主成分分析(principal component analysis, PCA)公式
主成分分析(principal component analysis, PCA)公式
- 主成分分析
-
- 摘要
- 什么是主成分
- 求解 PCA 的公式
- 数学证明
- 程序验证
- 参考文献
主成分分析
摘要
主成分分析作为一种常见的数据降维(dimension reduction)的方法,在数据科学的许多领域(比如图像压缩,时间序列预测等)都有广泛的应用。本文将简要介绍主成分分析的概念及相关公式。
什么是主成分
要对一组数据进行主成分分析(principal component analysis, PCA),我们首先要理解什么是主成分。概括地说,主成分是一个向量,这个向量在较低维度上概括了原来的较高维度数据的分布。假设我们的原始数据(红色的点)如下图中红色的点所示。
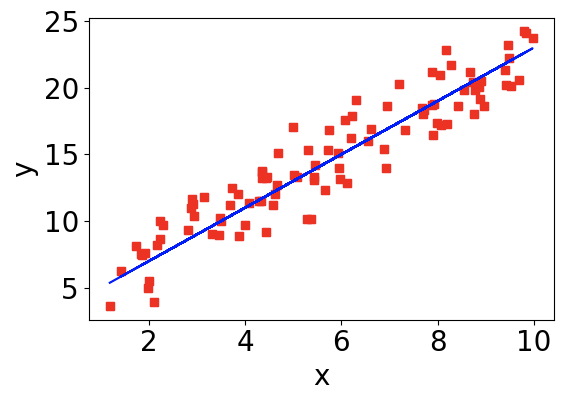
我们看到,每一个红色的点都有两个坐标,我们记为 ( x , y ) (x, \, y) (x,y)。但是我们发现红色点的分布可以用蓝色的直线来近似。如果对于每一个红色的点 ( x i , y i ) (x_i, \, y_i) (xi,yi),我们由 ( x i , y i ) (x_i, \, y_i) (xi,yi) 向蓝色的线做垂线(即做投影),那么我们将在蓝色的线上得到一个与 ( x i , y i ) (x_i, \, y_i) (xi,yi) 对应的点。如果我们在蓝色的线上规定一个原点,那么这个点在蓝色的线上对应的坐标就是一个实数,记为 z i z_i zi。于是,对于每一个红色的点 ( x i , y i ) (x_i, \, y_i) (xi,yi),我们有一个对应的点 z i z_i zi。这样,我们就把一个二维的数据转化为用一维数据来表示。这条蓝色的直线所代表的方向就是红色点集合的第一主成分。
对于三维的数据,类似的,我们同样可以根据数据点的分布找到能代表数据的主成分方向,如图2所示。图中蓝色的点代表原始的三维数据,而橙色的平面表示原始数据第一主成分与第二主成分所构成的平面。那么,我们将原始的数据向这个平面投影,每个三维的数据点 ( x i , y i , z i ) (x_i, \, y_i, \, z_i) (xi,yi,zi) 就会映射成一个二维的点 ( w 1 i , w 2 i ) (w_{1i}, \, w_{2i}) (w1i,w2i)。
通过上面两个例子,我们看到主成分分析可以帮助我们将原始的高维数据用低维的数据来表示,从而实现数据降维(dimension reduction)的目的。这在数据维度非常多的情况下,可以大大减少数据维度与存储空间。
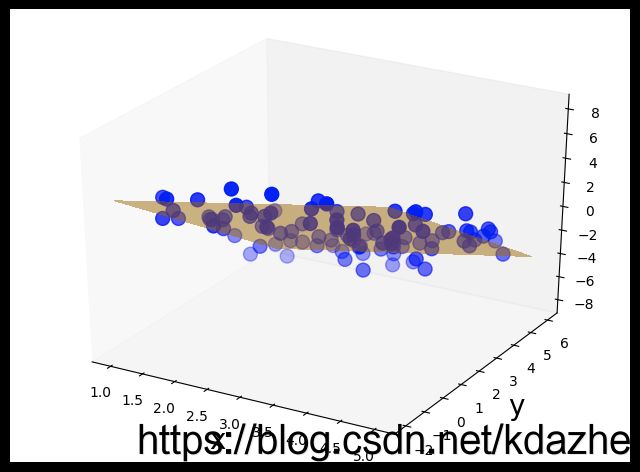
对于二维和三维的情况,我们尚且能通过画图看出数据的大致分布。但是对于 p p p 维 ( p ≥ 3 ) (p \geq 3) (p≥3) 的数据,我们不能将数据绘制出来。这时候怎么办呢?这正是我们须要用主成分分析(principal component analysis, PCA)的地方。PCA 可以帮助我们将高维的数据转化成低维的表示。
当然,在这个过程中,我们只是用低维数据去近似表示原来的高维数据。也就是说,我们筛选出了原来高维数据中信息含量最大的那些维度。
求解 PCA 的公式
怎么去求PCA中的主成分方向(或是主成分向量)呢?我们先将问题用数学化的语言来描述。假设我们有 n n n 个数据,数据的维度是 p p p。这 n n n 个数据所组成的矩阵记为 X X X。 X X X 是一个 n × p n \times p n×p 的矩阵。 X X X 的每一行代表一个数据。我们可以将矩阵 X X X 写成
X = ( X 1 , X 2 , ⋯ , X p ) \displaystyle X = (X_1, \, X_2, \, \cdots, \, X_p) X=(X1,X2,⋯,Xp)
这里的 X j , 1 ≤ j ≤ p X_j, \, 1 \leq j \leq p Xj,1≤j≤p 是一个 n × 1 n \times 1 n×1 的列向量,表示第 i i i 个 feature 在每一个数据点的值。为了方便起见,我们假设每一个 feature 在 n n n 个数据点测得的值的均值为0。于是 ∑ i = 1 n x i j = 0 , ∀ j = 1 , 2 , ⋯ , p \displaystyle \sum_{i = 1}^n x_{ij} = 0, \forall j = 1, \, 2, \, \cdots, \, p i=1∑nxij=0,∀j=1,2,⋯,p。那么,我们所要求的第一主值向量 ϕ 1 = ( ϕ 11 , ϕ 21 , ⋯ , ϕ p 1 ) T \phi_1 = (\phi_{11}, \phi_{21}, \cdots, \, \phi_{p1})^T ϕ1=(ϕ11,ϕ21,⋯,ϕp1)T 是使得线性映射
Z 1 = ϕ 11 X 1 + ϕ 21 X 2 + ⋯ + ϕ p 1 X p Z_1 = \phi_{11} X_1 + \phi_{21} X_2 + \cdots + \phi_{p1} X_p Z1=ϕ11X1+ϕ21X2+⋯+ϕp1Xp方差最大的那个向量 [1]。 注意,这里我们须要加一个限制条件,就是 ∑ i = 1 p ϕ i 1 2 = 1 \displaystyle \sum_{i = 1}^p \phi_{i1}^2 = 1 i=1∑pϕi12=1。否则,只要我们增大 ϕ i 1 \phi_{i1} ϕi1, Z 1 Z_1 Z1 的方差就可以变得无限大。
因为每个 X j X_j Xj 均为 n × 1 n \times 1 n×1 的向量,这里得到的 Z 1 Z_1 Z1 也将是一个 n × 1 n \times 1 n×1 的向量。我们记
Z 1 = ( z 11 z 21 ⋮ z n 1 ) Z_1 = \begin{pmatrix} z_{11} \\ z_{21} \\ \vdots \\ z_{n1} \\ \end{pmatrix} Z1=⎝ ⎛z11z21⋮zn1⎠ ⎞。
这里 z i 1 z_{i1} zi1 为 Z 1 Z_1 Z1 的第 i i i 个分量 ( i = 1 , 2 , ⋯ , n i = 1, 2, \cdots, \, n i=1,2,⋯,n),
z i 1 = ϕ 11 x i 1 + ϕ 21 x i 2 + ⋯ + ϕ p 1 x i p z_{i1} = \phi_{11} x_{i1} + \phi_{21} x_{i2} + \cdots + \phi_{p1} x_{ip} zi1=ϕ11xi1+ϕ21xi2+⋯+ϕp1xip。
事实上,我们可以将 Z 1 = ϕ 11 X 1 + ϕ 21 X 2 + ⋯ + ϕ p 1 X p Z_1 = \phi_{11} X_1 + \phi_{21} X_2 + \cdots + \phi_{p1} X_p Z1=ϕ11X1+ϕ21X2+⋯+ϕp1Xp 写成矩阵的形式: Z 1 = ϕ 11 X 1 + ϕ 21 X 2 + ⋯ + ϕ p 1 X p = X ϕ 1 Z_1 = \phi_{11} X_1 + \phi_{21} X_2 + \cdots + \phi_{p1} X_p = X \phi_1 Z1=ϕ11X1+ϕ21X2+⋯+ϕp1Xp=Xϕ1。
那么, Z 1 Z_1 Z1 的样本方差就为 1 n ∑ i = 1 n ( Z i 1 − E ( Z 1 ) ) 2 \frac{1}{n} \sum_{i = 1}^n (Z_{i1} - \mathbb{E}(Z_1))^2 n1∑i=1n(Zi1−E(Z1))2。 E ( Z 1 ) \mathbb{E}(Z_1) E(Z1) 是样本平均数。
要使得 Z 1 Z_1 Z1 的方差最大,我们须要找到 ( ϕ 11 , ϕ 21 , ⋯ , ϕ p 1 ) (\phi_{11}, \phi_{21}, \cdots, \, \phi_{p1}) (ϕ11,ϕ21,⋯,ϕp1),使得 1 n ∑ i = 1 n ( Z i 1 − E ( Z 1 ) ) 2 \frac{1}{n} \sum_{i = 1}^n (Z_{i1} - \mathbb{E}(Z_1))^2 n1∑i=1n(Zi1−E(Z1))2 最大。这样求解第一主成分的问题就转化成了最大化某个函数值的过程。我们注意到,
E ( Z 1 ) = 1 n ∑ i = 1 n z i 1 = 1 n ∑ i = 1 n ( ϕ 11 x i 1 + ϕ 21 x i 2 + ⋯ + ϕ p 1 x i p ) = 1 n ∑ i = 1 n ∑ j = 1 p ϕ j 1 x i j = 1 n ∑ j = 1 p ϕ j 1 ∑ i = 1 n x i j \begin{aligned} \displaystyle \mathbb{E}(Z_1) &= \frac{1}{n} \sum_{i = 1}^n z_{i1} \\ &= \frac{1}{n} \sum_{i = 1}^n ( \phi_{11} x_{i1} + \phi_{21} x_{i2} + \cdots + \phi_{p1} x_{ip}) \\ &= \frac{1}{n} \sum_{i = 1}^n \sum_{j = 1}^p \phi_{j1} x_{ij} \\ &= \frac{1}{n} \sum_{j = 1}^p \phi_{j1} \sum_{i = 1}^n x_{ij} \end{aligned} E(Z1)=n1i=1∑nzi1=n1i=1∑n(ϕ11xi1+ϕ21xi2+⋯+ϕp1xip)=n1i=1∑nj=1∑pϕj1xij=n1j=1∑pϕj1i=1∑nxij
但是根据上面我们的约定,每一个 feature 在 n n n 个数据点测得的值的均值为0。于是 ∑ i = 1 n x i j = 0 , ∀ j = 1 , 2 , ⋯ , p \displaystyle \sum_{i = 1}^n x_{ij} = 0, \forall j = 1, \, 2, \, \cdots, \, p i=1∑nxij=0,∀j=1,2,⋯,p。我们就有 E ( Z 1 ) = 0 \displaystyle \mathbb{E}(Z_1) =0 E(Z1)=0。我们的最大化问题随之变成了:
maximize ϕ 11 , ϕ 21 , ⋯ , ϕ p 1 1 n ∑ i = 1 n ( ∑ j = 1 p ϕ j 1 x i j ) 2 \underset{\phi_{11},\, \phi_{21}, \, \cdots, \phi_{p1}}{\text{maximize}} \frac{1}{n} \sum_{i = 1}^n \left(\sum_{j = 1}^p \phi_{j1} x_{ij} \right)^2 ϕ11,ϕ21,⋯,ϕp1maximizen1i=1∑n(j=1∑pϕj1xij)2
可以证明,这个最大化问题的解就是矩阵 1 n X T X \displaystyle \frac{1}{n} X^T X n1XTX 最大的那个特征值所对应的特征向量。我们称矩阵 1 n X T X \displaystyle \frac{1}{n} X^T X n1XTX 是 样本矩阵 X X X 的协方差矩阵。这个协方差矩阵是半正定的 (positive semidefinite)。所以它的特征值均是非负的。
数学证明
为什么矩阵 1 n X T X \displaystyle \frac{1}{n} X^T X n1XTX 最大的那个特征值所对应的特征向量就是第一主成分向量(即 ϕ 1 \phi_1 ϕ1)呢?这一部分我们将从数学上给出证明。
我们首先看要求的优化问题:
maximize ϕ 11 , ϕ 21 , ⋯ , ϕ p 1 1 n ∑ i = 1 n ( ∑ j = 1 p ϕ j 1 x i j ) 2 \underset{\phi_{11},\, \phi_{21}, \, \cdots, \phi_{p1}}{\text{maximize}} \frac{1}{n} \sum_{i = 1}^n \left(\sum_{j = 1}^p \phi_{j1} x_{ij} \right)^2 ϕ11,ϕ21,⋯,ϕp1maximizen1i=1∑n(j=1∑pϕj1xij)2
我们可以将 1 n ∑ i = 1 n ( ∑ j = 1 p ϕ j 1 x i j ) 2 \displaystyle \frac{1}{n} \sum_{i = 1}^n \left(\sum_{j = 1}^p \phi_{j1} x_{ij} \right)^2 n1i=1∑n(j=1∑pϕj1xij)2 写成一个矩阵的形式。
1 n ∑ i = 1 n ( ∑ j = 1 p ϕ j 1 x i j ) 2 = 1 n ∣ ∣ X ϕ 1 ∣ ∣ 2 \displaystyle \frac{1}{n} \sum_{i = 1}^n \left(\sum_{j = 1}^p \phi_{j1} x_{ij} \right)^2 = \frac{1}{n} || X \phi_1 || ^2 n1i=1∑n(j=1∑pϕj1xij)2=n1∣∣Xϕ1∣∣2。回忆 X X X 是 n × p n \times p n×p 的矩阵, ϕ 1 \phi_1 ϕ1 是 p × 1 p \times 1 p×1 的列向量。而 ∣ ∣ X ϕ 1 ∣ ∣ 2 \displaystyle || X \phi_1 || ^2 ∣∣Xϕ1∣∣2 又可以写成 ϕ 1 T X T X ϕ 1 \phi_1^T X^T X \phi_1 ϕ1TXTXϕ1。所以我们的优化问题就转化成了:
maximize ϕ 11 , ϕ 21 , ⋯ , ϕ p 1 1 n ϕ 1 T X T X ϕ 1 = maximize ϕ 11 , ϕ 21 , ⋯ , ϕ p 1 ϕ 1 T ( 1 n X T X ) ϕ 1 \underset{\phi_{11},\, \phi_{21}, \, \cdots, \phi_{p1}}{\text{maximize}} \frac{1}{n} \phi_1^T X^T X \phi_1 = \underset{\phi_{11},\, \phi_{21}, \, \cdots, \phi_{p1}}{\text{maximize}} \phi_1^T \left( \frac{1}{n} X^T X \right) \phi_1 ϕ11,ϕ21,⋯,ϕp1maximizen1ϕ1TXTXϕ1=ϕ11,ϕ21,⋯,ϕp1maximizeϕ1T(n1XTX)ϕ1
为了证明使得 ϕ 1 T ( 1 n X T X ) ϕ 1 \phi_1^T \left( \frac{1}{n} X^T X \right) \phi_1 ϕ1T(n1XTX)ϕ1 最大化的 ϕ 1 \phi_1 ϕ1 就是 1 n X T X \frac{1}{n} X^T X n1XTX 最大的特征值对应的特征向量,我们先证明下面的引理。
Lema
如果 A ∈ R p × p A \in \mathbb{R}^{p \times p} A∈Rp×p 是一个对称的positive semidefinite 的矩阵。 A A A 的 特征值为 λ 1 > λ 2 ⋯ > λ p \lambda_1 > \lambda_2 \cdots > \lambda_p λ1>λ2⋯>λp,对应的特征向量为 ϕ 1 , ϕ 2 , ⋯ , ϕ p \phi_1, \, \phi_2, \cdots, \phi_p ϕ1,ϕ2,⋯,ϕp。那么 ϕ 1 \phi_1 ϕ1 就是下面优化问题的解。
max x ∈ R p , ∣ ∣ x ∣ ∣ 2 = 1 x T A x \max\limits_{x \in \mathbb{R}^p, ||x||^2 = 1} x^T A x x∈Rp,∣∣x∣∣2=1maxxTAx
简要证明:
因为 A ∈ R p × p A \in \mathbb{R}^{p \times p} A∈Rp×p 是一个对称的positive semidefinite 的矩阵,我们可以将 A A A 分解为 A = Φ D Φ T A = \Phi D \Phi^T A=ΦDΦT。其中 Φ \Phi Φ 是 A A A 的特征向量组成的矩阵。即 Φ = ( ϕ 1 , ϕ 2 , ⋯ , ϕ p ) \Phi = (\phi_1, \, \phi_2, \cdots, \phi_p) Φ=(ϕ1,ϕ2,⋯,ϕp), A ϕ i = λ i ϕ i A \phi_i = \lambda_i \phi_i Aϕi=λiϕi,这里每一个 ϕ i \phi_i ϕi 均为 p × 1 p \times 1 p×1 的列向量。并且 Φ Φ T = I p × p \Phi \Phi^T = \mathbb{I}_{p \times p} ΦΦT=Ip×p。
D D D 是由特征值 λ i \lambda_i λi 组成的对角矩阵, D = ( λ 1 ⋱ λ p ) D = \begin{pmatrix} \lambda_1 & & \\ & \ddots & \\ & & \lambda_p \end{pmatrix} D=⎝ ⎛λ1⋱λp⎠ ⎞。
对于任意的列向量 x ∈ R p , ∣ ∣ x ∣ ∣ 2 = 1 x \in \mathbb{R}^p, \, ||x||^2 = 1 x∈Rp,∣∣x∣∣2=1,我们有
x T A x = x T Φ D Φ T x = ∑ i = 1 p λ i x T ϕ i ϕ i T x = ∑ i = 1 p λ i ∣ ∣ ϕ i T x ∣ ∣ 2 ≤ ∑ i = 1 p λ 1 ∣ ∣ ϕ i T x ∣ ∣ 2 = λ 1 ∑ i = 1 p ∣ ∣ ϕ i T x ∣ ∣ 2 = λ 1 ∣ ∣ Φ x ∣ ∣ 2 = λ 1 ( x T Φ T Φ x ) = λ 1 x T x = λ 1 \begin{aligned} x^T A x &= x^T \Phi D \Phi^T x \\ &= \sum_{i = 1}^p \lambda_i x^T \phi_i \phi_i^T x \\ &= \sum_{i = 1}^p \lambda_i || \phi_i^T x||^2 \\ &\leq \sum_{i = 1}^p \lambda_1 || \phi_i^T x||^2 \\ &= \lambda_1 \sum_{i = 1}^p || \phi_i^T x||^2 \\ &= \lambda_1 || \Phi x||^2 \\ &= \lambda_1 (x^T \Phi^T \Phi x) = \lambda_1 x^T x = \lambda_1 \end{aligned} xTAx=xTΦDΦTx=i=1∑pλixTϕiϕiTx=i=1∑pλi∣∣ϕiTx∣∣2≤i=1∑pλ1∣∣ϕiTx∣∣2=λ1i=1∑p∣∣ϕiTx∣∣2=λ1∣∣Φx∣∣2=λ1(xTΦTΦx)=λ1xTx=λ1
于是我们知道 max x ∈ R p , ∣ ∣ x ∣ ∣ 2 = 1 x T A x ≤ λ 1 \max\limits_{x \in \mathbb{R}^p, ||x||^2 = 1} x^T A x \leq \lambda_1 x∈Rp,∣∣x∣∣2=1maxxTAx≤λ1。如果我们取 x = ϕ 1 x = \phi_1 x=ϕ1,我们有 x T A x = ϕ 1 A ϕ 1 = λ 1 x^T A x = \phi_1 A \phi_1 = \lambda_1 xTAx=ϕ1Aϕ1=λ1。所以, ϕ 1 \phi_1 ϕ1 就是最优问题 max x ∈ R p , ∣ ∣ x ∣ ∣ 2 = 1 x T A x \max\limits_{x \in \mathbb{R}^p, ||x||^2 = 1} x^T A x x∈Rp,∣∣x∣∣2=1maxxTAx 的解。
程序验证
我们先用求特征值的方法来求主成分向量。我们的数据是有2个feature,一共有10 个数据。即 X.shape = (10, 2)。
np.random.seed(1)
m = 20
x = np.random.uniform(1, 10, m)
y = 2 * x + 1 + np.random.normal(0, 1, m)
x = x - np.mean(x)
y = y - np.mean(y)
X = np.vstack((x, y)).T # X is the data set, X.shape = (m, 2)
我们来求协方差矩阵的特征值和特征向量。
eig_vals, eig_vecs = np.linalg.eig(1 / 2 * np.dot(X.T, X))
eig_vals
array([ 1.12975274, 236.75469475])
eig_vecs # The eigenvectors are eig_vecs[:,1], eig_vecs[:, 2]
array([[-0.89631173, -0.44342449],
[ 0.44342449, -0.89631173]])
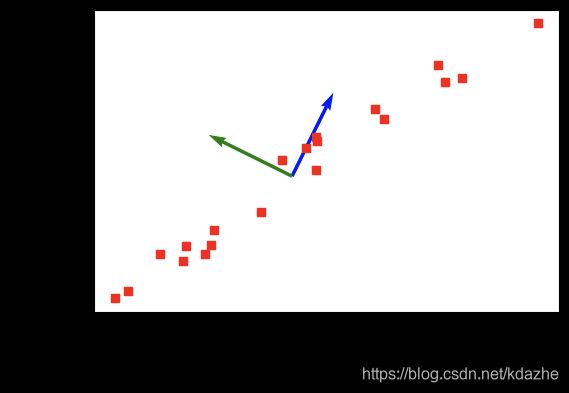
我们看到,最大的特征值是 236.75,对应的特征向量(即第一主成分)为 (-0.443, -0.896)。第二主成分为 (-0.896, 0.443)。
我们可以检验这两个主成分与用 sklearn 中的PCA 方法得到的结果是一样的。
pca = PCA(n_components=2, svd_solver='full')
pca.fit(X)
pca_phis = pca.components_
PCA(copy=True, iterated_power=‘auto’, n_components=2, random_state=None,
svd_solver=‘full’, tol=0.0, whiten=False)
array([[ 0.44342449, 0.89631173],
[-0.89631173, 0.44342449]])
可以看到,得到的第一主成分是(0.443, 0.896),第二主成分是 (-0.896, 0.443)。这些结果与求解特征值与特征向量得到的结果相同。
原始数据 X X X(红色) 与第一主成分(蓝色)、第二主成分(绿色)如下图所示。
参考文献
[1] An introduction to statistical learning: with applications in R, Gareth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani, Springer.