RCAN/RCAB:Image Super-Resolution Using Very Deep Residual Channel Attention Networks
前言
这是使用在超分辨率 领域的一个论文,主要卖点是提出的名叫RCAB的注意力模块。
Motivation
低分辨率图像(DR)中包含大量低频信息,但是在一般的卷积神经网络中每个通道中的特征会被同等对待,缺乏跨特征通道的区分学习能力,阻碍了深层网络的表征能力,不符合超分辨率任务中尽可能多地恢复高频信息的需求。
Methods
RCAN
本文提出了residual channel attention network(RCAN),残差通道注意力网络,来自适应地学习较深的网络中不同通道中的特征。
提出residual in residual(RIR)机制,即残差中的残差,目的是使网络能够适应更深层的结构。
如图所示,一个个深蓝色的残差组RG通过LSC长跳接连接,然后再接上最开始的只经过一次卷积得到的特征图,换句话说,大残差中包含了小残差。同时小残差中又有小小残差结构,即浅蓝色模块,浅蓝色模块又通过短跳接SSC进行连接,而且小小残差中是基于注意力的残差模块。最后经过所有的残差后的特征图做一个upsample使得低分辨率变成高分辨率(HR)。
结构是比较清晰明了的,感觉这种思维也是很容易套用在其他领域上,即把残差套娃再套娃。
整体上,具体做法是:输入一张低分辨率图片,经过一个3x3的卷积得到一个特征图,再经过一个RIR模块,其中包含10个RG与一个3x3卷积和一个LSC。最后经过上采样与一个3x3卷积层,上采样使用ESPCNN,约束使用L1loss。最终得到分辨率放大的输出。
小模块可以在下面进行介绍。
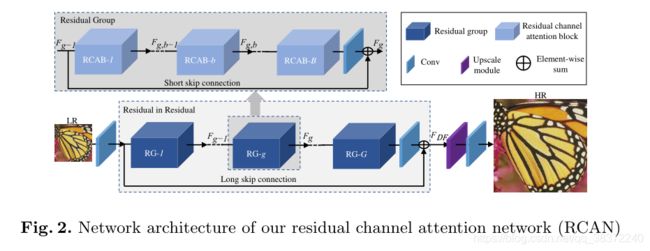
这种残差套娃的合理性来源,在文中是引用论文:Enhanced deep residual networks
for single image super-resolution. In: CVPR W (2017)
通道注意力CA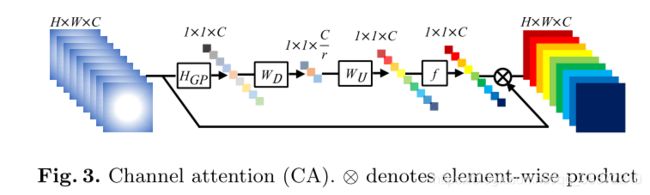
因为低频信息中包含了丰富的信息,高频信息中则是包含了边缘、纹理以及其他细节的信息,把这些特征都统一对待是不太好的,使用了注意力机制的方法,能够提升网络对这些特征的信息表征能力。
具体操作是先进行一个全局平均池化得到1x1xC,这是一个包含了粗略信息的通道描述符,再在channel上除以比例r,即downsample,之后再upsample得到每一个通道的权重系数。最后和残差过来的原来特征进行相乘,得到重新分配过通道权重的新特征。
作者选择C=64,r=16。
RCAB
F ( g , b ) F_(g,b) F(g,b)是输入,先经过一个conv+relu+conv的模块,得到 X ( g , b ) X_(g,b) X(g,b),然后将此特征图输入到CA中,经过一个sigmoid后再与原来特征图相乘,最终加上最开始的输入,得到输出。
其中卷积操作使用3x3的卷积核。

RG
residual group(RG)由B个RCAB、一个卷积和一个SSC组成,文中B为20。
代码
代码是从GitHub中直接复制出来的,是完整的一个RCAN的结构代码:
from model import common
import torch.nn as nn
def make_model(args, parent=False):
return RCAN(args)
## Channel Attention (CA) Layer
class CALayer(nn.Module):
def __init__(self, channel, reduction=16):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
## Residual Channel Attention Block (RCAB)
class RCAB(nn.Module):
def __init__(
self, conv, n_feat, kernel_size, reduction,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(RCAB, self).__init__()
modules_body = []
for i in range(2):
modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias))
if bn: modules_body.append(nn.BatchNorm2d(n_feat))
if i == 0: modules_body.append(act)
modules_body.append(CALayer(n_feat, reduction))
self.body = nn.Sequential(*modules_body)
self.res_scale = res_scale
def forward(self, x):
res = self.body(x)
#res = self.body(x).mul(self.res_scale)
res += x
return res
## Residual Group (RG)
class ResidualGroup(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, act, res_scale, n_resblocks):
super(ResidualGroup, self).__init__()
modules_body = []
modules_body = [
RCAB(
conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=nn.ReLU(True), res_scale=1) \
for _ in range(n_resblocks)]
modules_body.append(conv(n_feat, n_feat, kernel_size))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res += x
return res
## Residual Channel Attention Network (RCAN)
class RCAN(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(RCAN, self).__init__()
n_resgroups = args.n_resgroups
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
reduction = args.reduction
scale = args.scale[0]
act = nn.ReLU(True)
# RGB mean for DIV2K
rgb_mean = (0.4488, 0.4371, 0.4040)
rgb_std = (1.0, 1.0, 1.0)
self.sub_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std)
# define head module
modules_head = [conv(args.n_colors, n_feats, kernel_size)]
# define body module
modules_body = [
ResidualGroup(
conv, n_feats, kernel_size, reduction, act=act, res_scale=args.res_scale, n_resblocks=n_resblocks) \
for _ in range(n_resgroups)]
modules_body.append(conv(n_feats, n_feats, kernel_size))
# define tail module
modules_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)]
self.add_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std, 1)
self.head = nn.Sequential(*modules_head)
self.body = nn.Sequential(*modules_body)
self.tail = nn.Sequential(*modules_tail)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
res = self.body(x)
res += x
x = self.tail(res)
x = self.add_mean(x)
return x
def load_state_dict(self, state_dict, strict=False):
own_state = self.state_dict()
for name, param in state_dict.items():
if name in own_state:
if isinstance(param, nn.Parameter):
param = param.data
try:
own_state[name].copy_(param)
except Exception:
if name.find('tail') >= 0:
print('Replace pre-trained upsampler to new one...')
else:
raise RuntimeError('While copying the parameter named {}, '
'whose dimensions in the model are {} and '
'whose dimensions in the checkpoint are {}.'
.format(name, own_state[name].size(), param.size()))
elif strict:
if name.find('tail') == -1:
raise KeyError('unexpected key "{}" in state_dict'
.format(name))
if strict:
missing = set(own_state.keys()) - set(state_dict.keys())
if len(missing) > 0:
raise KeyError('missing keys in state_dict: "{}"'.format(missing))