TensorFlow2.0入门2-3 猫狗分类实战之迁移学习
TensorFlow 2.0 三大项目实战
目录
-
- 为什么要用迁移学习
- 读入数据与预训练模型
- 为模型添加新的层
-
- 读入数据并进行数据增强和自动标签
- 进行训练
-
- 绘制精度曲线
- 对我们之前错误的猫数据进行预测
内容总结自吴恩达TensorFlow2.0的课程
为什么要用迁移学习
- 我们没有足够的数据无法让我们的模型学习到足够的特征。
- 就算有足够的数据,我们没有足够好的环境,也无法训练这么大的网络。
- 虽然我们和原来的模型可能识别的东西不一样,但是要识别的的特征都是相似的,所以可以使用迁移学习。
如果懒得训练可以从这里下载训练好的模型
链接:https://pan.baidu.com/s/1jR3-4LHLRz6KlovT6nw79g
提取码:kyxj
读取和保存方式如下:
model.save(base + '/model/' + 'model_pre_trained.h5')
model = tf.keras.models.load_model(SAVE_PATH + 'model_pre_trained')
读取完之后就可以直接进行继续的训练或者预测了。
读入数据与预训练模型
点击下载权重数据
import os
from tensorflow.keras import layers
from tensorflow.keras import Model
# !wget --no-check-certificate \
# https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5 \
# -O /tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5
from tensorflow.keras.applications.inception_v3 import InceptionV3
base = 'C:/Users/dlaicourse-master/Course 2'
# 读取权重信息
local_weights_file = base + '/tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
# 对我们的预训练模型进行修改,输入改成我们要输入的数据的形状,不包括最上面一层因为我们要进行重新训练。
pre_trained_model = InceptionV3(input_shape = (150, 150, 3),
include_top = False,
weights = None)
# 加载我们需要的权重。
pre_trained_model.load_weights(local_weights_file)
# 因为我们的数据量比较小所以我们不训练之前的网络。
for layer in pre_trained_model.layers:
layer.trainable = False
# 打印inception网络的结果
pre_trained_model.summary()
# 从中选取一层打印相关信息。
last_layer = pre_trained_model.get_layer('mixed7')
print('last layer output shape: ', last_layer.output_shape)
last_output = last_layer.output
print(last_output)

为模型添加新的层
from tensorflow.keras.optimizers import RMSprop
# 对我们的输出进行平铺操作
x = layers.Flatten()(last_output)
# 增加一个全连接层,并使用relu作为激活函数
x = layers.Dense(1024, activation='relu')(x)
# 添加随机失活,抑制过拟合
x = layers.Dropout(0.2)(x)
# 把输出设置成sigmoid函数
x = layers.Dense (1, activation='sigmoid')(x)
# 初始化我们自己的模型
model = Model( pre_trained_model.input, x)
model.compile(optimizer = RMSprop(lr=0.0001),
loss = 'binary_crossentropy',
metrics = ['acc'])
读入数据并进行数据增强和自动标签
# !wget --no-check-certificate \
# https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip \
# -O /tmp/cats_and_dogs_filtered.zip
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import os
import zipfile
# 读取数据
local_zip = base + '/tmp/cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall(base + '/tmp')
zip_ref.close()
base_dir = base + '/tmp/cats_and_dogs_filtered'
train_dir = os.path.join( base_dir, 'train')
validation_dir = os.path.join( base_dir, 'validation')
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
train_cat_fnames = os.listdir(train_cats_dir)
train_dog_fnames = os.listdir(train_dogs_dir)
# 自动为数据打上标签并进行归一化处理和数据增强。
train_datagen = ImageDataGenerator(rescale = 1./255., #归一化处理
rotation_range = 40, # 旋转角度
width_shift_range = 0.2, # 宽度变化范围
height_shift_range = 0.2, # 高度变化范围
shear_range = 0.2, # 剪切范围(类似于倾斜并拉伸)
zoom_range = 0.2, # 缩放设置
horizontal_flip = True) # 水平翻转
# 对我们的测试集打上标签并进行归一化处理
test_datagen = ImageDataGenerator( rescale = 1.0/255. )
# 利用我们的ImageDataGenerator来读取数据
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size = 20, # 一批读多少个数据
class_mode = 'binary', # 分类方式
target_size = (150, 150)) # 目标大小
#
validation_generator = test_datagen.flow_from_directory( validation_dir,
batch_size = 20,
class_mode = 'binary',
target_size = (150, 150))
进行训练
# 进行训练
history = model.fit_generator(
train_generator,
validation_data = validation_generator,
steps_per_epoch = 100, # 一次训练几批完成
epochs = 20, # 所有数据训练几次
validation_steps = 50,
verbose = 2)

绘制精度曲线
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'r', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend(loc=0)
plt.figure()
plt.show()
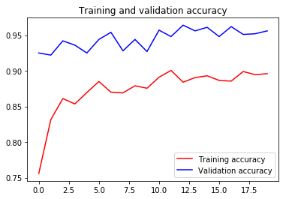
可以看到对比之前的0.75到0.85这一次在验证集的正确率上升到了0.95。之所以测试集比训练集正确率都高,是因为用了图像增强,产生了一些不太友好的数据,而我们的验证集数据都是正常的、好识别的数据。
对我们之前错误的猫数据进行预测
import numpy as np
from keras.preprocessing import image
import tensorflow as tf
import os
base = 'C:/Users/dlaicourse-master/Course 2'
filePath = base + '/tmp/content/'
keys = os.listdir(filePath)
# 获取所有文件名
model = tf.keras.models.load_model(base + '/model/' + 'model_pre_trained.h5')
for fn in keys:
# 对图片进行预测
# 读取图片
path = base + '/tmp/content/' + fn
img = image.load_img(path, target_size=(150, 150))
x = image.img_to_array(img)
# 在第0维添加维度变为1x150x150x3,和我们模型的输入数据一样
x = np.expand_dims(x, axis=0)
# np.vstack:按垂直方向(行顺序)堆叠数组构成一个新的数组,我们一次只有一个数据所以不这样也可以
x = x / 255
images = np.vstack([x])
# batch_size批量大小,程序会分批次地预测测试数据,这样比每次预测一个样本会快。因为我们也只有一个测试所以不用也可以
classes = model.predict(images, batch_size=1)
print(classes)
if classes[0]>0.5:
print(fn + " is a dog")
else:
print(fn + " is a cat")

在数据增强和dropout都没用成功识别的情况下,这次加入了迁移学习,终于识别成功之前发生过错误的两个数据了。

