KDD Cup 2020多模态召回比赛亚军方案与搜索业务应用

ACM SIGKDD(ACM SIGKDD Conference on Knowledge Discovery and Data Mining)是世界数据挖掘领域的顶级国际会议。今年,KDD Cup共设置四个赛道共五道赛题,涉及数据偏差问题(Debiasing)、多模态召回(Multimodalities Recall)、自动化图学习(AutoGraph)、对抗学习问题和强化学习问题。
美团搜索广告算法团队最终在Debiasing赛道中获得冠军(1/1895),在AutoGraph赛道中也获得了冠军(1/149)。在Multimodalities Recall赛道中,亚军被美团搜索与NLP团队摘得(2/1433),而季军被美团搜索广告算法团队收入囊中(3/1433)。
本文将介绍多模态召回比赛亚军的技术方案,以及在美团搜索业务中的应用与实践,希望能给从事相关工作的同学带来一些帮助或者启发。
1. 背景
跟其它电商公司一样,美团业务场景中除了文本,还存在图片、动图、视频等多种模态信息。同时,美团搜索是典型的多模态搜索引擎,召回和排序列表中存在POI、图片、文本、视频等多种模态结果,如何保证Query和多模态搜索结果的相关性面临着很大的挑战。
鉴于多模态召回赛题(Multimodalities Recall)和美团搜索业务的挑战比较类似,本着磨炼算法基本功和沉淀相关技术能力的目的,美团搜索与NLP组建团队参与了该项赛事,最终提出的“基于ImageBERT和LXMERT融合的多模态召回解决方案”最终获得了第二名(2/1433)(KDD Cup2020 Recall榜单)。本文将介绍多模态召回赛题的技术方案,以及多模态技术在美团搜索场景中的落地应用。
相关代码已经在GitHub上开源:
https://github.com/zuokai/KDDCUP_2020_MultimodalitiesRecall_2nd_Place。
 图1 KDD Cup 2020 Multimodalities Recall 比赛TOP 10榜单
图1 KDD Cup 2020 Multimodalities Recall 比赛TOP 10榜单
2. 赛题简介
2019年,全球零售电子商务销售额达3.53万亿美元,预计到2022年,电子零售收入将增长至6.54万亿美元。如此快速增长的业务规模表明了电子商务行业的广阔发展前景,但与此同时,这也意味着日益复杂的市场和用户需求。随着电子商务行业规模的不断增长,与之相关的各个模态数据也在不断增多,包括各式各样的带货直播视频、以图片或视频形式展示的生活故事等等。新的业务和数据都为电子商务平台的发展带来了新的挑战。
目前,绝大多数的电子商务和零售公司都采用了各种数据分析和挖掘算法来增强其搜索和推荐系统的性能。在这一过程中,多模态的语义理解是极为重要的。高质量的语义理解模型能够帮助平台更好的理解消费者的需求,返回与用户请求更为相关的商品,能够显著的提高平台的服务质量和用户体验。

在此背景下,今年的KDD Cup举办了多媒体召回任务(Modern E-Commerce Platform: Multimodalities Recall),任务要求参赛者根据用户的查询Query,对候选集合中的所有商品图片进行相关性排序,并找出最相关的5个商品图片。举例说明如下:
如下图2所示,用户输入的Query为:
leopard-print women's shoes
根据其语义信息,左侧图片与查询Query是相关的,而右侧的图片与查询Query是不相关的。
 图2 多模态匹配示意图
图2 多模态匹配示意图
从示例可以看出,该任务是典型的多模态召回任务,可以转化为Text-Image Matching问题,通过训练多模态召回模型,对Query-Image样本对进行相关性打分,然后对相关性分数进行排序,确定最后的召回列表。
2.1 比赛数据
本次比赛的数据来自淘宝平台真实场景下用户Query以及商品数据,包含三部分:训练集(Train)、验证集(Val)和测试集(Test)。根据比赛阶段的不同,测试集又分为testA和testB两个部分。数据集的规模、包含的字段以及数据样例如表1所示。真实样本数据不包含可视化图片,示例图是为了阅读和理解的便利。
 表1 比赛数据集详情
表1 比赛数据集详情
在数据方面,需要注意的点有:
训练集(Train)每条数据代表相关的Query-Image样本对,而在验证集(Val)和测试集(Test)中,每条Query会有多张候选图片,每条数据表示需要计算相关性的Query-Image样本对。
赛事主办方已经对所有图片通过目标检测模型(Faster-RCNN)提取了多个目标框,并保存了目标框相应的2048维图像特征。因此,在模型中无需再考虑图像特征的提取。
2.2 评价指标
本次比赛采用召回Top 5结果的归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG@5)来作为相关结果排序的评价指标。
3. 经典解法
本次比赛需要解决的问题可以转化为Text-Image Matching任务,即对每一个Query-Image 样本对进行相似性打分,进而对每个Query的候选图片进行相关度排序,得到最终结果。多模态匹配问题通常有两种解决思路:
将不同模态数据映射到不同特征空间,然后通过隐层交互这些特征学习到一个不可解释的距离函数,如图3 (a)所示。
将不同模态数据映射到同一特征空间,从而计算不同模态数据之间的可解释距离(相似度),如图3 (b)所示。
 图3 常用的多模态匹配解决思路
图3 常用的多模态匹配解决思路
一般而言,同等条件下,由于图文特征组合后可以为模型隐层提供更多的交叉特征信息,因而左侧的模型效果要优于右侧的模型,所以在后续的算法设计中,我们都是围绕图3左侧的解决思路展开的。
随着Goolge BERT模型在自然语言处理领域的巨大成功,在多模态领域也有越来越多的研究人员开始借鉴BERT的预训练方法,发展出融合图片/视频(Image/Video)等其他模态的BERT模型,并成功应用与多模态检索、VQA、Image Caption等任务中。因此,考虑使用BERT相关的多模态预训练模型(Vision-Language Pre-training, VLP),并将图文相关性计算的下游任务转化为图文是否匹配的二分类问题,进行模型学习。
目前,基于Transformer模型的多模态VLP算法主要分为两个流派:
单流模型,在单流模型中文本信息和视觉信息在一开始便进行了融合,直接一起输入到Encoder(Transformer)中。典型的单流模型如ImageBERT [3],VisualBERT [9]、VL-BERT [10] 等。
双流模型,在双流模型中文本信息和视觉信息一开始先经过两个独立的Encoder(Transformer)模块,然后再通过Cross Transformer来实现不同模态信息的融合。典型的双流模型如LXMERT [4],ViLBERT [8] 等。
4. 我们的方法:Transformer-Based Ensembled Models TBEM
本次比赛中,在算法方面,我们选用了领域最新的基于Transformer的VLP算法构建模型主体,并加入了Text-Image Matching作为下游任务。除了构建模型以外,我们通过数据分析来确定模型参数,构建训练数据。在完成模型训练后,通过结果后处理策略来进一步提升算法效果。整个算法的流程如下图4所示:
 图4 算法流程图
图4 算法流程图
接下来对算法中的每个环节进行详细说明。
4.1 数据分析&处理
数据分析和处理主要基于以下三个方面考虑:
正负样本构建:由于主办方提供的训练数据中,只包含了相关的Query-Image样本对,相当于只有正样本数据,因此需要通过数据分析,设计策略构建负样本。
模型参数设定:在模型中,图片目标框最大数量、Query文本最大长度等参数需要结合训练数据的分布来设计。
排序结果后处理:通过分析Query召回的图片数据分布特点,确定结果后处理策略。
常规的训练数据生成策略为:对于每一个Batch的数据,按照1:1的比例选择正负样本。其中,正样本为训练集(Train)中的原始数据,负样本通过替换正样本中的Query字段产生,替换的Query是按照一定策略从训练集(Train)中获取。
为了提升模型学习效果,我们在构建负样本的过程中进行了难例挖掘,在构造样本时,通过使正负样本的部分目标框包含同样的类别标签,从而构建一部分较为相似的正负样本,以提高模型对于相似的正负样本的区分度。
难例挖掘的过程如下图5所示,左右两侧的相关样本对都包含了“shoes”这一类别标签,使用右侧样本对的Query替换左侧图片的Query,从而构建难例。通过学习这类样本,能够提高模型对于不同类型“shoes”描述的区分度。
 图5 难例挖掘过程示意图
图5 难例挖掘过程示意图
具体而言,负样本构建策略如表2所示:
 表2 负样本Query抽取策略
表2 负样本Query抽取策略
其次,通过对训练数据中目标框的个数以及Query长度的分布情况分析,确定模型的相关参数。图片中目标框的最大个数设置为10,Query文本的最大单词个数为20。后处理策略相关的内容,我们将会在4.3部分进行详细的介绍。
4.2 模型构建与训练
4.2.1 模型结构
基于上文中对多模态检索领域现有方法的调研,在本次比赛中,我们分别从单流模型和双流模型中各选择了相应SOTA的算法,即ImageBERT和LXMERT。具体而言,针对比赛任务,两种算法分别进行了如下改进:
LXMERT模型方面主要的改进包括:
图片特征部分(Visual Feature)融入了目标框类别标签所对应的文本特征。
Text-Image Matching Task中使用两层全连接网络进行图片和文本融合特征的二分类,其中第一个全连接层之后使用GeLU [2] 进行激活,然后通过LayerNorm [1] 进行归一化处理。
在第二个全连接层之后采用Cross Entropy Loss训练网络。
改进后的模型结构如下图6所示:
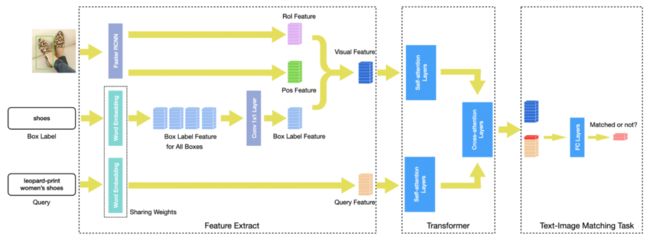
图6 比赛中使用的LXMERT模型结构
特征网络的预训练权重使用了LXMERT所提供权重文件,下载地址为:https://github.com/airsplay/lxmert。
ImageBERT:本方案中一共用到了两个版本的 ImageBERT模型,分别记为ImageBERT A和ImageBERT B,下面会分别介绍改进点。
ImageBERT A:基于原始ImageBERT的改进有以下几点。
训练任务:不对图片特征和Query的部分单词做掩码,仅训练相关性匹配任务,不进行MLM等其他任务的训练。
Segment Embedding:将Segment Embedding统一编码为0,不对图片特征和Query文本单独进行编码。
损失函数:在[CLS]位输出Query与Image的匹配关系,通过Cross Entropy Loss计算损失。
依据上述策略,选用BERT-Base模型权重对变量初始化,在此基础上进行FineTune。其模型结构如下图7所示:
 图7 比赛中使用的ImageBert模型结构
图7 比赛中使用的ImageBert模型结构
ImageBERT B:和ImageBERT A的不同点是在Position Embedding和Segment Embedding的处理上。
Position Embedding:去掉了ImageBert中图像目标框位置信息的Position Embedding结构。
Segment Embedding:文本的Segment Embedding编码为0,图片特征的Segment Embedding编码为1。
依据上述策略,同样选用BERT-Base模型权重对变量初始化,在此基础上进行FineTune。
三种模型构建中,共性的创新点在于,在模型的输入中引入了图片目标框的标签信息。而这一思路同样被应用在了微软2020年5月份最新的论文Oscar [7] 中,但该文的特征使用方式和损失函数设置与我们的方案不同。
4.2.2 模型训练
使用节4.1的数据生成策略构建训练数据,分别对上述三个模型进行训练,训练后的模型在验证集(Val)上的效果如表3所示。
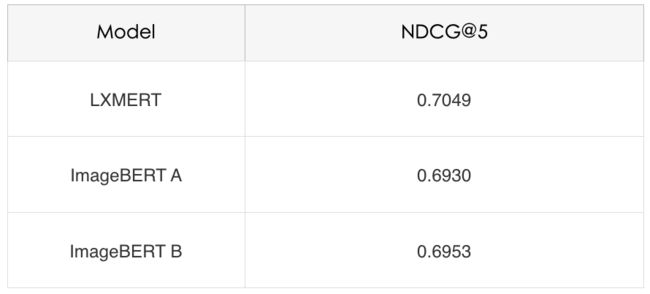 表3 初步训练后模型在验证集(Val)上的效果
表3 初步训练后模型在验证集(Val)上的效果
4.2.3 利用损失函数进行模型微调
完成初步的模型训练后,接下来使用不同的损失函数对模型进行进一步的微调,主要有AMSoftmax Loss [5]、Multi-Similarity Loss [6]。
AMSoftmax Loss通过权值归一化和特征归一化,在缩小类内距离的同时增大类间距离,从而提高了模型效果。
Multi-Similarity Loss将深度度量学习转化为样本对的加权问题,采用采样和加权交替迭代的策略实现了自相似性,负相对相似性和正相对相似性三种,能够促使模型学习得到更好的特征。
在我们的方案中所采用的具体策略如下:
对于LXMERT,在特征网络后加入Multi-Similarity Loss,与Cross Entropy Loss 组成多任务学习网络,进行模型微调。
对于ImageBERT A,使用AMSoftmax Loss代替Cross Entropy Loss。
对于ImageBERT B,损失函数处理方式和LXMERT一致。
经过微调,各模型在验证集(Val)上的效果如表4所示。
 表4 损失函数对模型微调--验证集(Val)上的效果
表4 损失函数对模型微调--验证集(Val)上的效果
4.2.4 通过数据过采样进行模型微调
为了进一步提高模型效果,本方案根据训练集(Train)中Query字段与测试集(testB)中的Query字段的相似程度,对训练集(Test)进行了过采样,采样规则如下:
对Query在测试集(testB)中出现的样本,或与测试集(testB)中的Query存在包含关系的样本,根据其在训练集(Train)出现的次数,按照反比例进行过采样。
对Query未在测试集(testB)中出现的样本,根据两个数据集Query中重复词的个数,对测试集(testB)每条Query抽取重复词数目Top10的训练集(Train)样本,每条样本过采样50次。
数据过采样后,分别对与上述的三个模型按照如下方案进行微调:
对于LXMERT模型,使用过采样得到的训练样本对LXMERT模型进行进一步微调。
对于ImageBERT A模型,本方案从训练集(Train)选出Query中单词和测试集(Test)Query存在重合的样本对模型进行进一步微调。
对于ImageBERT B模型,考虑到训练集(Train)中存在Query表达意思相同,但是单词排列顺序不同的情况,类似"sporty men's high-top shoes"和"high-top sporty men's shoes",为了增强模型的鲁棒性,以一定概率对Query的单词(Word)进行随机打乱,对ImageBERT B模型进行进一步微调。
训练后各模型在验证集(Val)上的效果如表5所示:
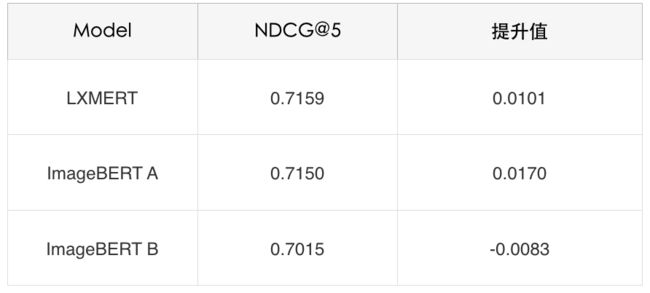 表5 过采样后验证集(Val)集上的效果
表5 过采样后验证集(Val)集上的效果
为了充分利用全部有标签的数据,本方案进一步使用了验证集(Val)对模型进行FineTune。为了避免过拟合,最终提交结果只对ImageBERT A模型进行了上述操作。
在Query-Image样本对的相关性的预测阶段,本方案对测试集(testB)Query所包含的短句进行统计,发现其中“sen department” 这一短句在测试集(testB)中大量出现,但在训练集(Train)中从未出现,但出现过“forest style”这个短句。为了避免这组同义短句对模型预测带来的影响,选择将测试集(testB)中Query的“sen department”替换为“forest style”,并且利用ImageBERT A对替换后的测试集进行相关性预测,结果记为ImageBERT A'。
4.3 模型融合和后处理
经过上述的模型构建、训练以及预测,本方案共得到了4个样本对相关性得分的文件。接下来对预测结果进行Ensemble,并按照一定策略进行后处理,得到Query相应的Image候选排序集合,具体步骤如下:
(1)在Ensemble阶段,本方案选择对不同模型所得相关性分数进行加权求和,作为每一个样本对的最终相关性得分,各模型按照LXMERT、ImageBERT A、ImageBERT B、ImageBERT A'的顺序的权值为0.3:0.2:0.3:0.2,各模型的权重利用网格搜索的方式确定,通过遍历4个模型的不同权重占比,每个模型权重占比从0到1,选取在valid集上效果最优的权重,进行归一化,作为最终权重。
(2)在得到所有Query-Image样本对的相关性得分之后,接下来对Query所对应的多张候选图片进行排序。验证集(Val)和测试集(testB)的数据中,部分Image出现在了多个Query的候选样本中,本方案对这部分样本做了进一步处理:
a.考虑到同一Image通常只对应一个Query,因此认为同一个Image只与相关性分数最高的Query相关。使用上述策略对ImageBERT B模型在验证集(Val)上所得结果进行后处理,模型的NDCG@5 分数从0.7098提升到了0.7486。
b.考虑到同一Image对应的多条Query往往差异较小,其语义也是比较接近的,这导致了训练后的模型对这类样本的区分度较差,较差区分度的相关性分数会一定程度上引起模型NDCG@5的下降。针对这种情况我们采用了如下操作:
如果同一Query的相关性分数中,Top1 Image和Top2 Image相关性分数之差大于一定阈值,计算NDCG@5时则只保留Top 1所对应的Query-Image样本对,删除其他样本对。
相反的,如果Top1 Image和Top2 Image相关性分数之差小于或等于一定阈值,计算NDCG@5时,删除所有包含该Image的样本对。
使用上述策略对ImageBERT B的验证集(Val)结果进行后处理,当选定阈值为0.92时,模型的NDCG@5 分数从0.7098提升到了0.8352。
可以看到,采用策略b处理后,模型性能得到了显著提升,因此,本方案在测试集(testB)上,对所有模型Ensemble后的相关性得分采用了策略b进行处理,得到了最终的相关性排序。
5. 多模态在美团搜索的应用
前面提到过,美团搜索是典型的多模态搜索场景,目前多模态能力在搜索的多个场景进行了落地。介绍具体的落地场景前,先简单介绍下美团搜索的整体架构,美团整体搜索架构主要分为五层,分别为:数据层、召回层、精排层、小模型重排层以及最终的结果展示层,接下来按照搜索的五层架构详细介绍下搜索场景中多模态的落地。
数据层
多模态表示:基于美团海量的文本和图像/视频数据,构建平行语料,进行ImageBERT模型的预训练,训练模型用于提取文本和图片/视频向量化表征,服务下游召回/排序任务。
多模态融合:图片/视频数据的多分类任务中,引入相关联的文本,用于提升分类标签的准确率,服务下游的图片/视频标签召回以及展示层按搜索Query出图。
召回层
多模态表示&融合:内容搜索、视频搜索、全文检索等多路召回场景中,引入图片/视频的分类标签召回以及图片/视频向量化召回,丰富召回结果,提升召回结果相关性。
精排层&小模型重排
多模态表示&融合:排序模型中,引入图片/视频的向量化Embedding特征,以及搜索Query和展示图片/视频的相关性特征、搜索结果和展示图片/视频的相关性特征,优化排序效果。
展示层
多模态融合:图片/视频优选阶段,引入图片/视频和Query以及和搜索结果的相关性信息,做到按搜索Query出图以及搜索结果出图,优化用户体验。
 图8 多模态在美团搜索的落地场景
图8 多模态在美团搜索的落地场景
6. 总结
在本次比赛中,我们构建了一种基于ImageBERT和LXMERT的多模态召回模型,并通过数据预处理、结果融合以及后处理策略来提升模型效果。该模型能够细粒度的对用户查询Query的相关图片进行打分排序,从而得到高质量的排序列表。通过本次比赛,我们对多模态检索领域的算法和研究方向有了更深的认识,也借此机会对前沿算法的工业落地能力进行了摸底测试,为后续进一步的算法研究和落地打下了基础。此外,由于本次比赛的场景与美团搜索与NLP部的业务场景存在一定的相似性,因此该模型未来也能够直接为我们的业务赋能。
目前,美团搜索与NLP团队正在结合多模态信息,比如文本、图像、OCR等,开展MT-BERT多模态预训练工作,通过融合多模态特征,学习更好的语义表达,同时也在尝试落地更多的下游任务,比如图文相关性、向量化召回、多模态特征表示、基于多模态信息的标题生成等。
参考文献
[1] Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer Normalization. arXiv preprint arXiv:1607.06450 (2016).
[2] Hendrycks, D., and Gimpel, K. Gaussian Error Linear Units (GeLUs). arXiv preprint arXiv:1606.08415 (2016).
[3] Qi, D., Su, L., Song, J., Cui, E., Bharti, T., and Sacheti, A. Imagebert: Cross-modal Pre-training with Large-scale Weak-supervised Image-text Data. arXiv preprint arXiv:2001.07966 (2020).
[4] Tan, H., and Bansal, M. LXMERT: Learning Cross-modality Encoder Representations from Transformers. arXiv preprint arXiv:1908.07490 (2019).
[5] Wang, F., Liu, W., Liu, H., and Cheng, J. Additive Margin Softmax for Face Verification. arXiv preprint arXiv:1801.05599 (2018).
[6] Wang, X., Han, X., Huang, W., Dong, D., and Scott, M. R. Multi-similarity Loss with General Pair Weighting for Deep Metric Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2019), pp. 5022–5030.
[7] Li X, Yin X, Li C, et al. Oscar: Object-semantics aligned pre-training for vision-language tasks[J]. arXiv preprint arXiv:2004.06165, 2020.
[8] Lu J, Batra D, Parikh D, et al. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[C]//Advances in Neural Information Processing Systems. 2019: 13-23.
[9] Li L H, Yatskar M, Yin D, et al. Visualbert: A simple and performant baseline for vision and language[J]. arXiv preprint arXiv:1908.03557, 2019.
[10] Su W, Zhu X, Cao Y, et al. Vl-bert: Pre-training of generic visual-linguistic representations[J]. arXiv preprint arXiv:1908.08530, 2019.
[11] 杨扬、佳昊等. MT-BERT的探索和实践.
作者简介
左凯,马潮,东帅,曹佐,金刚,张弓等,均来自美团AI平台搜索与NLP部。
关于美团AI
美团AI以“帮人们吃得更好,生活更好”为核心目标,致力于在实际业务场景需求上探索前沿的人工智能技术,并将之迅速落地在实际生活服务场景中,完成线下经济的数字化。
美团AI诞生于美团丰富的生活服务场景需求之上,具有场景驱动技术的独特性与优势。以业务场景与丰富数据为基础,通过图像识别、语音交互、自然语言处理、配送调度技术,落地于无人配送、无人微仓、智慧门店等真实场景下,覆盖人们生活的方方面面,用科技助力用户生活质量提升,产业智能化升级乃至整个社会的生活服务新基建建设。
更多信息请访问:https://ai.meituan.com/
---------- END ----------