VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation
动机
Can we learn a meaningful context representation directly from the structured HD maps?
【CC】开宗明义提问,直接从结构化的HD MAP数据学习一个信息丰富的上下文(带动态ObjList)
This paper focuses on behavior prediction in complex multi-agent systems, such as self-driving vehicles.
The core interest is to find a unifified representation which integrates the agent dynamics, acquired by perception systems such as object detection and tracking, with the scene context, provided as prior knowledge often in the form of High Defifinition (HD) maps.
【CC】找到一种表示方法将HD Map结构化数据跟感知给出的动态的ObjList做到统一表达;然后,基于这个统一的表达做轨迹预测
This paper introduces VectorNet, a hierarchical graph neural network that first exploits the spatial locality of individual road components represented by vectors and then models the high-order interactions among all components.
【CC】道路结构(即静态的环境信息)和动态的车辆都被表达成了vector,在此表达的基础上做了GNN网络来表达各个元素间交互关系
We avoid lossy rendering and computationally intensive ConvNet encoding steps. To further boost VectorNet’s capability in learning context features, we propose a novel auxiliary task to recover the randomly masked out map entities and agent trajectories based on their context.
【CC】基于Conv的Encoder会丢失精度;这里采用类似MAE的做法去做表达训练增强
构思过程
For example, a lane boundary contains multiple control points that build a spline; a crosswalk is a polygon defined by several points; a stop sign is represented by a single point. All these geographic entities can be closely approximated as polylines defined by multiple control points, along with their attributes. Similarly, the dynamics of moving agents can also be approximated by polylines based on their motion trajectories. All these polylines can then be represented as sets of vectors.
【CC】从几何意义看,车道线包含多个控制点,交叉路口是个多边形(带多个顶点),交通标志是一个点,所有这些都可被近似-- 多个顶点多边形. 同样,动态Obj的轨迹也可被多边形近似。这种多边形都可以通过vector来表达。这里就是整个vector表达的底层逻辑

Figure 1. Illustration of the rasterized rendering (left) and vectorized approach (right) to represent high-definition map and agent trajectories.
We treat each vector as a node in the graph, and set the node features to be the start location and end location of each vector, along with other attributes such as polyline group id and semantic labels.
【CC】上面有了vector的表达,现在要构造上下文;而上下文的表达比较自然的方式也就是Graph了。一组vector就是graph中的一个node(这个Node如何进行构建下面有解答)。如果采用Graph的方式,在Obj动态驶入/驶出的场景下,难道可以在已有grapgh上动态的增删节点然后进行推理?后面有解答
We observe that it is important to constrain the connectivities of the graph based on the spatial and semantic proximity of the nodes. We therefore propose a hierarchical graph architecture, where the vectors belonging to the same polylines with the same semantic labels are connected and embedded into polyline features, and all polylines are then fully connected with each other to exchange information. We implement the local graphs with multi-layer perceptrons, and the global graphs with self-attention.
【CC】这里讲graph如何构造,作者发现地理位置相近&语义相近的多边形作为Node去构造graph比较重要。属于同一多边形并且语义相近的vector做全连接,把属性编入多边形的特征中,多边形间做全连接
We propose an auxiliary graph completion objective in addition to the behavior prediction objective. More specifically, we randomly mask out the input node features belonging to either scene context or agent trajectories, and ask the model to reconstruct the masked features. The intuition is to encourage the graph networks to better capture the interactions between agent dynamics and scene context.
【CC】类似MAE的做法,随机抹除一些Node让这个NN去做估计;训练出来的NN能够更好的做表达:Node间的交互和上下文的刻画
MultiPath also uses ConvNets as encoder,but adopts pre-defined trajectory anchors to regress multiple possible future trajectories.
【CC】怎么能让 multipath跟vectornet结合? 关键是 pre-define的anchor怎么在vectornet上表达?其本质也是point,既然是Point就能通过vector来表达! 但是它的预测方式就要变掉
Representing trajectories and maps
Most of the annotations from an HD map are in the form of splines (e.g. lanes), closed shape (e.g. regions of intersections) and points (e.g. traffic lights), with additional attribute information such as the semantic labels of the annotations and their current states (e.g. color of the trafficlight, speed limit of the road). For agents, their trajectories are in the form of directed splines with respect to time.
【CC】经典HD MAP的表达方式:splines/shape/point 附带一些语义属性(红绿灯/限速);经典轨迹的表达:splines 带时间信息
For map features, we pick a starting point and direction, uniformly sample key points from the splines at the same spatial distance, and sequentially connect the neighboring key points into vectors; for trajectories, we can just sample key points with a fixed temporal interval (0.1 second), starting from t = 0, and connect them into vectors.
【CC】上面这些结构化信息如何vector化呢?采样。基于spline就等间距采样,基于轨迹就等时间采样
Our vectorization process is a one-to-one mapping between continuous trajectories, map annotations
【CC】对HD MAP元素1对1的采样
We treat each vector vi belonging to a polyline Pj as a node in the graph with node features given by

where dsi and dei are coordinates of the start and end points of the vector, d itself can be represented as (x, y) for 2D coordinates or (x, y, z) for 3D coordinates; ai correspondsto attribute features, such as object type, timestamps for trajectories, or road feature type or speed limit for lanes; j is the integer id of Pj , indicating vi ∈ Pj . To make the input node features invariant to the locations of target agents, we normalize the coordinates of all vectors to be centered around the location of target agent at its last
observed time step.
【cc】dsi/dei起始点的坐标;ai特征信息,比如限速/车道等; j是在多边形P中的下标。
Constructing the polyline subgraphs
We take a hierarchical approach by first constructing subgraphs at the vector level, where all vector nodes belonging to the same polyline are connected with each other.
【CC】最下层的子图,处理同一多边形的所有vector,并且vector间全连接
Considering a polyline P with its nodes {v1, v2, …, vP }, we define a single layer of subgraph propagation operation as

where vi(l) is the node feature for l-th layer of the subgraph network, and vi(0) is the input features vi. Function genc(·) transforms the individual node features, ϕagg(·) aggregates the information from all neighboring nodes, and ϕrel(·) is the relational operator between node vi and its neighbors.
【CC】vi(l)是第l层的特征;genc单节点的特征提取函数,ϕagg所有邻接点特征聚合函数,ϕrel节点跟其邻接点的关系函数
In practice, genc(·) is a multi-layer perceptron (MLP) whose weights are shared over all nodes; ϕagg(·) is the maxpooling operation, and ϕrel(·) is a simple concatenation.
【CC】从实现角度:genc是一个MLP,ϕagg 是一个maxPooling,ϕrel简单的全连接; MLP的权重在一个多边形里面是一个
An illustration is shown in Figure 3. We stack multiple layers of the subgraph networks, where the weights for genc(·) are different. Finally, to obtain polyline level features, we compute

where ϕagg(·) is again maxpooling

Figure 3. The computation flow on the vector nodes of the same polyline.
【CC】经过MLP-Pooling-Concat 得到多边形的特征P
Global graph for high-order interactions
We now consider modeling the high-order interactions on the polyline node features {p1, p2, …, pP } with a global interaction graph:

where {p(il)} is the set of polyline node features, GNN(·)corresponds to a single layer of a graph neural network, and A corresponds to the adjacency matrix for the set of polyline nodes.
【CC】A是多边形节点的邻接阵,通过GNN去处理第l层的节点Pil,得到其交互后的特征
The adjacency matrix A can be provided a heuristic, such as using the spatial distances between the nodes. For simplicity, we assume A to be a fully-connected graph
【CC】A的设计比较考究,可以按照距离来也可按照其他(比如通过网络学习一个出来),这里简单用全连接来处理
Our graph network is implemented as a self-attention operation
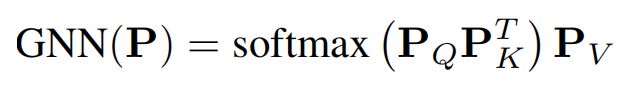
where P is the node feature matrix and PQ, PK and PV are its linear projections.
【CC】GNN就使用简单的self-attention来实现(这样的话节点个数可以动态); P是所有节点的合起来的特征阵,PQ/PK/PV分别是Query/Key/Vaule的特征分量
We then decode the future trajectories from the nodes corresponding the moving agents:
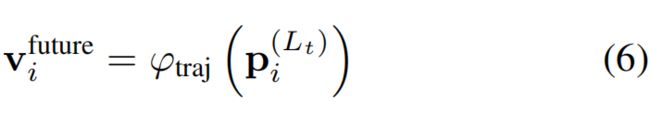
where Lt is the number of the total number of GNN layers, and ϕtraj(·) is the trajectory decoder. For simplicity, we use an MLP as the decoder function.
【CC】讲节点i的特征值decode成对应的vector,简单用MLP来实现
We use a single GNN layer in our implementation, so that during inference time, only the node features corresponding to the target agents need to be computed. However, we can also stack multiple layers of GNN(·) to model higher-order interactions when needed.
【CC】使用了单层的attention来实现;当然也可以做的很复杂
During training time, we randomly mask out the features for a subset of polyline nodes, e.g. pi. We then attempt to recover its masked out feature as:
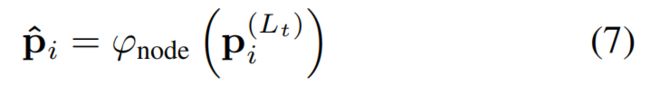
where ϕnode(·) is the node feature decoder implemented as an MLP.
【CC】类似MAE的做法,随机的抹除一部分节点,通过ϕnode来估计本层的特征;ϕnode是个简单的MLP
When its corresponding feature is masked out, we compute the minimum values of the start coordinates from
all of its belonging vectors to obtain the identifier embedding p-id-i. The inputs node features then become
【CC】这是Pi的编号规则:使用其实点坐标最小的那个vector的下标
Overall framework
Once the hierarchical graph network is constructed, we optimize for the multi-task training objective
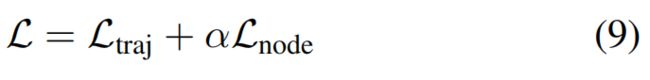
where Ltraj is the negative Gaussian log-likelihood for the groundtruth future trajectories, Lnode is the Huber loss
between predicted node features and groundtruth masked node features, and α = 1.0 is a scalar that balances the two loss terms. To avoid trivial solutions for Lnode by lowering the magnitude of node features, we L2 normalize the polyline node features before feeding them to the global graph network.
【CC】这里两个目标函数形式要注意,一个是高斯近似,一个是HuberLoss;另, 在进入GNN前对多边形的特征做了L2正则

Figure 2. An overview of our proposed VectorNet. Observed agent trajectories and map features are represented as sequence of vectors, and passed to a local graph network to obtain polyline-level features. Such features are then passed to a fully-connected graph to model the higher-order interactions. We compute two types of losses: predicting future trajectories from the node features corresponding to the moving agents and predicting the node features when their features are masked out.
【CC】不做解释了