Pytorch面试题面经
1.conv2d的实现:
接口定义:
class torch.nn.Conv2d(in_channels,
out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
bias=True)
参数说明:
- in_channels (int) – 输入通道个数。
- out_channels (int) – 输出通道个数 。有多少个out_channels,就需要多少个卷积(也就是卷积核的数量)
- kernel_size(int or tuple) –
卷积核的尺寸;卷积核的第二个维度由in_channels决定,所以实际上卷积核的大小为kernel_size * in_channels - stride (int or tuple, optional) – 卷积操作的步长, 默认:1
- padding (int or tuple, optional) – 输入数据各维度各边上要补齐0的层数,默认: 0
- dilation (int or tuple, optional) – 卷积核各元素之间的距离,默认: 1
- groups (int, optional) – 输入通道与输出通道之间相互隔离的连接的个数, 默认:1
- bias (bool, optional) – 如果被置为True,向输出增加一个偏差量,此偏差是可学习参数。 默认:True
channel的理解:
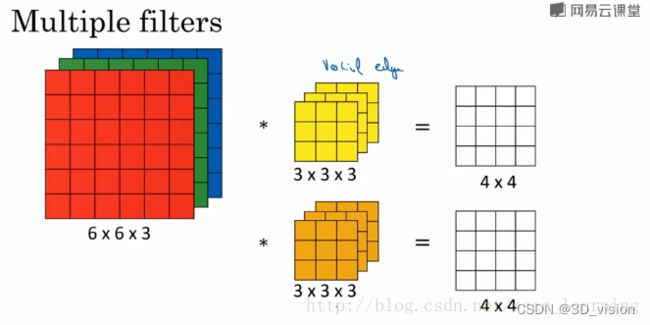
- 最初输入的图片样本的 channels ,取决于图片类型,比如RGB;
- 卷积操作完成后输出的 out_channels ,取决于卷积核的数量。此时的 out_channels 也会作为下一次卷积时的卷积核的 in_channels;
- 卷积核中的 in_channels ,刚刚2中已经说了,就是上一次卷积的 out_channels,如果是第一次做卷积,就是1中样本图片的 channels 。
2.pytorch如何微调fine tuning:
在加载了预训练模型参数之后,需要finetuning模型,可以使用不同的方式finetune:
局部微调: 加载了模型参数后,只想调节最后几层,其它层不训练,也就是不进行梯度计算,pytorch提供的requires_grad使得对训练的控制变得非常简单。
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
# 替换最后的全连接层, 改为训练100类
# 新构造的模块的参数默认requires_grad为True
model.fc = nn.Linear(512, 100)
# 只优化最后的分类层
optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
全局微调: 对全局微调时,只不过我们希望改换过的层和其他层的学习速率不一样,这时候把其它层和新层在optimizer中单独赋予不同的学习速率。
ignored_params = list(map(id, model.fc.parameters()))
base_params = filter(lambda p: id(p) not in ignored_params,
model.parameters())
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': model.fc.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
3.pytorch使用多gpu。
model.gpu() 把模型放在gpu上
model = nn . DataParallel ( model ) 。DataParallel并行的方式,是将输入一个batch的数据均分成多份,分别送到对应的GPU进行计算,各个GPU得到的梯度累加。与Module相关的所有数据也都会以浅复制的方式复制多份,在此需要注意,在module中属性应该是只读的。
对模型和相应的数据进行.cuda()处理,可以将内存中的数据复制到gpu显存中去
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model)
if torch.cuda.is_available():
model.cuda()
torch.nn:核心数据结构是Module,抽象的概念,既可以表示神经网络某个层layer,也可以表示一个包含很多层的神经网络。常见做法是继承nn.Module,编写自己的层。
- 自定义层必须继承nn.Module,并且在其构造函数中需调用nn.Module的构造函数,super(xx,self).init()
- 在构造函数__init__中必须自定义可学习的参数,并封装成Parameter
- forward函数实现前向传播过程,其输入可以是一个或者多个tensor。无需写反向传播函数,nn.Module能够利用autograd自动实现反向传播,这比function简单的多
- Module中可学习参数可以通过named_parameters()或者parameters()返回迭代器,前者会给每个parameter附上名字,使其更具有辨识度。
- pytorch实现了大部分的layer,这些layer都继承于nn.Module
nn.conv2d卷积层
AvgPool,Maxpool,AdaptiveAvgPool
TransposeConv逆卷积
nn.Linear全连接层
nn.BatchNorm1d(1d,2d,3d)
nn.dropout
nn.ReLU
nn.Sequential
nn.ModuleList(),可以包含几个子module,可以像list一样使用它,但不能直接把输入传给MuduleList
nn.LSTM(4,3,1) 输入向量4维,隐藏元3,1层 nn.LSTMCell(4,3) 对应层数只能是一层
nn.Embedding(4,5)4个词,每个词使用5个向量表示
损失函数也是nn.Module的子类。nn.CrossEntropLoss() loss = criterion(score,label)
torch.optim 将深度学习常用优化方法全部封装在torch.optim中,所有优化方法继承基类optim.Optimizer,并实现了自己的优化步骤
- optimizer = optim.SGD(param=net.parameters(),lr=1)
- optimizer.zero_grad() #梯度清零,等价于net.zero_grad()
- input = t.randn(1,3,32,32)
- output = net(input)
- output.backward(output)
- optimizer.step()
- 对不同网络设置不同学习率
# 为不同子网络设置不同的学习率,在finetune中经常用到
# 如果对某个参数不指定学习率,就使用最外层的默认学习率
optimizer =optim.SGD([
{'params': net.features.parameters()}, # 学习率为1e-5
{'params': net.classifier.parameters(), 'lr': 1e-2}
], lr=1e-5)
调整学习率的方法,两种
- 修改optimizer.param_groups中对应的学习率
- 新建优化器
# 方法1: 调整学习率,新建一个optimizer
old_lr = 0.1
optimizer1 =optim.SGD([
{'params': net.features.parameters()},
{'params': net.classifier.parameters(), 'lr': old_lr*0.1}
], lr=1e-5)
# 方法2: 调整学习率, 手动decay, 保存动量
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1 # 学习率为之前的0.1倍
nn.functional中的函数和nn.Module主要区别:
- nn.Module实现的layers是一个特殊的类,都是有class layer(nn.Module)定义,会自动提取可学习的参数
- nn.functional中的函数更像是纯函数,由def function(input)定义
- 也就是说如果模型有可学习的参数,最好用nn.Module否则使用哪个都可以,二者在性能上没多大差异,
- 对于卷积,全连接等具有可学习参数的网络建议使用nn.Module
- 激活函数(ReLU,sigmoid,tanh),池化等可以使用functional替代。对于不具有可学习参数的层,将他们用函数代替,这样可以不用放在构造函数__init__中。
如何在多个gpu上并行计算,pytorch提供 了两个函数,可实现简单高效的并行gpu计算
- nn.parallel.data_parallel(module, inputs, device_ids=None,
output_device=None, dim=0, module_kwargs=None) - class torch.nn.DataParallel(module, device_ids=None,
output_device=None, dim=0) - 通过device_ids参数可以指定在哪些gpu上优化
DataLoader函数
定义如下:对batch的数据进行操作,同时还需要对数据进行shuffle和并行加速等。
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False)
-
dataset:加载的数据集(Dataset对象)
-
batch_size:batch size
-
shuffle::是否将数据打乱
-
sampler: 样本抽样,后续会详细介绍
-
num_workers:使用多进程加载的进程数,0代表不使用多进程
-
collate_fn: 如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可
-
pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些
-
drop_last:dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃