目标检测之SSD:Single Shot MultiBox Detector
Single Shot MultiBox Detector论文学习
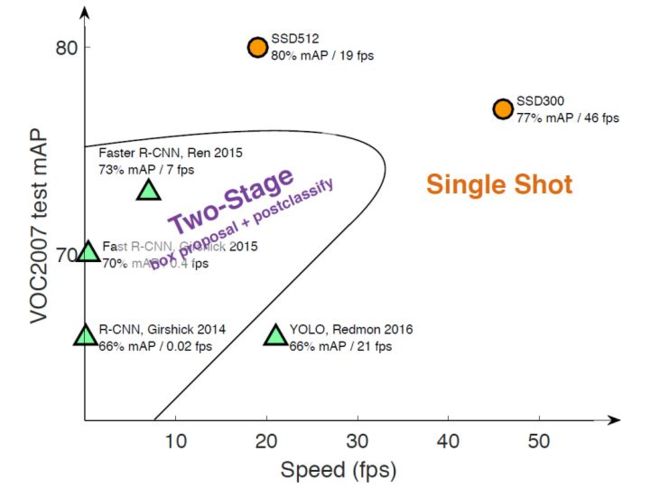
single shot指的是SSD算法属于one-stage方法,MultiBox说明SSD是多框预测。ssd和yolo都是一步式检测器,yolov1的一个缺点就是不擅长做小目标识别,ssd正好克服了这个问题,ssd的一个优势就是准确率高,但ssd512版本fps比yolo低。
1.采用多尺度特征图用于检测
卷积神经网络一般是个金字塔结构,前宽后窄,所以在不同的阶段就可以得到一些比较大的特征图和一些比较小的特征图,思路和spp差不多。
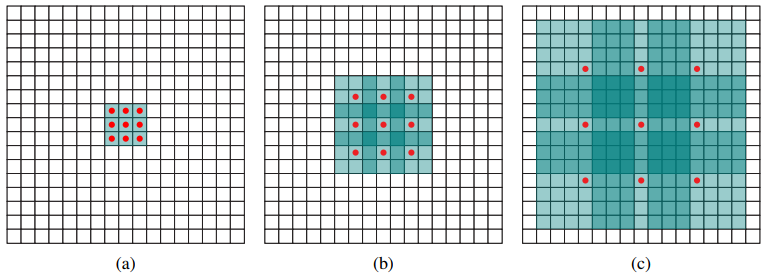
一是SSD提取不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)用来检测小物体,小尺度特征图(较靠后的特征图,感受野大)用来检测大物体;
二是SSD采用了不同尺度和长宽比的先验框Anchor box,这个技巧新版本的yolov2也使用了。
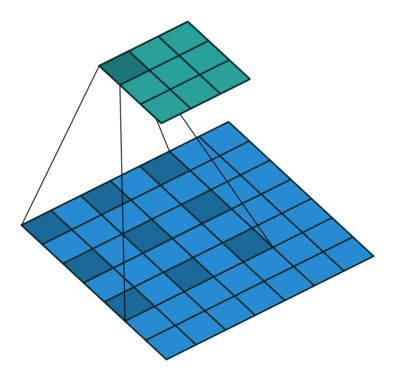
2.采用卷积进行检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。
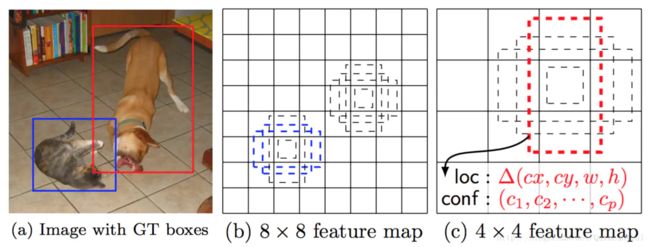
3.设置先验框
SSD借鉴了Faster R-CNN中anchor box的理念,将 feature map 切分为一个个格子feature map cell,对于每一个格子,设置的一系列固定大小的 default box(先验框) ,预测的bounding boxes(边界框)是以这些先验框为基准的,在一定程度上节约了时间。
第一部分是各个类别的置信度或者评分,SSD将背景也当做了一个特殊的类别,如果检测目标共有c 个类别,SSD其实需要预测 c+1 个置信度值,第一个置信度指的是不含目标或者属于背景的评分,这个是和yolov1不一样的。所以当第一个类别置信度最高时,表示边界框中并不包含目标。
第二部分就是边界框的location,包含4个值x,y,w,h分别表示边界框的中心坐标以及宽高,这个和yolo一样 。
每一个bb预测c个类别置信度和4个收缩量 offset(真实预测值其实是边界框相对于先验框的转换值然后就带入了四个伸缩量),每个单元设置k个先验框,特征图是m*n的话就需要,就要计算m*n*(c+4)*k次卷积
第三部分default box的 scale(大小、是一种归一化于输入尺度的面积)和 aspect ratio(横纵比)规定:
scale:
smin是0.2,表示最底层的scale是0.2;smax是0.9,表示最高层的scale是0.9。这就保证了sk是在0.2-0.9的范围内的
aspect ratio :一共有5种{1,2,3,1/2,1/3}
所以default box 的宽的计算公式为:![]()
高:![]()
宽和高的乘积是 scale 的平方
4.正负样本
将 prior box 和 grount truth box 按照IOU(本论文叫做JaccardOverlap)进行匹配,匹配成功则这个 prior box 就是 positive example(正样本),如果匹配不上,就是 negative example(负样本),显然这样产生的负样本的数量要远远多于正样本。做了难例挖掘hard nevigating mining:将所有的匹配不上的 负样本 按照分类 loss 进行排序,选择最高的 num_sel 个 prior box 序号集合作为最终的负样本集。这里就可以利用 num_sel 来控制最后正、负样本的比例在 1:3 左右。

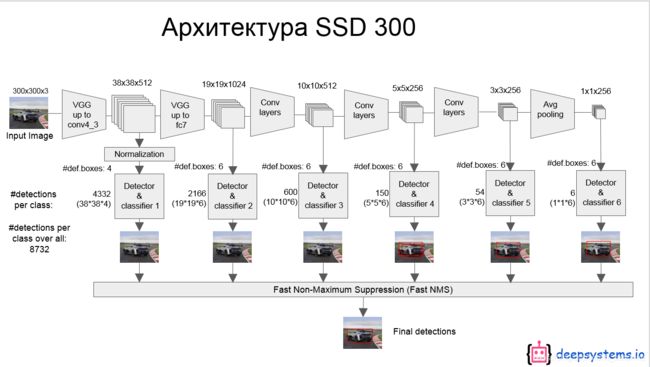
5.网络结构
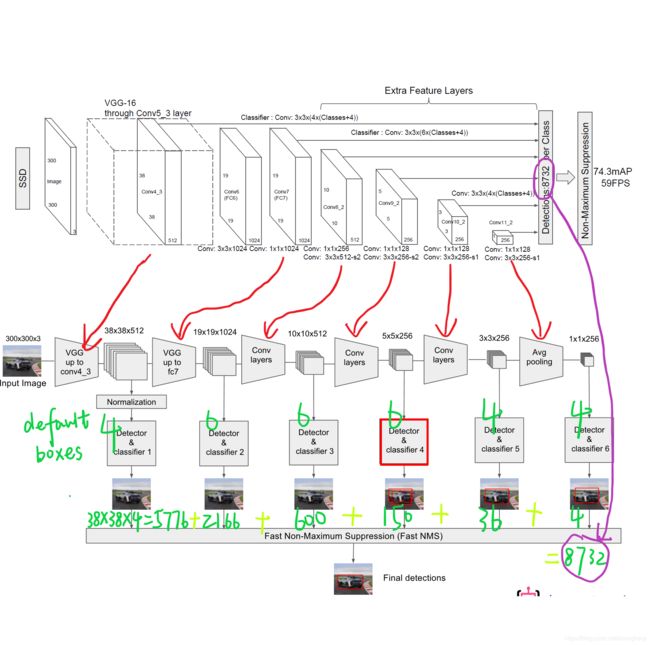
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于多尺度检测的。其中VGG16中的Conv4_3层将作为用于检测的第一个特征图
Conv4_3 得到的feature map大小为38*38:38*38*4 = 5776,用它作为用于检测的第一个特征图,从后面新增的卷积层中提取Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图,其大小分别是 38、19、10、5、3、1,越来越小的前面适合小目标,后面适合大目标。不同特征图单元cell设置的先验框数目不同,对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加。
最后得到8731个prior box边界框(可以认为 default box 是抽象类,而 prior box 是具体实例,这里用到的 default box 和 Faster RCNN中的 Anchor 很像),这是一个相当庞大的数字,所以SSD采样量还是比较大的,是密集采用,因此在map上直接秒杀yolo,当然耗时也越大。别看获取的 prior box 一共有8732个,那么可能分别有10、20个 prior box 能分别与这个 ground truth box 匹配上,匹配成功的将会作为正样本参与分类和回归训练,而未能匹配的则只会参加分类(负样本)训练。
6.Atrous Algorithm(Dilated Convolution膨胀卷积、空洞卷积)
atrous algorithm可以在减小卷积步长的同时扩大feature map的大小,即同等情况下,通过这个操作,我们可以获得一个更大的feature map,而实验表明,大的feature map会提升检测的性能。yolov3中也使用了。
7.损失函数
和Faster RCNN的基本一样,由分类和回归两部分组成,回归部分的loss是希望预测的box和prior box的差距尽可能跟ground truth和prior box的差距接近,这样预测的box就能尽量和ground truth一样。总损失是置信度损失和位置损失的加权和
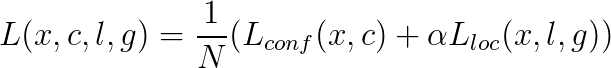
位置损失,其采用Smooth L1 loss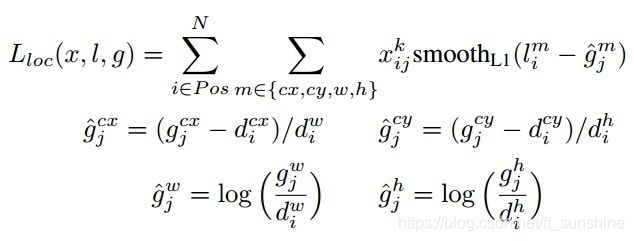
下面四个公式就是反编码公式

置信度误差,其采用softmax loss
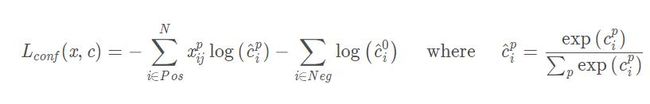
8.数据扩增
为了使模型对各种输入目标大小和形状更鲁棒,每张训练图像都是通过以下选项之一进行随机采样的:1.直接使用整个原始输入图像。
2.采样一个patch(就是feature map 上裁下来一部分,使得与目标之间的最小Jaccard overlap重叠为0.1,0.3,0.5,0.7或0.9。
3.水平翻转:以0.5的概率进行水平翻转
4.光度失真: Some improvements on deep convolutional neural network based image classification中提出的
###9.性能评估
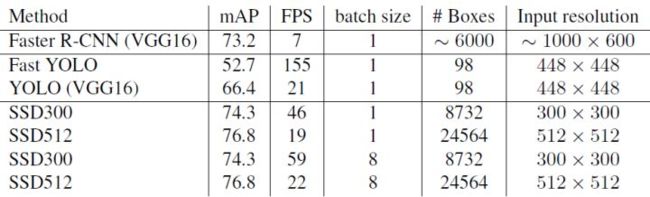
ssd支持两种规模的输入:300、512。SSD与Faster R-CNN有同样的准确度,并且与Yolo具有同样较快地检测速度。


采用多尺度的特征图用于检测也是至关重要的,在ssd中混合的多尺度特征混合提取方式是比较好的一种
参考文献:
Single Shot MultiBox Detector论文翻译【修改】 - GrPhoenix - 博客园
(13条消息) SSD:Single Shot MultiBox Detector_u013087645的专栏-CSDN博客
(13条消息) SSD论文笔记_chenghaoy的博客-CSDN博客_ssd论文
Single Shot MultiBox Detector论文翻译——中英文对照 - 简书
目标检测|SSD原理与实现 - 知乎
(13条消息) SSD学习小结_sinat_33454180的博客-CSDN博客
(13条消息) SSD学习总结_aift的专栏-CSDN博客
五、SSD原理(Single Shot MultiBox Detector) - keepgoing18 - 博客园
(13条消息) 论文阅读:SSD: Single Shot MultiBox Detector_Simon’s Blog-CSDN博客_ssd论文原文
很值得看的深度学习笔记(七)SSD 论文阅读笔记 - xuanyuyt - 博客园
(13条消息) 目标检测常见的框架_gaotihong的博客-CSDN博客_目标检测框架
动手学深度学习