负对数似然(negative log-likelihood)
negative log likelihood
文章目录
- negative log likelihood
-
- 似然函数(likelihood function)
-
- Overview
- Definition
-
- 离散型概率分布(Discrete probability distributions)
- 连续型概率分布(Continuous probability distributions)
- 最大似然估计(Maximum Likelihood Estimation,MLE)
- 对数似然(log likelihood)
- 负对数似然(negative log-likelihood)
-
- Reference
似然函数(likelihood function)
Overview
在机器学习中,似然函数是一种关于模型中参数的函数。“似然性(likelihood)”和"概率(probability)"词意相似,但在统计学中它们有着完全不同的含义:概率用于在已知参数的情况下,预测接下来的观测结果;似然性用于根据一些观测结果,估计给定模型的参数可能值。
Probability is used to describe the plausibility of some data, given a value for the parameter. Likelihood is used to describe the plausibility of a value for the parameter, given some data.
—from wikipedia [ 3 ] ^[3] [3]
其数学形式表示为:
假设 X X X是观测结果序列,它的概率分布 f x f_{x} fx依赖于参数 θ \theta θ,则似然函数表示为
L ( θ ∣ x ) = f θ ( x ) = P θ ( X = x ) L(\theta|x)=f_{\theta}(x)=P_{\theta}(X=x) L(θ∣x)=fθ(x)=Pθ(X=x)
Definition
似然函数针对**离散型概率分布(Discrete probability distributions)和连续型概率分布(Continuous probability distributions)**的定义通常不同.
离散型概率分布(Discrete probability distributions)
假设 X X X是离散随机变量,其概率质量函数 p p p依赖于参数 θ \theta θ,则有
L ( θ ∣ x ) = p θ ( x ) = P θ ( X = x ) L(\theta|x)=p_{\theta}(x)=P_{\theta}(X=x) L(θ∣x)=pθ(x)=Pθ(X=x)
L ( θ ∣ x ) L(\theta|x) L(θ∣x)为参数 θ \theta θ的似然函数, x x x为随机变量 X X X的输出.
Sometimes the probability of "the value of for the parameter value " is written as P(X = x | θ) or P(X = x; θ).
连续型概率分布(Continuous probability distributions)
假设 X X X是连续概率分布的随机变量,其密度函数(density function) f f f依赖于参数 θ \theta θ,则有
L ( θ ∣ x ) = f θ ( x ) L(\theta|x)=f_{\theta}(x) L(θ∣x)=fθ(x)
最大似然估计(Maximum Likelihood Estimation,MLE)
假设每个观测结果 x x x是独立同分布的,通过似然函数 L ( θ ∣ x ) L(\theta|x) L(θ∣x)求使观测结果 X X X发生的概率最大的参数 θ \theta θ,即 a r g m a x θ f ( X ; θ ) argmax_{\theta}f(X;\theta) argmaxθf(X;θ) 。
在“模型已定,参数未知”的情况下,使用最大似然估计算法学习参数是比较普遍的。
对数似然(log likelihood)
由于对数函数具有单调递增的特点,对数函数和似然函数具有同一个最大值点。取对数是为了方便计算极大似然估计,MLE中直接求导比价困难,通常先取对数再求导,找到极值点。
负对数似然(negative log-likelihood)
实践中,softmax函数通常和负对数似然(negative log-likelihood,NLL)一起使用,这个损失函数非常有趣,如果我们将其与softmax的行为相关联起来一起理解.首先,让我们写下我们的损失函数:
L ( y ) = − l o g ( y ) L(y)=-log(y) L(y)=−log(y)
回想一下,当我们训练一个模型时,我们渴望能够找到使得损失函数最小的一组参数(在一个神经网络中,参数指权重weights和偏移biases).
对数函数如下图红线所示:

由于是对概率分布求对数,概率 p p p的值为 0 ≤ p ≤ 1 0\leq{p}\leq1 0≤p≤1,取对数后为红色线条在 [ 0 , 1 ] [0,1] [0,1]区间中的部分,再对其取负数,得到负对数似然函数如下图所示:
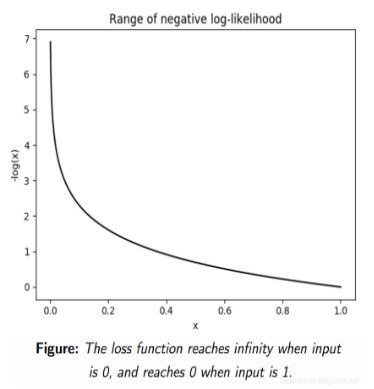
我们希望得到的概率越大越好,因此概率越接近于1,则函数整体值越接近于0,即使得损失函数取到最小值。
最大似然估计的一般步骤如下:
(1) 写出似然函数;
(2) 对似然函数取对数,得到对数似然函数;
(3) 求对数似然函数的关于参数组的偏导数,并令其为0,得到似然方程组;
(4) 解似然方程组,得到参数组的值.
Reference
[1]王海良,李卓恒,林旭鸣.智能问答与深度学习[M].北京:电子工业出版社,2019:19-20.
[2]Lj Miranda.Understanding softmax and the negative log-likelihood.2017.
[link]https://ljvmiranda921.github.io/notebook/2017/08/13/softmax-and-the-negative-log-likelihood/
[3]wikipedia-likelihood function
[link]https://en.wikipedia.org/wiki/Likelihood_function#Log-likelihood