(周星驰,演员,喜剧之王)(周星驰,演员,大话西游) |
| 实体对重叠 |
由周星驰导演并主演的《功夫》于近期上映。 |
(周星驰,演员,功夫)(周星驰,导演,功夫) |
后来提出的一些方法已经可以解决重叠问题,如 CopyRE、CopyMTL、CasRel(HBT)等,但它们在训练和推理阶段存在曝光偏差。即在训练阶段,使用了 golden truth 作为已知信息对训练过程进行引导,而在推理阶段只能依赖于预测结果。这导致中间步骤的输入信息来源于两个不同的分布,对性能有一定的影响。
虽然这些方法都是在一个模型中对实体和关系进行了联合抽取,但从某种意义上它们“退化”成了“pipeline”的方法,即在解码阶段需要分多步进行。这也是它们存在曝光偏差的本质原因。
TPLinker提出了一种新的实体关系联合抽取标注方案,可在一个模型中实现真正意义上的单阶段联合抽取,不存在曝光偏差,保证训练和测试的一致性。并且同时可解决多关系重叠和多关系实体嵌套的问题。
标注方案
具体的标注方案如下图所示:
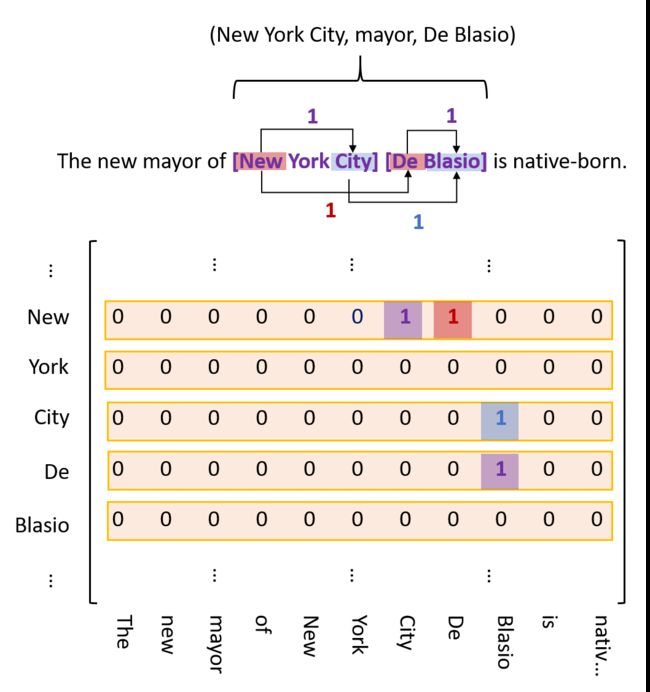
初始标注方案示例
其中紫色标签代表实体的头尾关系,红色标签代表 subject 和 object 的头部关系,蓝色标签代表 subject 和 object 的尾部关系。至于为什么用颜色区分,是因为这三种关系可能重叠,所以三种标签是存在于不同矩阵的,这里为了便于阐述,才放在一起。
因为实体尾部不可能出现在头部之前,所以紫色标签是不可能出现在下三角区的,那么这样标就有点浪费资源。能不能不要下三角区?但要注意到,红标和蓝标是会出现在下面的。所以我们把红蓝标映射到上三角区对应位置,并标记为 2,然后弃了下三角区,如下图:
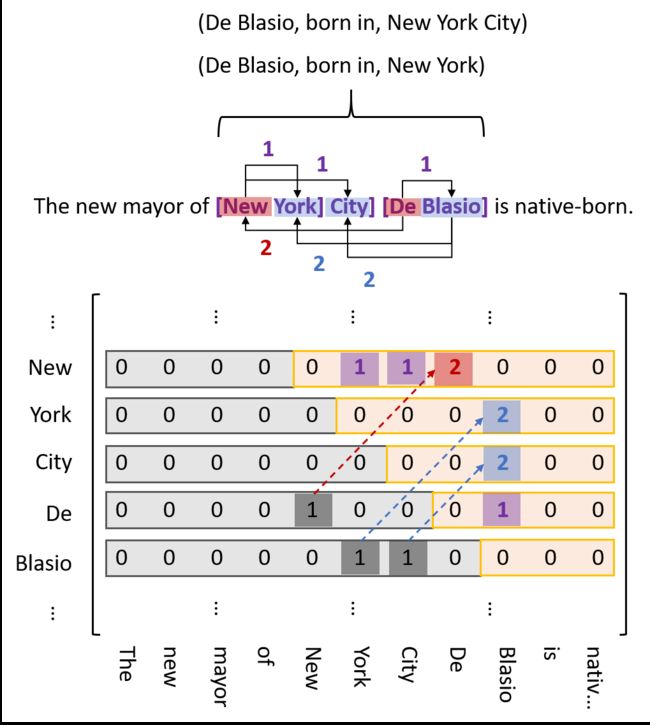
最终标注方案
模型框架
模型比较简单,整个句子过一遍 encoder,然后将 token 两两拼接输入到一个全连接层,再激活一下输出作为 token 对的向量表示,最后对 token 对进行分类即可。换句话说,这其实是一个较长序列的标注过程。
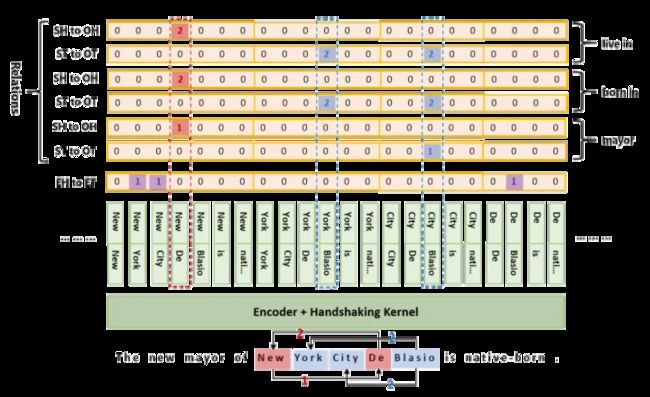
上图的例,可以解码出5种关系:
- (New York City, mayor, De Blasio),
- (De Blasio, born in, New York),
- (De Blasio, born in, New York City) ,
- (De Blasio, live in, New York),
- (De Blasio, live in, New York City)
解码
解码过程抽取出实体和实体间对应的关系,过程如下:
(1)构建实体EH-TO-ET字典D,其中字典D的key是实体头,value为实体
(2)解码ST-to-OT,构建字典E;再解码SH-to-OH且在字典D中尽可能查找满足实体头的所有实体subject和object
(3)验证上述找到的subject 和object实体对儿的尾部是否在E中,如果在E中,得到实体subject,objdect和关系三元组
handshaking decoder (tplinker plus)
解码过程包括抽取实体和关系,这里考虑了实体的type,解码过程如下:
(1) 根据handshaking kernel的结果得到所有handshaking tagging的结果,即[(start, end, idstag)]
(2) 根据得到的handshaking tagging的结果解码得到EH-TO-ET,即(entity_start, entity_end, entity_type),同时构建head_ind2entities字典,字典的key是entity_head index,value 是entity token span
(3) 根据得到的handshaking tagging的结果解码得到ST-TO-OT或者OT-TO-ST,即(sub_tail, obj_tail, rel_type)
(4) 根据handshaking tagging的结果解码得到SH-TO-OH,ST-TO-OT, sub_head, obj_head, rel_type,验证sub_head,obj_head是否在head_ind2entities中,如果sub_head, obj_head在head_ind2entities中,验证(sub_tail, obj_tail, rel_type)是否在(3)中的结果,如果在,则返回关系三元组。
实验
数据集
NYT 和 WebNLG,这两个数据集都给出了实体标记, 而关系,包括了普通关系 Normal,Entity Pair Overlap (EPO,多个subject对单个object),Single Entity Overlap (SEO,两个实体间存在多种关系) ,具体例子请看本文章中的第二张图。

实验结果
与各种模型作对比的主要成绩:

当输入的句子复杂度增加,各种模型的成绩呈下降趋势,然而 TPLinker 表现出显著的提高:

在计算性能上,TPLinker 也表现出巨大的优势:
