源码解读ReDet:A Rotation-equivariant Detector for Aerial Object Detection
文章目录
- 前言
- 1、解决的问题
- 2、模型结构
-
- 2.1.ReCNN
- 2.2. RiRoiAlign
- 总结
前言
本篇解读2021CVPR旋转目标检测论文:ReDet:A Rotation-equivariant Detector for Aerial Object Detection。附上地址和源码链接:
论文下载地址
源码地址
1、解决的问题
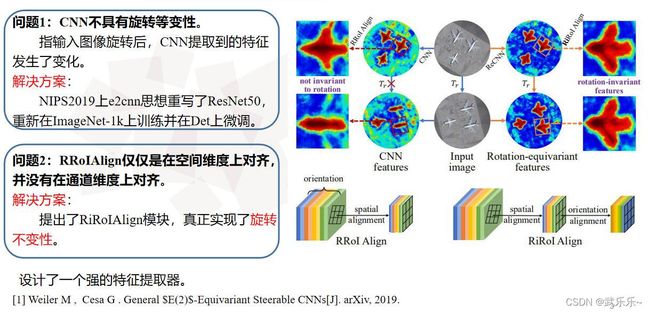
这是本人组会上做的ppt。简单说创新点有两个:
1)利用NIPS2019的e2cnn思想重写了ResNet50并命名为ReCNN,使得CNN具有旋转等变性。即当输入图像发生旋转时,CNN提取到的特征一样。
2)在经过e2cnn提取到图像的特征向量F(K*N,H,W)后,在通道维度上,可以理解为划分成N个组(N=4/8)代表4个方向或8个方向,而每组的子通道数为K。但RRoIAlign模块仅仅是对于不同朝向的物体在空间维度上进行了校正,但在通道维度上并不对齐,故作者设计了RiROIAlign模块在通道维度上和空间维度上均进行了对齐,从而得到了旋转不变性的特征。
总的来说:本文就是设计了一个非常强的特征提取器。
2、模型结构

2.1.ReCNN
这块我也不理解,e2cnn太硬核了。只是说下:作者在写好ReCNN后,在ImageNet上重新训练并在测试数据集上微调。(羡慕有能力训练Backbone的人)。
2.2. RiRoiAlign
在模型结构图中的意思是首先使用RRoiAlign模块进行了空间对齐,之后在循环交换各个通道,比如r=2,将Cn2通道值赋给Cn1,Cn1的值赋给Cnn…并在前后两个通道间执行双线性插值来计算当前通道像素值。(我在这里比较懵逼,所以去看了看源码)。源码位置:ReDet-master\mmdet\ops\riroi_align\src\riroi_align_kernel.cu。我尽量做到详细注释。不懂欢迎评论交流。
#include 从代码可看出,并不是作者论文中所说的先 空间对齐在通道对齐。 作者在实现上将二者结合起来,即确定通道位置的像素值之后顺便执行了RRoIAlign。
如果还是觉得蒙,我这里给出一个示例,自己手推了一下运行过程。也是ppt。
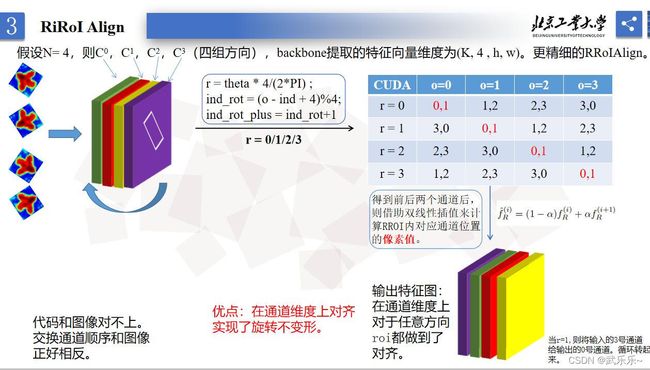
假设N=4,即划分成4组通道,对应代码中的nOrientation。r即ind,o代表池化后特征向量的通道下标。以表格为例,当r=1时,o=1时候,即将输入通道的0和1号通道像素值拿去做RiRoiAlign,并将计算得到像素值放到o=1号位置,即实现了通道对齐。就是循环编码过程。
总结
感觉RiRoiAlign本质上是让不同朝向的物体在通道维度上放到了一个相对的参考系下,让不同朝向的物体从自身角度看,通道位置和自身朝向始终对齐。从而实现了真正意义上旋转不变性。若有问题欢迎+vx:wulele2541612007,拉你进群探讨交流。