hive实现单词统计
一、前期准备
二、操作步骤
1.在hive下创建一个数据库
编辑
2. 在wordcount库下创建一个表
3. 在虚拟机上创建一个文件
4. 将在linux上创建的data文件,上传到新建的hive的worltest表中
5. 进入hive, 查询表wordtest信息
6. 新建一个wordtest1表,只有一列值,用来储存wordtest表数据中的内容
7. 将表wordtest中的数据存放进新建的表wordtest1中
编辑 8. 查询wordtest1表中的信息
9. 统计单词出现的个数
10. 查询将单词出现的次数按照降序排序
三、问题及解决
问题1.Error during job, obtaining debugging information..FAILED: Execution Error, return code 2 from org. apache , hadoop. hive. ql. exec . mr. MapRedTaskMapReduce Jobs Launched:Stage-Stage-l: HDFS Read: 0 HDFS Write: 0 FAILTotal MapReduce CPU Time Spent: 0 msec
问题2.我设置了本地模式之后启动hive然后进行增加,查询数据的时候又提示了无法分配内存
一、前期准备
1. 启动hadoop集群
2. 启动mysql
3. 启动hive
二、操作步骤
1.在hive下创建一个数据库
create database wordcount;
2. 在wordcount库下创建一个表
#使用数据库wordcount
use wordcount;
#创建一个表名字为 wordtest,其值有course1,course2
create table wordtest(course1 String, course2 String) row format delimited fields terminated by ',' stored as textfile;
#查询 wordcount数据库下拥有的表
show tables;


3. 在虚拟机上创建一个文件
#编辑一个文件,名字为data
vi data
#在文件中添加如下信息(自己任意添加一些信息即可,每行两个单词,单词之间用逗号隔开)
hadoop,hadoop
saprk,hadoop
kafka,flume
flume,kafka
spark,spark
mysql,tomcat
netcat,mysql
hive,scala
#注:因为我们刚才在hive下创建的表是之后course1,course2;两个属性,每个属性之间用,隔开,所以这里在data添加内容的时候,每一行有两个值,每个值之间用逗号隔开4. 将在linux上创建的data文件,上传到新建的hive的worltest表中
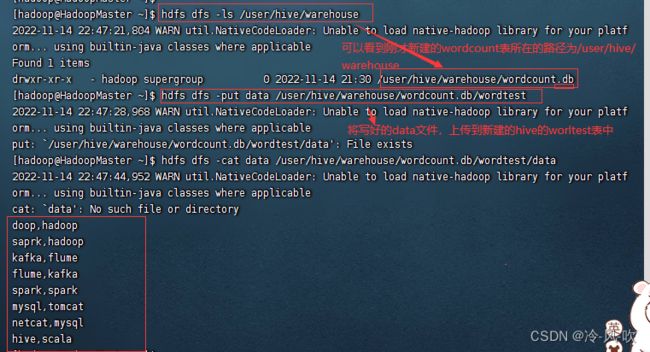
hdfs dfs -ls /user/hive/warehouse
可以看到刚才新建的wordcount表所在的路径为/user/hive/warehouse
#将写好的data文件,上传到新建的hive的worltest表中
hdfs dfs -put data /user/hive/warehouse/wordcount.db/wordtest
#查看数据
hdfs dfs -cat data /user/hive/warehouse/wordcount.db/wordtest/data
5. 进入hive, 查询表wordtest信息
#查询表中中的所有信息
select * from wordtest; 
6. 新建一个wordtest1表,只有一列值,用来储存wordtest表数据中的内容
#创建一个表wordtest1来储存wordtest里面原有的信息,以逗号问分隔符
create table wordcount.wordtest1(course String) row format delimited fields terminated by ','stored as textfile;
#查看wordcount数据库下边有哪些表
show tables;
7. 将表wordtest中的数据存放进新建的表wordtest1中
#将第一列的值储存到wordtest1表中
insert into wordtest1 select course1 from wordtest;#将第二列的值储存到wordtest1表中
insert into wordtest1 select course2 from wordtest;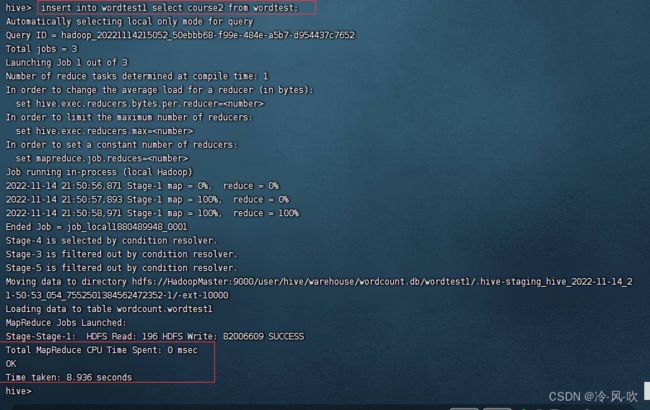 8. 查询wordtest1表中的信息
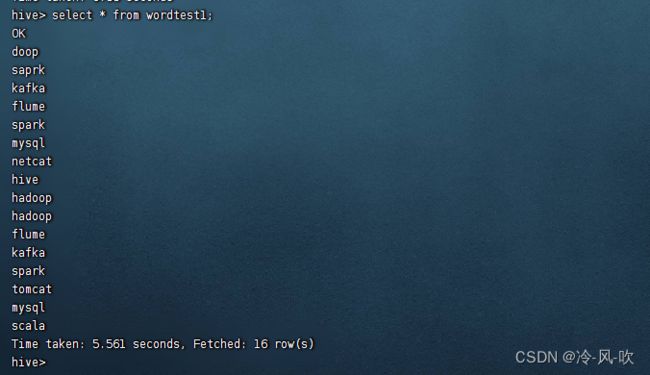
8. 查询wordtest1表中的信息
select * from wordtest1;
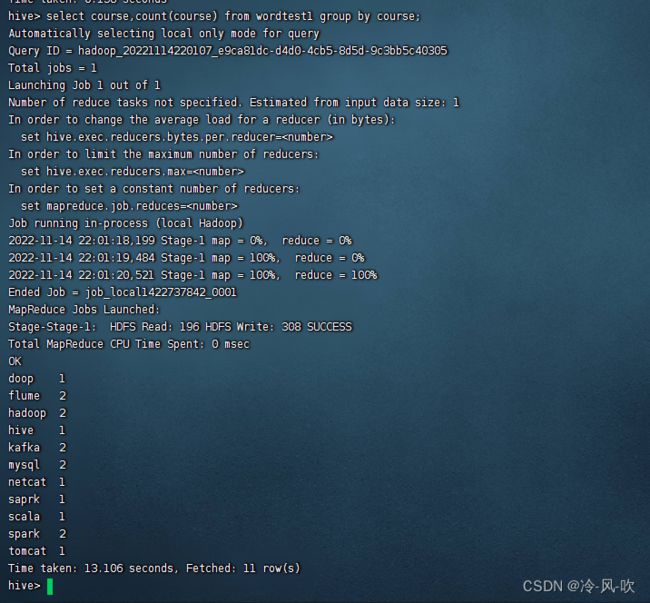
9. 统计单词出现的个数
select course,count(course) from wordtest1 group by course;
10. 查询将单词出现的次数按照降序排序
select course,count(course) as nu from wordtest1 group by course order by nu desc;
扩展小知识:
如果想要按照升序排序,则可以用asc 使用order by 进行排序的时候默认的是降序排序(desc)
升序:
select course,count(course) as nu from wordtest1 group by course order by nu asc;
如果只想查询前三个次数最多的单词,则可以用limit来进行限定
例如:
select course,count(course) as nu from wordtest1 group by course order by nu desc limit 3;
如果只想查询后三个次数最少的单词,则可以用limit来进行限定
select course,count(course) as nu from wordtest1 group by course order by nu asc limit 3;
三、问题及解决
问题1.Error during job, obtaining debugging information..
FAILED: Execution Error, return code 2 from org. apache , hadoop. hive. ql. exec . mr. MapRedTaskMapReduce Jobs Launched:
Stage-Stage-l: HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
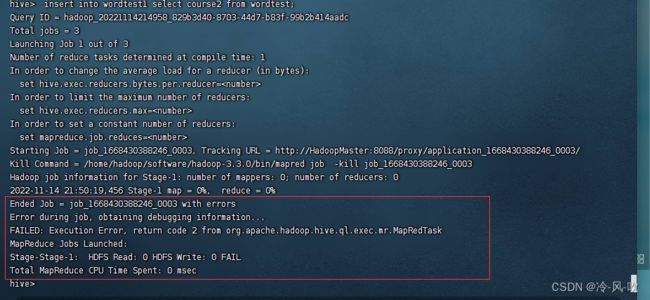
原因:namenode内存空间不够,jvm 剩余空间不够新的job运行导致的;
解决方法:将hive设置成本地模式来执行任务
1. 临时设置:
set hive.exec.mode.local.auto=true;这样设置比较麻烦,需要每次执行语句的时候输入这条命令,而且输一次命令只能执行一次语句,再次执行其他语句的时候就会提示进程被杀死。需要从新启动hive。每次都要重新启动一次hive然后在输一次这条语句比较麻烦。
2. 长远设置:
在hive-site.xml 文件添加配置
hive.exec.mode.local.auto
true
设置了之后从新启动hive就可以了。
问题2.我设置了本地模式之后启动hive然后进行增加,查询数据的时候又提示了无法分配内存
这里问题解决了忘记保存图片了。
解决方法:可以通过创建swap交换分区来解决内存分配不足问题
具体参考这篇文章
https://blog.csdn.net/m0_61232019/article/details/127618271?spm=1001.2014.3001.5502