动作识别最新高效利器 ACTION-Net:通用的多路径激活模块 | CVPR 2021
2021-04-20 01:48:02

本文是对我们 CVPR 2021 接收的工作 "ACTION-Net: Multipath Excitation for Action Recognition" 的介绍。主要针对强时序依赖行为识别这个场景,设计了一组卷积模块。

作者单位:都柏林圣三一大学,字节跳动
论文地址:
https://arxiv.org/abs/2103.07372
代码地址:
https://github.com/V-Sense/ACTION-Net
近年来,随着越来越多的大规模视频数据集的出现如Kinetics,Something-to-Someting,Jester,基于3D卷积的深度神经网络在视频动作识别上面取得了非常好的效果如X3D,SlowFast Networks。同时,我们的应用场景也变得越来越多元化比如视频分类,视频精彩时刻,人机交互。
在这个工作中,我们主要侧重于时序动作识别比如人机交互与VR/AR中的手势识别。和传统的动作识别相比如Kinetics(注重视频分类),此类应用场景主要有两种区别:1. 一般部署在边缘设备上如手机,VR/AR设备上。所以对模型计算量和推理速度有一定的要求;2. 此类动作("Rotate fists counterclockwise" vs "Rotate fists clockwise")和传统动作识别动作("Walking" vs "Running")相比有着较强时序性。针对以上的两点,我们基于2D CNN(轻便)提出了一个混合注意力机制的ACTION模块(对于时序动作建模)。
设计该模块的主要动机是为了探究多个注意力机制对于时序动作的一个建模的潜力。之前的工作如TSM,TEA都提出了相对单一的机制对于时序动作进行建模。而在视频中,前后帧之间都是存在联系的。并且深度神经网络提取的每一帧的feature在各个通道间,也会存在一些时序上的联系。所以我们把这些一一进行建模,并且把它们合并来得到一个视频动作的混合注意力机制的输出。通过实验发现,融合这些不同的注意力机制,能够提高时序动作的建模能力。
1 主要贡献点
1、对于时序动作识别(比如手势)提出了一个混合注意力机制的ACTION模块,该模块兼顾时序动作里面三个重要的信息: (a) 时空信息即动作在时间和空间上的关系;(b) 动作的时序信息在不同信道间的一个权重;(c) 每相邻两帧之间动作的变化轨迹。
2、该模块和经典TSM模块一样,即插即用。基于2D CNN,非常轻便。我们在文章中展示了ACTION模块在三个不同backbone: ResNet-50,MobileNet V2和BNInception相比于TSM带来的效果提升和额外增加计算量。在三个时序动作数据集即Something-to-Something V2,Jester和EgoGesture上都测试了ACTION模块的实用性。
下图展现了ACTION-Net相比较之前TSN和TSM在刻画时序动作轨迹方面的效果。尤其是中间高亮的两帧,可以看到对我们最后分类结果产生影响的不仅仅是手握拳的姿势,同时运动的轨迹也是对于动作的一个重要的评判指标。

2 ACTION模块
ACTION的核心思想是生成三个attention map即时空attention map, channel attention map和motion attention map来激发相应视频中的特征。因为ACTION模块是基于2D CNN的,所以ACTION的输入是一个4D tensor:
![]()
(N: batch size, T: number of segments, C: number of channels, H: hegith, W: width)。下面我们将介绍三个模块分别对于输入的处理。
时空注意力 (Spatial-Temporal Excitation: STE)
该模块通过产生时空attention map来提取视频中的时空(spatio-temporal)特征。传统的时空特征提取主要使用3D卷积,但直接对输入引入3D卷积会大大的增加模型的计算量。所以我们先对做一个channel average得到一个对于时空的global channel的特征
![]()
,我们再将reshape成能够被3D卷积操作的维度即(N, 1, T, H, W)。至此,我们可以用一个3D卷积核对这个
![]()
进行卷积,卷积完之后再通过Sigmoid就可以得到一个时空的attention map
![]()
。这个时空attention map reshape成和一样的维度再去点乘就可以得到激发我们所需要的时空特征。STE的结构和PyTorch API伪代码如下图:


信道注意力 (Channel Excitation: CE)
这个block是基于SE-Net的SE block。但因为视频动作中含有时序信息,所以我们在信道的squeeze和unsqueeze之间插入了1D在时域上的卷积来增强信道在时域上的相互依赖程度。和SE一样,我们可以得到一个基于信道的attention map
![]()
。和STE一样,我们用得到的attention map点乘输入的得到信道所激发特征。STE的结构和PyTorch API伪代码如下图:


运动注意力 (Motion Excitation: ME)
ME在之前的工作如STM和TEA都有采用。主要是描述每相邻两帧之间动作的移动,这一点和optical flow很像。我们的motion feature
![]()
通过一个2D卷积对前后两帧
![]()
和
![]()
来进行操作得到的。具体的来讲,
![]()
。我们把输入每两帧得到的差值在时间维度上concatenate起来(最后一个补0)。再对这个得到的特征做spatial average pooling通过Sidmoid之后得到一个motion attention map
![]()
。ME结构如下图,伪代码可以参照TEA。

ACTION模块是由以上提到的三个注意力模块并联而成。这个模块和之前的工作TSM一样,即插即用。在和state-of-the-art的方法比较中,我们的backbone采用了和之前工作相同的ResNet-50作为比较。同时,我们以TSN和TSM为baseline测试了ACTION在不同backbone (ResNet-50, MobileNet V2, BN-Inception) 上的性能。

3 实验结果
我们分别用了三个侧重于时序动作的视频数据集: Something-Something V2, Jester, EgoGesture来测试我们提出的ACTION模块。
对比实验
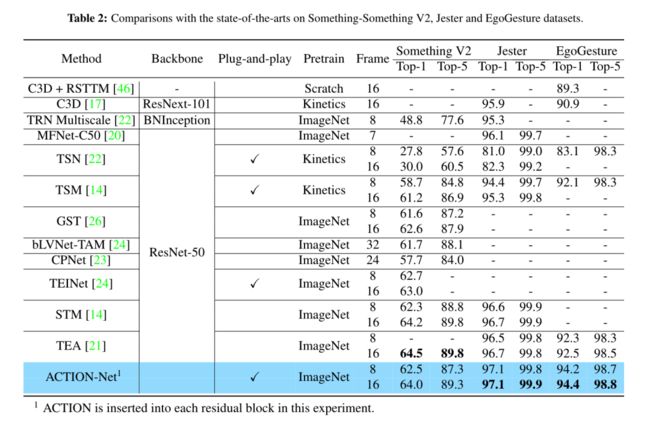
从下表中可以看出ACTION在Jester和EgoGesture上面的表现还是十分鲁棒的,都取得了state-of-the-art的效果。在Something V2的数据集上面相比STM和TEA也取得了很相近的效果。但值得注意的是,STM和TEA都是分别针对于ResNet和Res2Net设计的,而ACTION是一个即插即用的模块,不会受限于backbone种类。
Ablation Studies
-
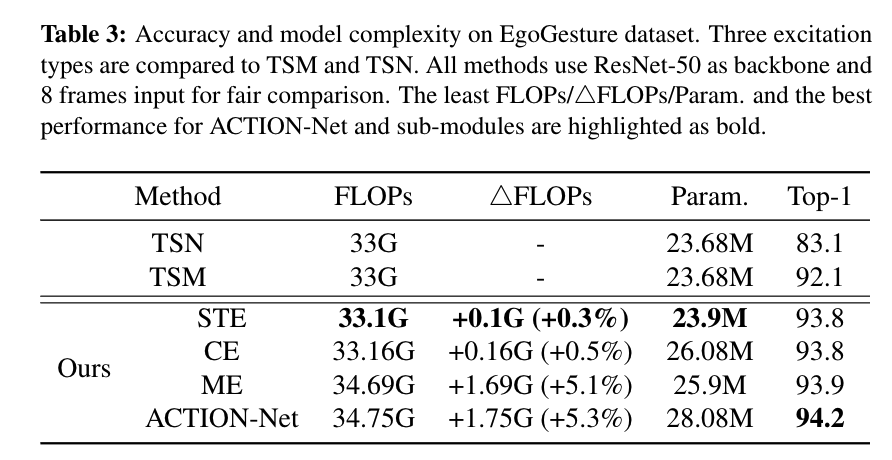
Table 3列出了不同path增加的计算量,参数以及效果提升。可以看STE和CE相对TSM于所增加的计算量非常小,同时可以提高1.7%准确率。ME相对于另外两个模块计算量有所增加,但同时增加的准确率也最高。当我们把三个模块并联成ACTION时,准确率最高,但同时计算量也是增加的最多的。
-
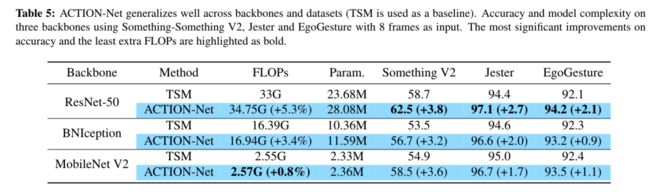
Table 5 列出了ACTION模块在不同backbone相较于baseline的一个效果提升。我们可以看出ACTION在MobileNet V2中所增加的计算量最低,这是由于MobileNet V2本身倒锥形的结构(Inverted Residual)即在residual block里,两边channel少,中间channel多。而我们的ACTION插在每个residual的开始,所以MobileNet V2这样的结构本身会是ACTION带来的计算量比ResNet-50和BNInception来的要小。从准确率增加的效果上来看,对ResNet-50的提升最为明显(同时也增加的计算量也是最大)。
ACTION模块在不同backbone上对于不同数据集的一个效率
![]()
我们定义了一个效率系数
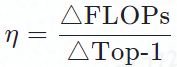
来量化ACTION模块相对于TSM每提高1%的Top-1准确率所需增加的额外计算量。越低代表效率越高。下图我们展示了ACTION在三个不同数据集上对于三个backbone的效率。我们可以看到ACTION在MobileNet V2上的效率最为明显。类似的,在Something-Something V2上的效率相较于另外两个数据集要高。

可视化
我们用CAM来可视化不同区域对于分类做出的贡献。相比于TSN和TSM只识别出视频里的手的姿势,我们可以看到ACTION-Net可以感知到动作的移动对于整个动作的重要性。