tensorflow中model.compile()
model.compile()用来配置模型的优化器、损失函数,评估指标等
里面的具体参数有:
compile(
optimizer='rmsprop',
loss=None,
metrics=None,
loss_weights=None,
weighted_metrics=None,
run_eagerly=None,
steps_per_execution=None,
jit_compile=None,
**kwargs
)
我们一帮需要设置的就只有前三个参数,
一. optimizer设置优化器
没有衰减率的一般是在整个更新过程中学习率不改变,有衰减率的就是自适应学习率的优化器,就是在更新参数过程中,学习率能根据梯度自己改变。
这里的学习率改变好像是针对的这一轮中的学习率,在下一个epoch中学习率又会变成没变化之前的值。例如某一轮的学习率为0.001,在这一轮训练过程中学习率可能会变化,但是下一轮开始时学习率是0.001,也就是变化不带入下一轮训练,如果想要改变学习率,就在回调函数里设置学习率衰减方式才能改变 (不知道我说的对不对,我也不是很明白,有错误的话请大哥批评指正 )
tf.keras.optimizers中有很多优化器供我们选择:
- tf.keras.optimizers.Adadelta
tf.keras.optimizers.Adadelta(
learning_rate=0.001, #初始学习率
rho=0.95, # 衰减率
epsilon=1e-07, #加在分母避免出现除以0的情况
name='Adadelta',
**kwargs
)
- tf.keras.optimizers.Adagrad
tf.keras.optimizers.Adagrad(
learning_rate=0.001, #初始学习率
initial_accumulator_value=0.1, #动量值
epsilon=1e-07,
name='Adagrad',
**kwargs
)
- tf.keras.optimizers.Adam
Adam优化是一种基于一阶和二阶矩自适应估计的随机梯度下降方法。
根据Kingma et al.,2014的说法,该方法“计算效率高,几乎不需要内存,对梯度的对角线重新缩放不变性,非常适合于数据/参数较大的问题”。
tf.keras.optimizers.Adam(
learning_rate=0.001, #初始学习率
beta_1=0.9, #一阶矩估计的衰减率
beta_2=0.999, #二阶矩估计的衰减率
epsilon=1e-07,
amsgrad=False,
name='Adam',
**kwargs
)
- tf.keras.optimizers.RMSprop
利用了梯度的均方
tf.keras.optimizers.RMSprop(
learning_rate=0.001,
rho=0.9, #衰减率
momentum=0.0, #动量
epsilon=1e-07,
centered=False,
name='RMSprop',
**kwargs
)
- tf.keras.optimizers.SGD
SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。缺点还挺大的,
tf.keras.optimizers.SGD(
learning_rate=0.01,
momentum=0.0,
nesterov=False,
name='SGD',
**kwargs
)
二. loss设置损失函数
- tf.keras.losses.BinaryCrossentropy为二分类交叉熵损失函数
计算公式为:
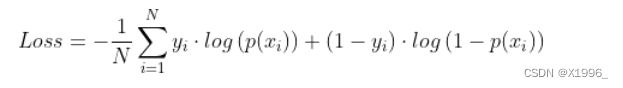
yi为第i个的真实标签,p(xi)为第i个预测正确的概率,当输出的预测值不是概率时,我们需要将from_logits参数设置为True,它会将预测值转换为概率,如果预测值是概率的话,就设置为False。

tf.keras.losses.BinaryCrossentropy(
from_logits=False,
label_smoothing=0.0,
axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name='binary_crossentropy'
)
import tensorflow as tf
y_true = [0, 1, 0, 0]
y_pred = [-18.6, 0.51, 2.94, -12.8]
bce = tf.keras.losses.BinaryCrossentropy(from_logits=True)
print(bce(y_true, y_pred))
L = 0
for i in range(4):
y_pred[i] = 1.0/(1+tf.math.exp(-1*y_pred[i]))
L += y_true[i]*tf.math.log(y_pred[i]) + (1-y_true[i])*tf.math.log(1-y_pred[i])
print(-1*L/4)
输出:

2. tf.keras.losses.BinaryFocalCrossentropy
Focal loss主要用来解决样本不均衡问题,引入了一个聚焦因子和loss相乘。
如果真实标签为1,聚焦因子为 focal_factor = (1 - output) ^ gamma
如果真是标签为0,聚焦因子为 focal_factor = ( output) ^ gamma
output为输出概率:
当gamma为0时,就成了BinaryCrossentropy。
参数:
tf.keras.losses.BinaryFocalCrossentropy(
gamma=2.0,
from_logits=False,
label_smoothing=0.0,
axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name='binary_focal_crossentropy'
)
具体实现过程:
import tensorflow as tf
y_true = [0, 1, 0, 0]
y_pred = [-18.6, 0.51, 2.94, -12.8]
bce = tf.keras.losses.BinaryFocalCrossentropy(gamma=2.0, from_logits=True)
print(bce(y_true, y_pred))
L = 0
for i in range(4):
y_pred[i] = 1.0/(1+tf.math.exp(-1*y_pred[i]))
L += tf.math.pow((1.0-y_pred[i]),2)*y_true[i]*tf.math.log(y_pred[i]) + tf.math.pow(y_pred[i],2)*(1-y_true[i])*tf.math.log(1-y_pred[i])
print(-1*L/4)
输出:

3. tf.keras.losses.CategoricalCrossentropy 多分类交叉熵损失函数
当y_true为One-Hot 编码时使用CategoricalCrossentropy
当y_true为整数编码时使用SparseCategoricalCrossentropy
tf.keras.losses.CategoricalCrossentropy(
from_logits=False,
label_smoothing=0.0,
axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name='categorical_crossentropy'
)
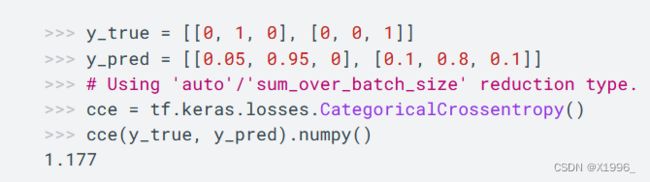
tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=False,
reduction=losses_utils.ReductionV2.AUTO,
name='sparse_categorical_crossentropy'
)
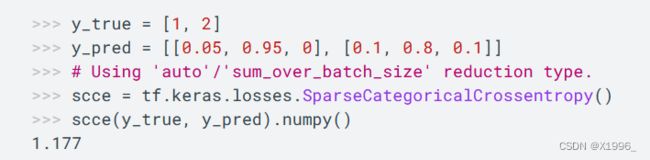
还有很多其他损失函数。。。。。
三、metrics设置评估指标
常用的分类指标有准确率、精度等,添加进去就会在训练过程中实时打印这些指标。
metrics=[tf.keras.metrics.Accuracy(),tf.keras.metrics.Precision()]
例外也可以自定义一些函数添加进去,例如想打印学习率:
def get_lr_metric(optimizer):
def lr(y_true, y_pred):
return optimizer.lr
return lr
optimizer = Adam(learning_rate=lr)
lr_metric = get_lr_metric(optimizer)
model.compile(loss=tf.keras.losses.categorical_crossentropy,
optimizer=optimizer,
metrics=['accuracy', lr_metric])
这样就可以打印了。
tensorflow的API里函数太多了。。。。。