Gan的loss函数
1. Classic Adversarial Loss
优化目标为:
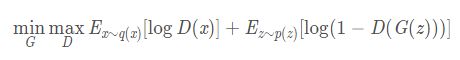
D(x)为经过sigmoid的输出值
(1)在GAN第一阶段——求Discriminator,最大化
![]()
实验中统计梯度是对最小值进行寻优的,因此实际操作上是对目标函数做最小化处理:
![]()
实现方式:
dis_real、dis_fake分别为真假样本输入判别器输出的logit,未经过sigmoid
(1)直接计算
L1 = F.mean(-F.log(F.sigmoid(dis_real)))
L2 = F.mean(-F.log(1-F.sigmoid(dis_fake)))
loss_dis = L1 + L2
(2)BCEWithLogitsloss(p,y), p为判别器输出的logit,未经过sigmoid,y为判别器输入对应的标签
BCEWithLogitsloss(p,y) = -[ylog(sigmoid(p))+(1-y)log(1-sigmoid(p))]
BCELoss()和BCEWithLogitsLoss()的区别
https://blog.csdn.net/qq_16236875/article/details/87980867
L1 = BCEWithLogitsloss(dis_real,y_real)
L2 = BCEWithLogitsloss(dis_fake,y_fake)
loss_dis = L1 + L2
(3)softplus(p), p为判别器输出的logit,未经过sigmoid
softplus(-p) = log(1+exp(-p)) = -log(1/(1+exp(-p))) = -log(sigmoid(p))
softplus(p) = log(1+exp(p)) = -log(1/(1+exp(p))) = -log(1-1/(1+exp(-p))) = -log(1-sigmoid(p))
L1 = F.mean(softplus(-dis_real))
L2 = F.mean(F.softplus(dis_fake))
loss_dis = L1 + L2(2)在GAN第二阶段——求Generator,最小化

2. WGAN的loss object functions:
![]()
L为真实分布与生成分布之间的Wasserstein距离。
注意原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
(1)在GAN第一阶段——求Discriminator,最大化L,等价于最小化下式
![]()
其数值越小,表示真实分布与生成分布的Wasserstein距离越大,dis训练得越好。
实现方式:
dis_real、dis_fake分别为真假样本输入判别器输出的logit,未经过sigmoid
loss_dis = - F.mean(dis_real) + F.mean(dis_fake)(2)在GAN第二阶段——求Generator,最小化L
![]()
3.Hinge loss
最初是SVM中的概念,其基本思想是让正例和负例之间的距离尽量大,后来在Geometric GAN中,被迁移到GAN:

(1)在GAN第一阶段——求Discriminator,min LD,
![]()
希望D(x)越>1越好,此时的loss为0,D(G(z))越<-1越好,此时loss为0。便可将真样本与假样本分开与-1,1两端。
对于D来说,只有当D(x) < 1 的正向样本,以及D(G(z)) > -1的负样本才会对结果产生影响
也就是说,只有一些没有被合理区分的样本,才会对梯度产生影响这种方法可以使训练更加稳定。
dis_real、dis_fake分别为真假样本输入判别器输出的logit,未经过sigmoid
loss_dis = F.mean(F.relu(1. - dis_real)) + F.mean(F.relu(1. + dis_fake))(2)在GAN第二阶段——求Generator,min LG,
![]()
优化D时,希望D(G(z))越<-1越好,此时则希望D(G(z))越大越好,则更倾向于真样本。故最小化-D(G(z))。
Geometric GAN的判别器力图把真实样本映射到大于1的区间,把伪造样本映射到小于-1的区间。