自然语言处理 cs224n 2019 Lecture 11: ConvNets for NLP
主要内容
- 公告
- CNN的介绍
- 用于句子分类的简单的cnn
- 各种不同的cnn
- 用于句子分类的深层cnn
- Quasi-recurrent Neural Networks
本节课视频语音声音字幕跟不上图像,看的很辛苦,到后半部分也没听太懂,老师的ppt很简单,都是说的,重要内容没贴上去
pytorch学习推荐书籍:
natural language processing with pytorch by O'REILLY
二、从RNN到卷积神经网络CNN
- 如果没有前缀信息,RNN捕捉不到句意
- 捕捉到的信息很多都是与最后一个单词相关的
- softmax通常都是在最后一步进行计算
- 如果我们为每个可能的单词子序列计算一定长度的向量呢
比如说句子:tentative deal reached to keep government open,计算向量:
tentative deal reached, deal reached to, reached to keep, to keep government, keep government open
不管句子的语法,然后再将他们组织起来
CNN
1层的卷积: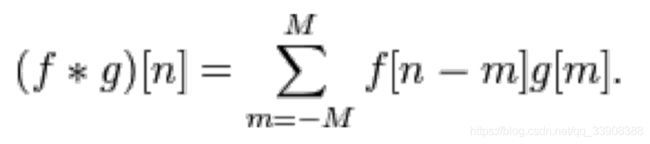
卷积通常用来从图像中抽取特征
2层卷积的例子:

黄色框中黑色数字乘红色数字=粉红色数字
绿色框中是输入(包括黄色框中的,这是绿色被黄色覆盖了),粉红色是输出
红色的就是过滤权重,也就是核
一层的卷积:
过滤器(或者核)尺寸是3,计算的右边的特征

带有填充的1层卷积

三通道的1层卷积,padding=1
也就是在两边各填充了1层0,可以防止对边缘信息提取不充分的问题
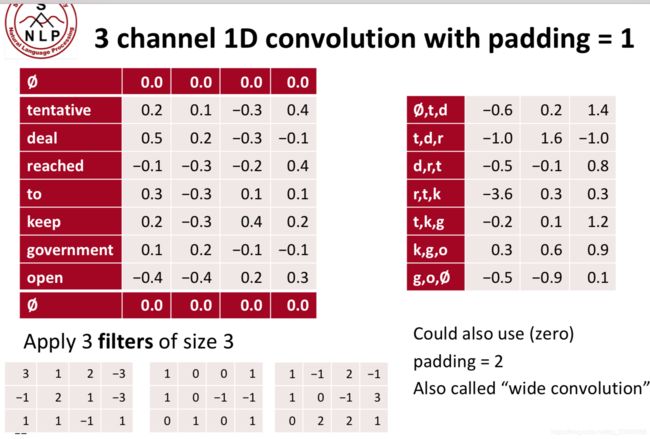
1层卷积,带有最大池化的填充
池化的概念:用于将经过卷积核计算出来的特征进一步压缩,比如将右上角的矩阵压缩成右下角的矩阵
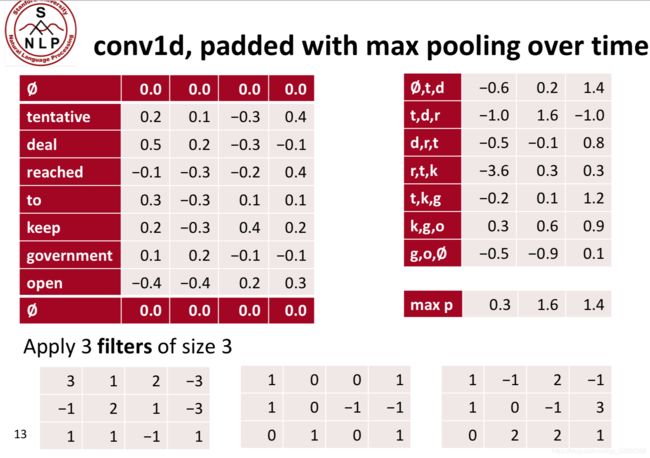
带有平均池化的填充
步长为2:
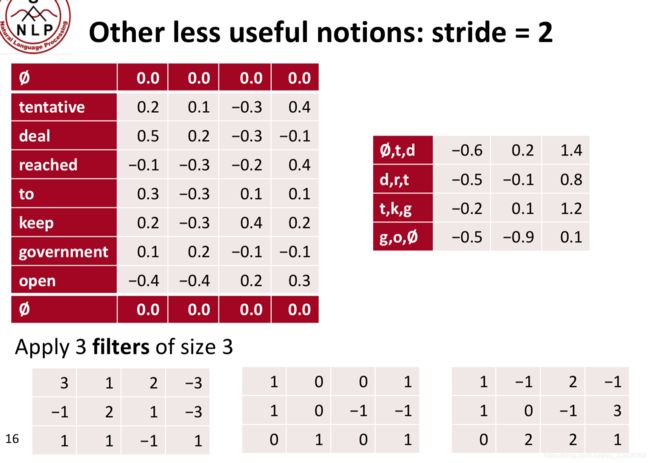
不常用的概念:本地最大池化
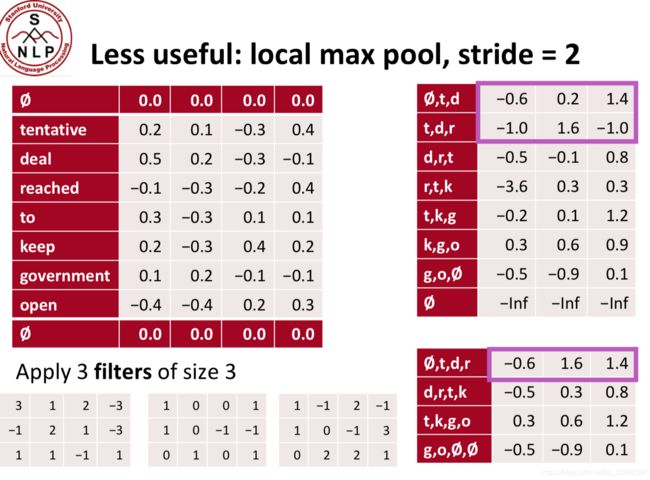
两个最大池:
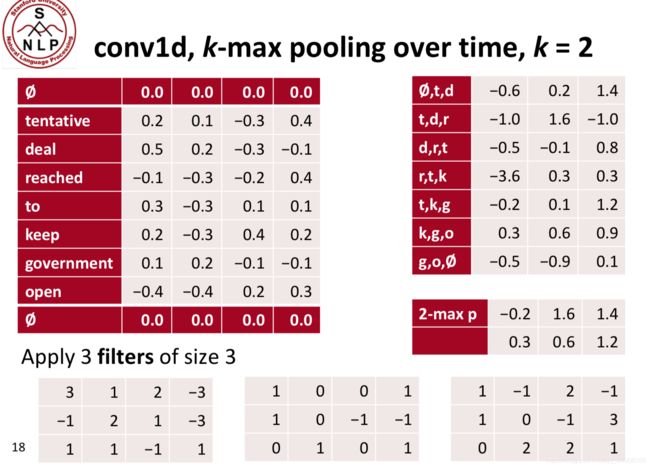
其他有用的概念:扩张卷积
使用右下角的两个矩阵和右上角的红色框做点乘,得到扩张结果

三、用于句子分类的单层网络
Yoon Kim (2014):Convolutional Neural Networks for Sentence Classification. EMNLP 2014.EMNLP 2014. https://arxiv.org/pdf/1408.5882.pdf Code: https://arxiv.org/pdf/1408.5882.pdf [Theano!, etc.]
上述论文研究的是使用单层卷积网络实现句子分类,判断句子是正面的还是负面的。
单层卷积网络的其他应用还有:
- 判断句子是主管的还是客观的
- 问题分类:关于人、位置、数字
单层CNN用于句子分类:
- 词向量:
 ,k是向量的维度
,k是向量的维度 - 句子:

- 分割的子序列:Xi:Xi+j,注意是是纵向拼接的,也就是把向量一层层堆叠起来的
- 卷积核:
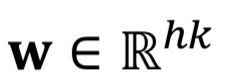 每个窗口有h个单词,也就是卷积核的尺寸为h
每个窗口有h个单词,也就是卷积核的尺寸为h
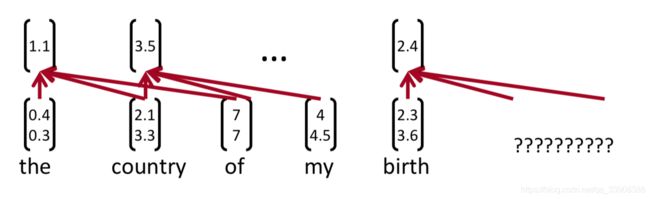
下面这个例子h=3

计算特征的公式:

所有可能的窗口:
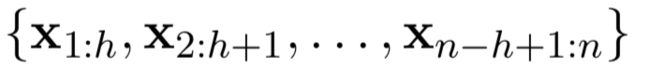
最终的结果是特征映射:
池化和通道
- 池化:从映射的特征中获取最重要的特征
- 最大池化的公式:

- 使用多种权重核w
- 有不同的窗口尺寸h是有意义的
- 因为最大池化是,c的长度是无关紧要的,可以一些过滤器,比如unigrams,bigrams,tri-grams,4-grams,等
- 多通道输入的想法
- 以预训练的向量初始化
- 仅仅通过一个小集合数据反向传播,其他不变
- 在最大池化之前两个通道的数据加起来变成ci
- 在一个卷积层之后的分类
在最大池化之前是一个卷积层
获取最终的特征向量: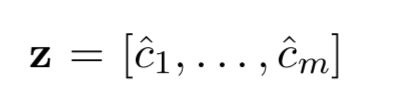
假设有m个核
之后是softmax层: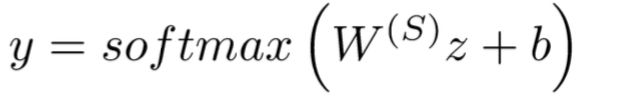
论文的模型:region size是2,3,4时分别取了两个不同的核进行过滤,得到的结果拼接起来
Zhang and Wallace (2015) A Sensitivity
Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification

正则化:
使用dropout。droup的原理和使用在另一篇博客里讲了
添加L2正则化约束
在Kim中的所有超参数
基于验证集找超参数
非线性化:ReLU
过滤器的窗口尺寸:3,4,5
每个过滤器尺寸有100个特征映射
dropout中 p=5,提升了2%-4%的准确率
L2对softmax中的行的限制了s,s=3
随机梯度下降的最小的批处理大小为:50
词向量:使用word2vec预训练词向量,k=300
在训练的时候检查在验证集上的性能,选择最高的准确度权重
模型比较:日益增长的工具包
- 向量词袋:对于单个分类问题效果挺好,特别是加了ReLU层之后
- 窗口模型:对不需要广泛的向下文的单个单词分类问题效果很好,比如POS, NER
- CNN:对分类效果很好,对于短文本需要0填充,很难解释,容易在GPUs上并行计算,效率高而且用途广泛
- RNN:从左边读到右边,有认知不全的问题,对分类效果不是很好(如果仅仅使用最后一个状态的话),比cnn慢,对语言模型效果很好,加入了注意力机制之后效果很好
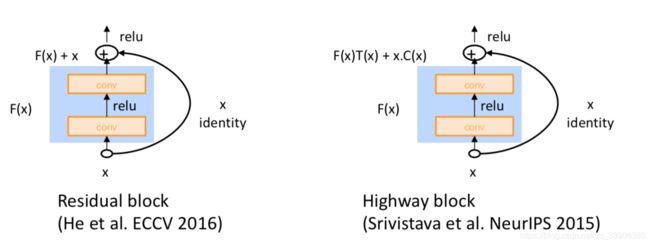
加入直接连接的门控单元
在LSTM和GRU中使用的跳跃连接被被广泛使用,对深度神经网络来说效果很好
批标准化
经常在RNN中使用
通过将激活量缩放为零均值和单位方差来转换卷积层的批输出,这个和数据处理中的Z-转换类似
这个方法使得模型对参数初始化不那么敏感,因为输出自动缩放了,它还倾向于简化学习速度的调整
-
PyTorch: nn.BatchNorm1d
1x1的卷积
这个概念有意义吗?有
卷积核为1x1
能减少通道的数量
CNN的应用:翻译
使用cnn作为编码器,rnn作为解码器

为部分演讲标记学习特征层的表示
六、RNN比较慢
因为RNN是串行的所以比较慢,可以将RNN和CNN结合起来
Quasi-Recurrent Netural Network
将两个模型的优点集合起来
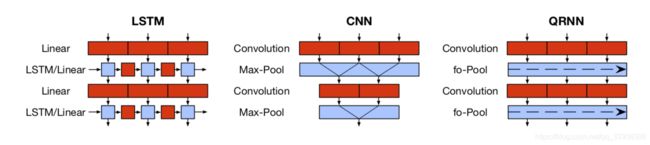
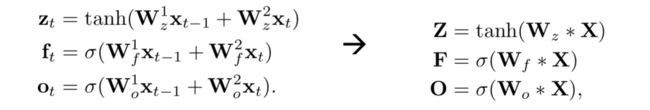
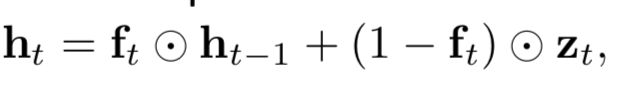
比LSTM更快和更好
更多的可解释性
缺点:
在字符级没有LSTM效果好,对长依赖处理不好
需要更深的网络层,但是仍然很快
我们想要并行化,但是RNNs本质上是顺序的
尽管有GRUs和LSTMs, RNNs仍然从处理远程依赖关系的注意机制中获益——状态之间的路径长度随顺序增长
但如果注意力能让我们进入任何一个状态……也许我们不需要RNN?