pandas.pivot_table详解
想必大家都用过excel, 肯定会熟悉excel中的透视表, python中pandas.pivot就是在DataFrame表格中实现这个操作, 什么? 连透视表都不知道? 没事,往下看就知道了
目录
开始使用pivot_table
index参数
values
columns
fill_value
aggfunc
margin
开始使用pivot_table
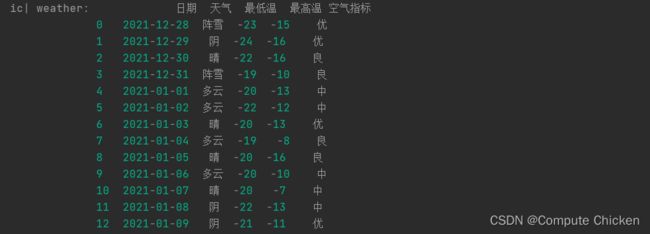
整个最简单的天气数据, 有日期, 天气, 最低温, 最高温, 空气指标五项数据
日期,天气,最低温,最高温,空气指标
2021-12-28,阵雪,-23,-15,优
2021-12-29,阴,-24,-16,优
2021-12-30,晴,-22,-16,良
2021-12-31,阵雪,-19,-10,良
2021-01-01,多云,-20,-13,中
2021-01-02,多云,-22,-12,中
2021-01-03,晴,-20,-13,优
2021-01-04,多云,-19,-8,良
2021-01-05,晴,-20,-16,良
2021-01-06,多云,-20,-10,中
2021-01-07,晴,-20,-7,中
2021-01-08,阴,-22,-13,中
2021-01-09,阴,-21,-11,优先用一个DataFrame读出来,并打印(我比较喜欢冰淇淋ic)
from icecream import ic
import pandas as pd
import numpy as np
weather = pd.read_csv("../resources/weather.csv", date_parser=True)
ic(weather)平平无奇的表格数据罢了
index参数
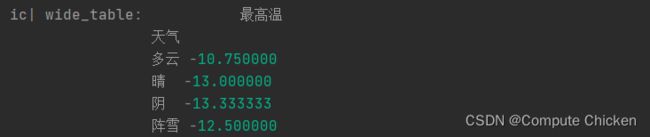
现在使用一下pivot_table函数, 加一个属性index=["天气"](当然也可以加两个)
wide_table = (weather.pivot_table(
index=["天气"], # 透视表行索引为天气, 按不同的天气统计其他值
))
ic(wide_table)这时显示的数据是各种"天气"的平均值(平均最高温, 平均最低温...,空气指标不是数字当然没有平均值)

values
如果再使用一个参数values=["最高温"], 默认显示的是除index的所有值, 加入values之后就只显示values了
wide_table = (weather.pivot_table(
index=["天气"], # 透视表行索引为天气, 按不同的天气统计其他值
values=["最高温"], # 要展示的值(除了index)
))
ic(wide_table)只显示了"最高温"
columns
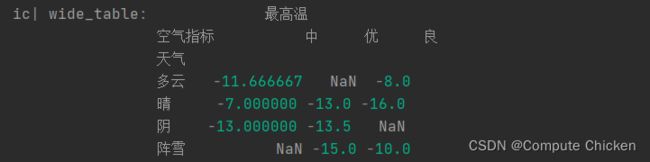
只有index说明我们只在行这边统计, 加上columns可以在列上也统计平均值
例如加上columns=["空气指标"]
wide_table = (weather.pivot_table(
index=["天气"], # 透视表行索引为天气, 按不同的天气统计其他值
columns=["空气指标"], # 透视表列索引
values=["最高温"], # 要展示的值(除了index)
))
ic(wide_table)这样列上统计了不同"空气指标"的数据平均值 (但是总感觉不是很好看......)
fill_value
fill_value 就是用一个什么值来代替表格中出现的空值, 很简单理解
aggfunc
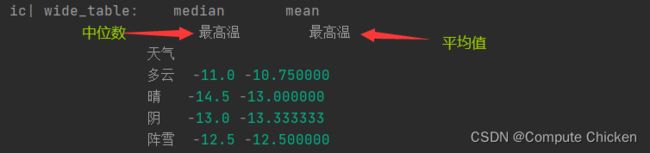
本来我们一直都是在统计平均值(默认),在aggfunc可以统计其他的指标(如中位数, 总和等)
wide_table = (weather.pivot_table(
index=["天气"], # 透视表行索引为天气, 按不同的天气统计其他值
values=["最高温"], # 要展示的值(除了index)
fill_value=0, # 填补空值
aggfunc=[np.median, np.mean], # aggfunc默认统计的是平均值(一个值),也可以让他统计中位数等等
))
ic(wide_table)这时不仅统计了平均值, 还统计了中位数
margin
值是布尔值, 是否在边缘统计全部的aggfunc(默认是平均值)
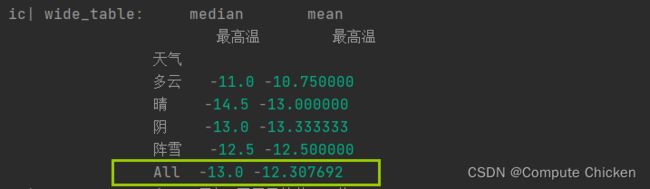
wide_table = (weather.pivot_table(
index=["天气"], # 透视表行索引为天气, 按不同的天气统计其他值
values=["最高温"], # 要展示的值(除了index)
fill_value=0, # 填补空值
aggfunc=[np.median, np.mean], # aggfunc默认统计的是平均值(一个值),也可以让他统计中位数等等
margins=True
))
ic(wide_table)多出一行All, 统计的是全部的平均值(中位数)
喜欢的朋友点个赞吧[咧嘴笑]