Keras 手写数字辨识
Keras 手写数字辨识
库文件:
from keras import layers
from keras import Input
from keras import Model
from keras import optimizers
import numpy as np
import matplotlib.pyplot as plt
主要网络层:
| 网络层 | 名称 |
|---|---|
| Dense | 密集层 |
| Flatten | Flatten层(降维处理) |
| Dropout | Dorpout层(过拟合处理) |
| Conv1D | 一维卷积层 |
| Conv2D | 二维卷积层 |
| Conv3D | 三维卷积层 |
| MaxPooling1D | 一维最大池化层 |
| MaxPooling2D | 二维最大池化层 |
| MaxPooling3D | 三维最大池化层 |
| AveragePooling1D | 一维平均池化层 |
| AveragePooling2D | 二维平均池化层 |
| AveragePooling3D | 三维平均池化层 |
| GlobalMaxPooling1D | 一维全局最大池化层 |
| GlobalMaxPooling2D | 二维全局最大池化层 |
| GlobalMaxPooling3D | 三维全局最大池化层 |
| SimpleRNN | 全连接RNN层 |
| LSTM | 长短期记忆层 |
| Embedding | 嵌入层 |
from keras import Input
from keras import Model
这两句是函数式API都需要引入的库文件
Input 是输入形式的定义
Model 是模型的建立
from keras import optimizers
该语句是专门设置优化器属性的库文件
import numpy as np
该语句主要是处理数据,比如标准化等
一般还有
import pandas as pd
import matplotlib.pyplot as plt
该语句是用于显示图形
import os,shutil
一般文件处理的库文件
from keras.preprocessing import image
一般图像文件处理的库文件
数据导入及预处理:
from keras.datasets import mnist
(train_images,train_labels) , (test_images,test_labels) = mnist.load_data()
def one_hot(labels):
temp = labels.shape
to_one_hot = np.zeros((temp[0],10))
for i in range(temp[0]):
to_one_hot[i,labels[i]] = 1
return to_one_hot
validation_images = train_images[20000:30000]
validation_labels = train_labels[20000:30000]
train_images = np.concatenate([train_images[:20000],train_images[30000:]],axis=0)
train_labels = np.concatenate([train_labels[:20000],train_labels[30000:]],axis=0)
temp = train_images[0].shape
validation_images = validation_images.reshape((-1,temp[0],temp[1],1)).astype('float32')/255
train_images = train_images.reshape((-1,temp[0],temp[1],1)).astype('float32')/255
test_images = test_images.reshape((-1,temp[0],temp[1],1)).astype('float32')/255
train_labels = one_hot(train_labels)
validation_labels = one_hot(validation_labels)
test_labels = one_hot(test_labels)
from keras.datasets import mnist
(train_images,train_labels) , (test_images,test_labels) = mnist.load_data()
该语句是导入数据,这里笔者使用内置的数据集,第一次运行它会自动下载
def one_hot(labels):
temp = labels.shape
to_one_hot = np.zeros((temp[0],10))
for i in range(temp[0]):
to_one_hot[i,labels[i]] = 1
return to_one_hot
该语句是处理标签数据,即进行one-hot编码,因为它的输出只有是个特征
validation_images = train_images[20000:30000]
validation_labels = train_labels[20000:30000]
train_images = np.concatenate([train_images[:20000],train_images[30000:]],axis=0)
train_labels = np.concatenate([train_labels[:20000],train_labels[30000:]],axis=0)
temp = train_images[0].shape
validation_images = validation_images.reshape((-1,temp[0],temp[1],1)).astype('float32')/255
train_images = train_images.reshape((-1,temp[0],temp[1],1)).astype('float32')/255
test_images = test_images.reshape((-1,temp[0],temp[1],1)).astype('float32')/255
train_labels = one_hot(train_labels)
validation_labels = one_hot(validation_labels)
test_labels = one_hot(test_labels)
以上为数据处理过程,主要目的就是为了让计算机理解,一般因实际问题而异,主要需要掌握的是特征工程有关方面的算法
input_tensor = Input(shape=(28,28,1))
x1 = layers.Conv2D(128,(3,3),activation='relu')(input_tensor)
x2 = layers.MaxPooling2D((2,2))(x1)
x3 = layers.Conv2D(256,(3,3),activation='relu')(x2)
x4 = layers.MaxPooling2D((2,2))(x3)
x5 = layers.Flatten()(x4)
x6 = layers.Dropout(0.5)(x5)
x7 = layers.Dense(512,activation='relu')(x6)
output_tensor = layers.Dense(10,activation='softmax',name='out')(x7)
model = Model(inputs=input_tensor,outputs=output_tensor,name='mnist model')
#model.summary()
# 构建编译器
model.compile(optimizer=optimizers.RMSprop(lr=1e-4),
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练过程
history = model.fit(train_images,
train_labels,
epochs=10,
batch_size=200,
validation_data=(validation_images,validation_labels))
以下为本例题的网络架构:
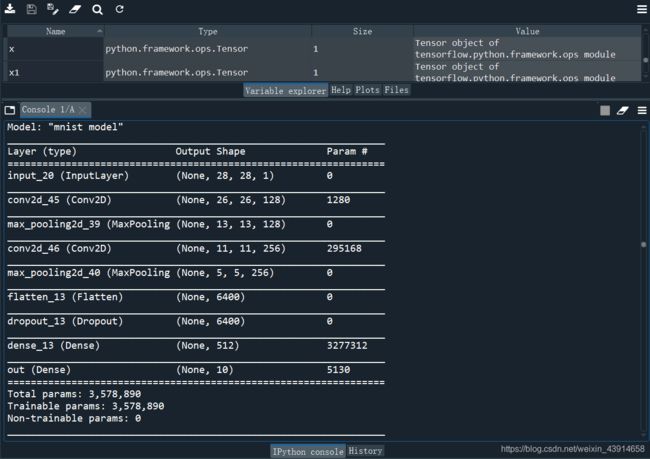
input_tensor = Input(shape=(28,28,1))
x1 = layers.Conv2D(128,(3,3),activation='relu')(input_tensor)
x2 = layers.MaxPooling2D((2,2))(x1)
x3 = layers.Conv2D(256,(3,3),activation='relu')(x2)
x4 = layers.MaxPooling2D((2,2))(x3)
x5 = layers.Flatten()(x4)
x6 = layers.Dropout(0.5)(x5)
x7 = layers.Dense(512,activation='relu')(x6)
output_tensor = layers.Dense(10,activation='softmax',name='out')(x7)
构建模型过程,面对不同数据类型,网络架构一般也不相同
向量数据:密集连接网络
图像数据:二维卷积神经网络
声音数据:一维卷积神经网络或者循环神经网络
文本数据:一维卷积神经网络或者循环神经网络
时间序列数据:循环神经网络或者一维卷积神经网络
视频数据:三维卷积神经网络
立体数据: 三维卷积神经网络
激活函数选择:
sigmoid 函数 [0,1]
tanh 函数 [-1,1]
relu 函数 深度学习常用
softmax 函数 多分类
softplus 函数 [0,inf]
linear 函数 最简单
主流的激活函数可以如上述例子一样通过名称直接使用,
但是还有一些复杂的激活函数如:
Leaky ReLU、PReLU是不可以这样直接使用的,
必须将高级激活函数作为层(layer)来使用
首先需要引入库文件
列题:
from keras import Input
from keras import Model
from keras import layers
from keras.layers import LeakyReLU
from keras.layers import PReLU #可学习,故相当于一层神经网络
input_tensor = Input(shape=(100,100))
x = layers.Dense(128)(input_tensor)
out_x = LeakyReLU(alpha=0.05)(x)
y = layers.Dense(128)(input_tensor)
out_y = PReLU()(y)
output_tensor = layers.concatenate([out_x,out_y],axis=1)
model = Model(input_tensor,output_tensor)
model.summary()
model.compile(optimizer=optimizers.RMSprop(lr=1e-4), loss='categorical_crossentropy', metrics=['accuracy'])
以上为构建编译器,搭建优化器类型,损失函数以及准确度度量类型等,以及调整超参数,如调整学习率
常见的损失函数有:
mean_squared_error或mse
mean_absolute_error或mae
mean_absolute_percentage_error或mape
mean_squared_logarithmic_error或msle
binary_crossentropy 亦称作对数损失,用于二分类问题
categorical_crossentropy:亦称作多类的对数损失,用于多分类问题
sparse_categorical_crossentrop
常见的优化器有:
SGD
RMSprop
Adam
Adadelta
Adagrad
history = model.fit(train_images, train_labels, epochs=10, batch_size=200, validation_data=(validation_images,validation_labels))
fit函数用于训练模型,返回一个History的对象,有点类似于字典,记录了损失函数和其他指标的数值随epoch变化的情况, 如果有验证集的话,也包含了验证集的这些指标变化情况 与之类似的训练函数还有model.fit_generator()函数,在数据量非常大时, 使用 Python 生成器(或 Sequence 实例)逐批生成的数据,按批次训练模型。 生成器与模型并行运行,以提高效率。
val_loss = history.history['val_loss']
loss = history.history['loss']
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.plot(range(len(loss)),loss,'r',label='training loss')
plt.plot(range(len(val_loss)),val_loss,'b',label='validation loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
plt.figure()
plt.plot(range(len(acc)),acc,'r',label='training accuracy')
plt.plot(range(len(val_acc)),val_acc,'b',label='validation accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend()
plt.show()
# 模型评估
loss,acc = model.evaluate(test_images,test_labels)
print('测试集上的精度为:{},测试集上的损失值为:{}'.format(acc,loss))
# 模型保存
model.save("D:\深度学习模型\手写数字辨识.h5")
val_loss = history.history['val_loss']
loss = history.history['loss']
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.plot(range(len(loss)),loss,'r',label='training loss')
plt.plot(range(len(val_loss)),val_loss,'b',label='validation loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
plt.figure()
plt.plot(range(len(acc)),acc,'r',label='training accuracy')
plt.plot(range(len(val_acc)),val_acc,'b',label='validation accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend()
plt.show()
结果图像显示,和matlab操作类似
loss,acc = model.evaluate(test_images,test_labels)
print('测试集上的精度为:{},测试集上的损失值为:{}'.format(acc,loss))
最终在测试集上评估效果
model.save("D:\深度学习模型\手写数字辨识.h5")
模型的保存是一个好习惯
对于加载模型,如下代码
from keras.models import load_model
model = load_model("D:\深度学习模型\手写数字辨识.h5")
过拟合解决方法:正则化
1.L1和L2正则:L1正则化和L2正则化可以看做是损失函数的惩罚项,依据是奥克姆剃刀原理。L1正则化是指权值向量w中各个元素的绝对值之和,L2正则化是指权值向量w中各个元素的平方和然后再求平方根,即在损失函数后面添加上述相应的罚函数,以下代码,参数代表罚函数权重
from keras import regularizers
# L1正则化
regularizers.l1(0.001)
# 同时做L1和L2正则化
regularizers.l1_l2(l1=0.001,l2=0.001)
2.dropout:深度学习中最常用的正则化技术是dropout,即让某个神经元的激活值以一定的概率p停止更新。以下代码,笔者定义了一个顺序架构,设定p为0.05
from keras import layers
from keras import models
p = 0.05
model = models.Sequential()
model.add(layers.Dense(128,activation='relu',input_dim=1))
model.add(layers.Dropout(p))
model.add(layers.Dense(1,activation='sigmoid'))
model.summary()
3.数据增强,比如将原始图像翻转平移拉伸,从而是模型的训练数据集增大。它的作用可以增加训练的数据量,提高模型的泛化能力,但是不必做的太过,将原始数据量通过数据增加增加到2倍即可,如果增加十倍百倍就只是增加了训练所需的时间,并不会继续增加模型的泛化能力。笔者利用ImageDataGenerator来设置数据增强,如下代码:
from keras.preprocessing.image import ImageDataGenerator
data_sets = ImageDataGenerator(
rotation_range=30, # 随机旋转最大角度值,这里图片旋转的随机角度区间为[0,30]
width_shift_range=0.3, #
height_shift_range=0.3, # 水平和垂直方向的随机平移范围
shear_range=0.3, # 随机错切变换的角度
zoom_range=0.3, # 图像随机缩放的范围
horizontal_flip=True, # 随机将图像沿水平翻转
fill_mode='nearest' # 用于填充像素,这里像素填充是依靠邻近像素值填充
)
4.提前停止:观察评估值,选择模型在训练的某个阶段就停止训练,如果继续训练带来提升不大或者连续几轮训练都不带来提升的时候,这样可以避免只是改进了训练集的指标但降低了验证集的指标。
卷积神经网络可视化
主要有以下三种途径:
1.可视化卷积神经网络的中间输出(中间激活):有助于理解卷积神经网络连续的层如何对输入进行变换,也有助于初步了解卷积神经网络每个过滤器的含义。
2.可视化卷积神经网络的过滤器:有助于精确理解卷积神经网络中每个过滤器容易接受的视觉模式或视觉概念。
3.可视化图像中类激活的热力图:有助于理解图像的哪个部分被识别为属于某个类别,从而可以定位图像中的物体。
笔者出于篇幅有限,以下代码只是第一种方式可视化:
# -*- coding: utf-8 -*-
# 这是新的文件
from keras.datasets import mnist
import matplotlib.pyplot as plt
from keras.models import load_model
from keras import models
import numpy as np
# 导入数据
(_,_) , (test_images,test_labels) = mnist.load_data()
# 查看图片
img_tensor = test_images[100].astype('float32')/255
plt.matshow(img_tensor)
# 载入模型
model = load_model("D:\深度学习模型\手写数字辨识.h5")
model.summary()
# 这里的模型只有五层卷积层,记得去除第一个输入层
layer_outputs = [layer.output for layer in model.layers[1:5]]
activation_model = models.Model(inputs=model.input,outputs=layer_outputs)
img_tensor = img_tensor.reshape((1,img_tensor.shape[0],img_tensor.shape[1],1))
activations = activation_model.predict(img_tensor)
'''
first_layer_activation = activations[0]
second_layer_activation = activations[1]
print(first_layer_activation.shape)
print(second_layer_activation.shape)
'''
layer_names = []
for layer in model.layers[1:5]:
layer_names.append(layer.name)
images_per_row = 16
for layer_name,layer_activation in zip(layer_names,activations):
n_features = layer_activation.shape[-1]
size = layer_activation.shape[1]
n_cols = n_features // images_per_row
display_grid = np.zeros((size*n_cols,images_per_row*size))
for col in range(n_cols):
for row in range(images_per_row):
channel_image = layer_activation[0,:,:,
col*images_per_row+row]
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image,0,255).astype('uint8')
display_grid[col * size:(col + 1) * size,
row * size :(row + 1) * size] = channel_image
scale = 1./size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid,aspect='auto',cmap='viridis')
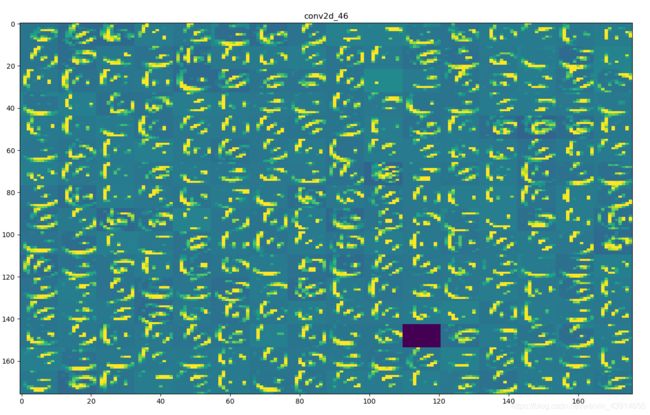
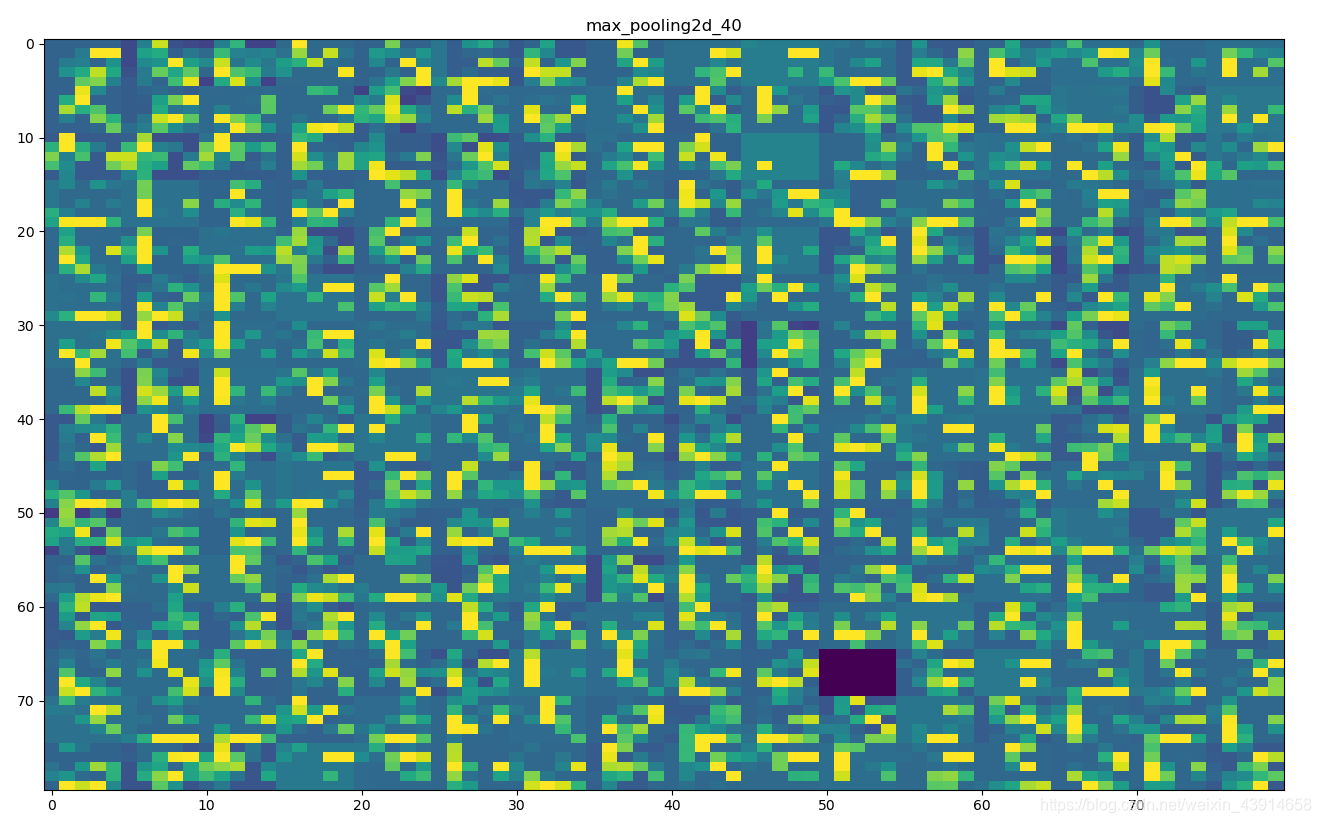
选择的可视化图片为:
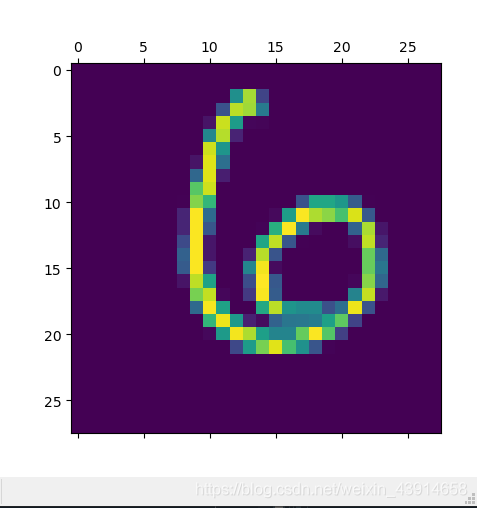
第一层卷积层:

第一层最大池化层:

第二层卷积层:
第二层最大池化层:
完整代码如下:
# -*- coding: utf-8 -*-
from keras import layers
from keras import Input
from keras import Model
from keras import optimizers
import numpy as np
import matplotlib.pyplot as plt
# 数据导入
from keras.datasets import mnist
(train_images,train_labels) , (test_images,test_labels) = mnist.load_data()
def one_hot(labels):
temp = labels.shape
to_one_hot = np.zeros((temp[0],10))
for i in range(temp[0]):
to_one_hot[i,labels[i]] = 1
return to_one_hot
validation_images = train_images[20000:30000]
validation_labels = train_labels[20000:30000]
train_images = np.concatenate([train_images[:20000],train_images[30000:]],axis=0)
train_labels = np.concatenate([train_labels[:20000],train_labels[30000:]],axis=0)
temp = train_images[0].shape
validation_images = validation_images.reshape((-1,temp[0],temp[1],1)).astype('float32')/255
train_images = train_images.reshape((-1,temp[0],temp[1],1)).astype('float32')/255
test_images = test_images.reshape((-1,temp[0],temp[1],1)).astype('float32')/255
train_labels = one_hot(train_labels)
validation_labels = one_hot(validation_labels)
test_labels = one_hot(test_labels)
# 构建模型 利用函数式API构建
input_tensor = Input(shape=(28,28,1))
x1 = layers.Conv2D(128,(3,3),activation='relu')(input_tensor)
x2 = layers.MaxPooling2D((2,2))(x1)
x3 = layers.Conv2D(256,(3,3),activation='relu')(x2)
x4 = layers.MaxPooling2D((2,2))(x3)
x5 = layers.Flatten()(x4)
x6 = layers.Dropout(0.5)(x5)
x7 = layers.Dense(512,activation='relu')(x6)
output_tensor = layers.Dense(10,activation='softmax',name='out')(x7)
model = Model(inputs=input_tensor,outputs=output_tensor,name='mnist model')
#model.summary()
# 构建编译器
model.compile(optimizer=optimizers.RMSprop(lr=1e-4),
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练过程
history = model.fit(train_images,
train_labels,
epochs=10,
batch_size=200,
validation_data=(validation_images,validation_labels))
# 绘制图形显示
val_loss = history.history['val_loss']
loss = history.history['loss']
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.plot(range(len(loss)),loss,'r',label='training loss')
plt.plot(range(len(val_loss)),val_loss,'b',label='validation loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
plt.figure()
plt.plot(range(len(acc)),acc,'r',label='training accuracy')
plt.plot(range(len(val_acc)),val_acc,'b',label='validation accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend()
plt.show()
# 模型评估
loss,acc = model.evaluate(test_images,test_labels)
print('测试集上的精度为:{},测试集上的损失值为:{}'.format(acc,loss))
# 模型保存
model.save("D:\深度学习模型\手写数字辨识.h5")
运行结果显示:
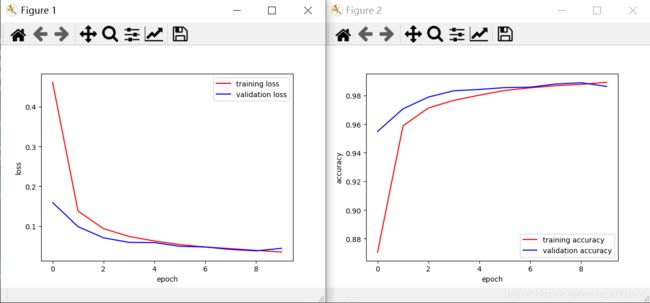
结果显示出来了,但是还没完,依靠数据,图像分析回调模型超参数也是一个不可缺失的过程,从上图看得出来,在第八轮的时候validation loss(验证集损失值)开始上升,validation accuracy(验证集准确度)开始下降,说明开始出现过拟合现象,也就是说,从这轮开始就可以停止训练了。