使用Pytorch中的tensorboard可视化网络训练参数
环境配置
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorboard
安装tensorboard,TensorBoard可视化的数据来自于本地l文件,在控制台开启TensorBoard服务时指定该文件夹为监控文件夹。
默认开启6006端口提供服务,通过http://localhost:6006/可以访问可视化结果
简单试验
官方示例
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()
这个示例将训练的日志保存在了和你这个python文件同级的目录下,或者理解为 ‘./runs’ 。
运行之后,再去terminal 下调用一下命令:
tensorboard --logdir=D:\grin-main\runs #项目所在的目录下自动新创建了runs文件夹
(我的tensorboard是安装在项目的虚拟环境,即venv文件夹下,所以进入该文件夹的Scripts下可直接使用tensorboard命令)
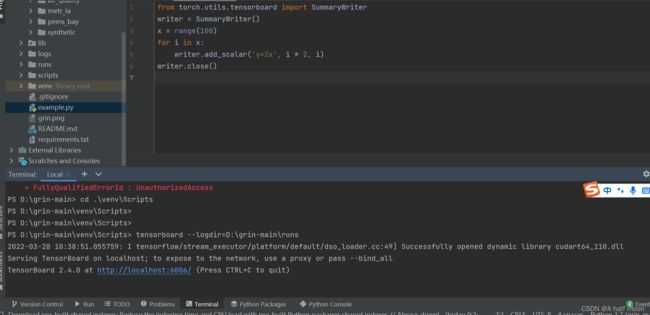
没有虚拟环境的话,直接在terminal端运行代码,也可运行下面的代码。
tensorboard --logdir runs

然后直接打开链接,可查看结果
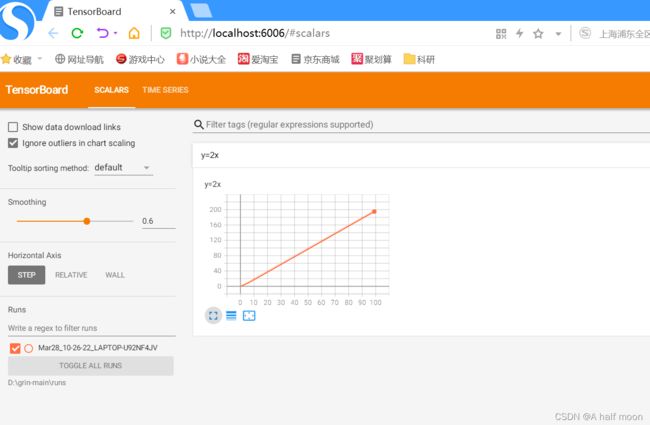
tensorboard针对不同的类型数据区分多个标签,每一个标签页面代表不同的类型。简单介绍如下:
1.SCALAR
- 对标量数据进行汇总和记录,通常用来可视化训练过程中随着迭代次数准确率(val acc)、损失值(train/test loss)、学习率(learning rate)、每一层的权重和偏置的统计量(mean、std、max/min)等的变化曲线
2.IMAGES
- 可视化当前轮训练使用的训练/测试图片或者 feature maps
3.GRAPHS
- 可视化计算图的结构及计算图上的信息,通常用来展示网络的结构
4.HISTOGRAMS
- 可视化张量的取值分布,记录变量的直方图(统计张量随着迭代轮数的变化情况)
5.PROJECTOR
- 全称Embedding Projector 高维向量进行可视化
创建SummaryWriter
from torch.utils.tensorboard import SummaryWriter
# 默认使用 "runs/时间" 路径来保存日志
writer = SummaryWriter("./runs/") #./表示当前项目目录,runs文件夹会自动创建,此句表示writer把日志(训练时的相关记录情况)写入runs文件夹下
SCALAR
使用add_scalar来记录数值。
add_scalar(tag, scalar_value, global_step=None, walltime=None)
- tag:字符串。数据名称。
- scalar_value:浮点型。数值。
- global_step:整形,可选。训练的step
- walltime:浮点型,可选。默认为time.time()
一般用add_scalar来记录损失 loss、正确率 accurary、学习率 learning rate的变化,用来监控训练过程。
with SummaryWriter(comment='MutipleInput') as w:
writer.add_scalar("loss", training_losses[-1], global_step=epoch) #training_losses[-1]为模型代码中的loss项
然后在terminal端执行tensorboard --logdir=runs 运行结果如下图:

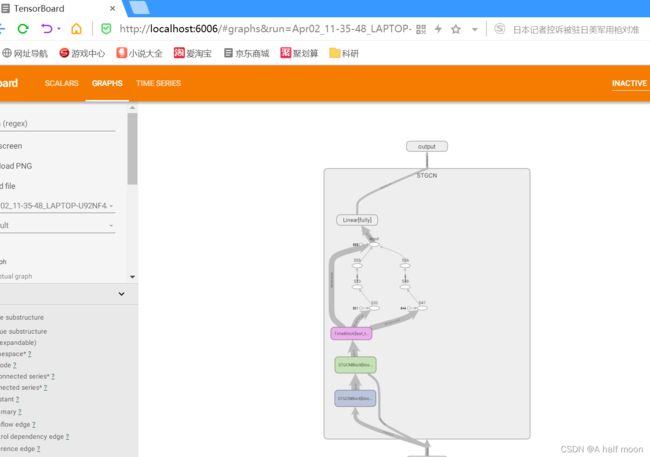
GRAPHS
使用add_graph来可视化神经网络
add_graph(model, input_to_model=None, verbose=False, **kwargs)
- model:torch.nn.Module。需要可视化的网络模型
- input_to_model:torch.Tensor或其列表,默认为None。输入神经网络的变量或一组变量
- verbose:布尔,默认为False。是否为信息详细模式。
注意:模型的输入可能有多组,此时可以用(,)格式进行区分。
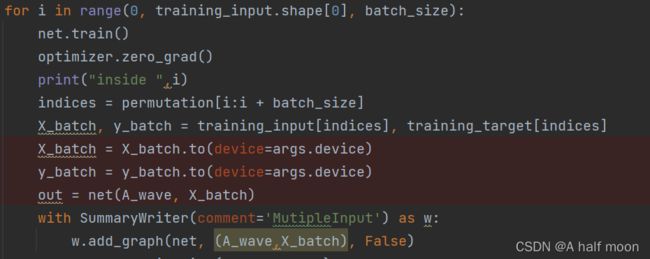
with SummaryWriter(comment='MutipleInput') as w:
w.add_graph(net, (A_wave,X_batch), False) #net为定义的模型名称,A_wave,X_batch为输入的两组变量
然后在terminal端执行tensorboard --logdir=runs 运行结果如下图:
Histogram 直方图
使用 add_histogram 方法来记录一组数据的直方图。
- tag (string): 数据名称
- values (torch.Tensor, numpy.array, or string/blobname): 用来构建直方图的数据
- global_step (int, optional): 训练的 step
- bins (string, optional): 取值有 ‘tensorflow’、‘auto’、‘fd’ 等, 该参数决定了分桶的方式,详见这里。
- walltime (float, optional): 记录发生的时间,默认为 time.time()
- max_bins (int, optional): 最大分桶数
我们可以通过观察数据、训练参数、特征的直方图,了解到它们大致的分布情况,辅助神经网络的训练过程。
with SummaryWriter(comment='MutipleInput') as w:
writer.add_histogram('theta-w1', net.block1.Theta1[0], global_step=i)
writer.add_histogram('theta-w2', net.block1.Theta1[1], global_step=i) #net.block1.Theta1为训练权重参数,i为迭代轮数,共250次
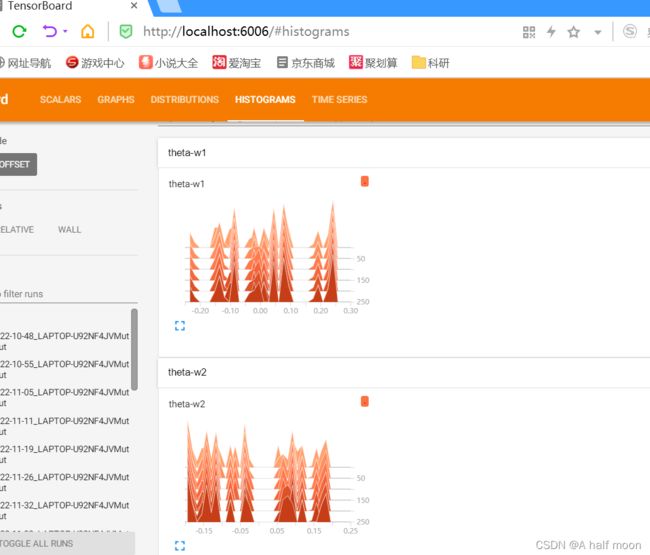
如上图所见,我们可以通过可视化的直方图更直观地了解可训练参数随着训练次数的变化情况。
更多用法,可参考下面这篇博客:tensorboard全面用法详解