线性模型分析
线性模型分析
摘要
线性模型是线性统计模型的一种简称,是数理统计学中研究变量之间关系的一种模型,在线性模型中,未知参数以线性形式出现。本文主要分析和介绍机器学习中两种经典的线性模型:线性回归模型的逻辑回归模型,并结合实际应用场景,用代码实现这两种模型的训练过程。
1、线性模型的基本形式
线性模型形式简单,易于理解,是机器学习中非常基础的部分,许多复杂的非线性模型都是在线性模型的基础上通过引入层级结构或高维映射得来的。
线性模型对于给定的d个属性描述的值x=( x1,x2,…,xd x 1 , x 2 , … , x d ),通过属性的线性组合来预测。一般的写法如下:
其中,参数w代表每个属性 xi x i 在预测过程中的重要程度,w越大,表示这个属性越重要,对预测结果的影响也越大。训练线性模型的过程,即求w和b的值的过程。
2、线性回归模型
①单变量线性回归
假设函数也称预测函数,是在线性回归过程中训练的模型。假设函数公式为:
假设函数也就是用来对输出结果进行进行预测的函数,公式中的θ表示模型参数,也是我们在训练线性模型过程中需要求的值,选择不同的θ,会得到不同的模型,模型学习的目的是求的使代价函数最小时的θ的值,从而得到一个能更好地与我们的数据拟合的模型。
代价函数即对模型的误差的度量,在训练模型过程中的目标是最小化代价函数。对于回归问题,我们常用的是平方误差代价函数。平方误差代价函数公式为:
下标n表示第n个特征,上标i表示第i个样本,m表示训练样本的总数。
我们的目标是最小化代价函数,求的 θ0,θ1 θ 0 , θ 1 的值,得到线性回归模型。
梯度下降算法是为了解决线性回归问题,将代价函数最小化,求出代价函数取最小值时的 θi θ i ,于是可得到线性回归的公式,取得最优解。梯度下降法公式为:
其中α代表线性回归模型的学习速率,符号:=表示将该符号后面的运算结果赋值给该符号前面的变量,每次同步计算 θ0 θ 0 到 θn θ n 的值,重复的进行计算,直到 θj θ j 的值不再改变,或者 θj θ j 的值的变化处于一个非常小的范围内,此时即得到代价函数 J(θ0,θ1) J ( θ 0 , θ 1 ) 的最小值,即可得到线性回归模型。
梯度下降算法的实现过程需要注意以下问题:
- 对 θ0,θ1 θ 0 , θ 1 做初步猜测,通常的做法是将它们初始化为0.对 θ0,θ1 θ 0 , θ 1 赋予某个值就是从曲面上的某一点出发;
- 不断改变 θ0,θ1 θ 0 , θ 1 ,使 J(θ0,θ1) J ( θ 0 , θ 1 ) 变小,直到找到 J(θ0,θ1) J ( θ 0 , θ 1 ) 的最小值或局部最小值;
- 不同的起点,即 θ0,θ1 θ 0 , θ 1 的初始值不同,会得到不同的局部最优点,这是梯度下降算法的一个特点,它得到的最优解不一定是全局最优解,很有可能是局部最优解;
- 在梯度啊下降的过程中,由于 J′(θ) J ′ ( θ ) 越来越小,θ的变化越来越小,梯度下降的幅度越来越小;
- 梯度下降算法可用于最小化任何代价函数J,不止是线性回归的代价函数。
下面通过代码实现梯度下降算法的执行过程。梯度下降过程中的主要代码如下所示,while循环中的判断条件的作用是确定运算的准确程度,当θ的变化值为0.0005,也就是接近0时,表面此时已接近代价函数的最小值,即可停止循环,得出结果。
while (abs(temp0-theta0)>0.0005 and abs(temp1-theta1)>0.0005):
#初始化theta0,theta1
theta0 = temp0
theta1 = temp1
#预测值与真实值的差
err0 = 0.0
err1 = 0.0
#累积计算差
for i in range(len(a)):
err0 = err0 + (theta0 + theta1*a[i][0] - a[i][1])*1.0
err1 = err1 + (theta0 + theta1*a[i][0] - a[i][1])*a[i][0]
temp0 = theta0 - learnRate/(len(a))*err0
temp1 = theta0 - learnRate/(len(a))*err1
学习速率决定模型学习的效率,在用户界面输入学习速率α,测试不同学习速率的输出结果。
如下图所示,当α取值太小时,梯度下降的过程非常缓慢:

如下图所示,当α取值很小时求得的 θ0,θ1 θ 0 , θ 1 的值:
![]()
如下图所示,当α取值太大时,梯度下降处于震荡的状态,无法求出正确的θ;
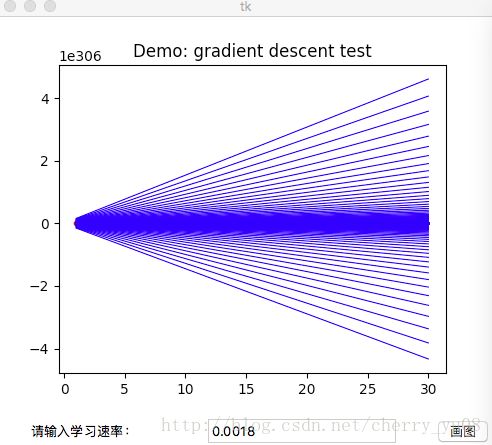
如下图所示,当α取值太小时,无法正确得出 θ0,θ1 θ 0 , θ 1 的值;
![]()
如下图所示,当α取到一个合适的值时,梯度下降可以很好地计算出正确的θ,得到预测函数,如图中黑色线段所示即为最终得到的预测函数:
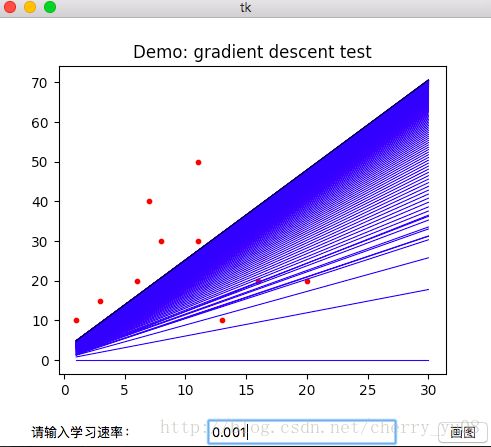
如下图所示,当α取合适的值时,可以很好地计算出 θ0,θ1 θ 0 , θ 1 的值;
![]()
②多变量线性回归
多变量线性回归模型对应多个变量的情况,在计算过程中一般使用矩阵乘法来解决问题。多变量线性回归在单变量线性回归的基础上,解决了多个特征的情况下,线性回归模型的拟合问题,是一种使用更广泛、更实用的线性回归模型。
假设函数的形式为:
将假设函数转化为矩阵相乘的形式为:
代价函数的形式为:
梯度下降函数的形式为:
3、对数几率回归模型(逻辑回归模型)
分类问题是监督学习的一个分支,在分类问题中,要预测的变量是离散的值,它可以取两个值,也可以取多个值,即分类问题可分为二分类问题和多类分类问题。对于分类问题,可使用映射函数将其转化为回归问题的形式,用回归模型解决问题。这里主要介绍逻辑回归模型。
①二分类问题
二分类问题的输出标记为(0,1)的形式,可在线性回归模型的基础上,引入逻辑函数来解决二分类问题,这种形式的模型称为对数几率模型,又名逻辑回归模型。
逻辑回归算法的函数形式由线性回归函数与逻辑函数相结合而得来的,它的形式为:
与线性回归模型一样,逻辑回归模型的目标是求出θ的值,用假设函数对输入变量作出预测。
逻辑回归问题的目标是拟合出一条决策边界,对数据集进行分类。决策边界表示逻辑回归模型的假设函数的作用,在逻辑回归中,假设函数的图形即为逻辑回归的决策边界,决策边界将整个平面分成两部分,分别对应而分类问题中的两类结果。决策边界是假设函数的一个属性,而不是数据集的属性。确定了决策边界,就可以根据输入值获取二分类问题的分类结果。
逻辑回归通过求使得代价函数取得最小值时的θ值,从而拟合出模型的最优解。代价函数的形式为:
代价函数的向量化形式为:
极大似然法用于离散问题,与求概率相关,逻辑回归模型的训练过程中可用极大似然法来求解代价函数。由于代价函数是高阶可导函数,根据凸优化理论,可有梯度下降算法、牛顿法来求得最优解。在这里我们使用梯度下降法,结合实际问题编写代码,完成逻辑回归模型的训练过程。
逻辑回归模型中梯度下降函数的形式为:
梯度下降函数的向量化形式为:
由于逻辑回归模型是在线性回归模型的基础上引入逻辑函数得来的,所以逻辑回归的梯度下降算法与线性回归的梯度下降算法基本相似,唯一的的区别在于 hθ(x) h θ ( x ) 不同,逻辑回归的 hθ(x) h θ ( x ) 引入了逻辑函数。
下面通过代码训练逻辑回归模型。梯度下降过程中的主要代码如下所示,while循环中的判断条件的作用是确定运算的准确程度,当θ的变化值为0. 000005,也就是接近0时,表面此时已接近代价函数的最小值,即可停止循环,得出结果。
while (abs(temp0-theta0)>0.000005 and abs(temp1- theta1)>0.000005 and abs(temp2-theta2)>0.000005):
theta0 = temp0
theta1 = temp1
theta2 = temp2
#预测值与真实值的差
err0 = 0.0
err1 = 0.0
err2 = 0.0
#累积计算差
for i in range(len(a)):
#假设函数
h = 1/(1+1/(np.e**(theta0+theta1*a[i][0]+theta2*a[i][1])))
#累积计算误差
err0 = err0 + (h - a[i][2])*1.0
err1 = err1 + (h - a[i][2])*a[i][0]
err2 = err2 + (h - a[i][2])*a[i][1]
temp0 = theta0 - learnRate/(len(a))*err0
temp1 = theta0 - learnRate/(len(a))*err1
temp2 = theta0 - learnRate/(len(a))*err2如下图所示,当α取到一个合适的值时,梯度下降可以很好地计算出正确的θ,得到预测函数,如图中蓝色线段所示即为最终得到的预测函数,即逻辑回归的决策边界,红色方块和绿色圆圈分别表示不同类别的标签,在决策边界上方的点属于绿色标签一类,在决策边界下方的点属于红色标签一类:
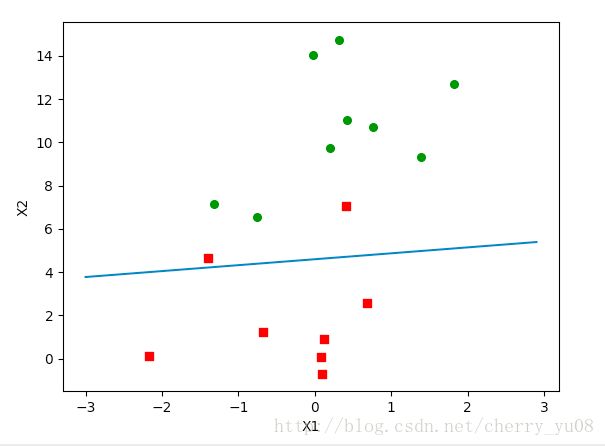
②多类别分类问题(一对多的分类算法)
在多类别分类问题中,要预测的变量有多个离散的取值。在逻辑回归中,对于多类别分类问题,使用较多的是一对多的分类算法,它的的原理是,每次将一个类别与其它类别分离,视作两个类别,模拟出逻辑回归模型进行分类,并多次进行这样的操作,知道将每个类别都单独地分离开来。
4、相关工作
线性回归模型与逻辑回归模型是监督学习中两种经典的线性模型,形式较简单,训练过程中难度不大,但主要问题在于如何提高模型的精确度。如上文线性回归模型的训练过程所示,不同的α值,会影响模型的学习速度,也会对训练结果的准确度造成影响。同时,在训练过程中,如果仅仅为了准确拟合训练数据集中的数据而提高准确度,可能会产生过拟合问题,这样的模型无法对训练数据集以外的数据做出很好的预测。
5、总结
线性模式看似简单,但它是学习其它复杂模型的基础,所以深入、透彻地理解线性模型非常重要。在线性回归模型和逻辑回归模型这两种模型的训练过程中,需要考虑的问题有很多,不仅需要考虑模型的精确度、避免过拟合,还需要考虑很多其它问题来减小训练误差,如线性回归模型的数据集不在一个训练集上,就需要用到特征缩放等。看似简单的模型,在训练过程中也需要细心和考虑周全,避免产生过大的误差。
参考文献
[1]《机器学习》.周志华.清华大学出版社.2016年01月
[2]《机器学习实战》. [美]哈林顿.人民邮电出版社.2013年06月
[3]Couesra课程《机器学习》.Andrew Ng