【笔记+代码】网格搜索-GridSearchCV
文章目录
- 1 为什么需要网格搜索?
-
- 1.1 参数
- 1.2 使用网格搜索的原因
- 2 网格搜索是什么?
- 3 如何进行网格搜索?
- 参考
1 为什么需要网格搜索?
在了解一个东西之前,首先,我们需要知道为什么要这样做,即该东西的应用之地和好处。而在了解使用网格搜索的原因之前,需要先了解一个名词——“参数”。
1.1 参数
参数,在程序里意义上来说就是一个变量。
而在机器学习模型中,它大致可以分为两类:
- 超参数
- 在算法运行前需要决定的参数
- 模型参数
- 算法运行过程中学习的参数
以KNN模型为例,该模型是没有模型参数的,而k则是典型的超参数,因为在算法开始前就需要指定选取目标点的多少个邻居。
此外,若KNN中使用距离权重,且距离采用闵可夫斯基距离时,p也会成为一个超参数。
1.2 使用网格搜索的原因
不同的超参数设置,机器学习给出的结果也会不一样,因此,也会一定程度上影响到对结果的评价指标。而往往人们会追求一个“最好”的结果,因此,就需要在众多超参数的取值范围中选取一个“最优”的值进行设置。
因此,使用网格搜索等手段,均是为了寻找好的超参数。
寻找好的超参数往往有多种手段:
- 利用领域知识
- 利用经验数值
- 进行实验搜索
前两项,基本上像我们这种领域小白是不可能达到的了,因此只能采取第三种方法。
实验搜索也就是常常说的一种类似“穷举/遍历”的手段。往往,我们会先人为给定一个搜索范围,然后自行编写一段代码嵌套在主体算法的外面,或者使用现成的API调用搜索(比如网格搜索)。前者,对于不同的模型算法,还有搜索的个数,调整会比较多;后者,更为方便快捷。
2 网格搜索是什么?
如上述所言,网格搜索是为了寻找到好的超参数的一种实验搜索手段,且其具有现成的API可以调用,方便快捷。
网格搜索的思想跟穷举是类似的,因此下面以KNN模型为例,对其超参数进行搜索。先不使用网格搜索的方法,来体验该思想。
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 加载数据集
digits = datasets.load_digits()
# 获取样本的特征数据与标签值
X = digits.data
y = digits.target
# 划分测试数据集与训练数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
# 实例化一个KNN分类器
knn_clf = KNeighborsClassifier(n_neighbors=3)
# 训练
knn_clf.fit(X_train, y_train)
# 模型得分
knn_clf.score(X_test, y_test)
'''默认情况下寻找最好的K'''
# 保存当前最优的信息
best_score = 0.0
best_k = -1
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
print("best_k =", best_k)
print("best_score =", best_score)
'''是否考虑距离'''
best_score = 0.0
best_k = -1
# 是否考虑距离权重
best_method = ""
for method in ["uniform", "distance"]:
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors=k, weights=method)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
best_method = method
print("best_method =", best_method)
print("best_k =", best_k)
print("best_score =", best_score)
'''考虑距离的情况下搜索闵可夫斯基距离的p'''
best_score = 0.0
best_k = -1
best_p = -1
# 对于距离进行搜索
for k in range(1, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(n_neighbors=k, weights="distance", p=p)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_p = p
best_score = score
print("best_k =", best_k)
print("best_p =", best_p)
print("best_score =", best_score)
可以发现,在进行不同模式下的搜索时(当超参数之间存在依赖关系时),需要写多个程序,比如,只有在考虑距离的模式下,才能对闵可夫斯基距离的p进行搜索,不考虑的时候,不需要进行搜索。
此外,当要一次性搜索出的超参数集合的元素越来越多时,外面显式嵌套的for循环也将越来越多,影响美观。
而网格搜索则可以解决这些问题,即当超参数之间存在一定的依赖关系,可以一次性寻找最优的这些超参数。
3 如何进行网格搜索?
关于网格搜索的使用,详细的可以参考我在后续的参考中的前两个链接。
纠正:第一个文章中说cv默认为3折,但是官方文档已经注明:
Changed in version 0.22: cv default value if None changed from 3-fold to 5-fold.
其它之处没有详细查阅,这个给我们一个巨大的提示:看博客确实可以快速get到各参数设置的用法,但是还要以官方文档为准。
通常使用手册:
- 使用
from sklearn.model_selection import GridSearchCV来调用- 常使用的
GridSearchCV的参数有
estimator:参数针对的搜索对象param_grid:超参的集合,本质上是一个列表,每个元素代表一组搜索(是一个字典),每个字典中的key是本次一次性要搜索的超参名字,对应的value是一个列表,描述搜索范围,其每个元素是相应的搜索取值。n_jobs:与并行运行相关,即可以提高搜索速度,取值为整数,默认为1,大于1的整数表示运行核数(但不能超过运行主机有的核数),取-1代表使用主机所有的核数。cv:与交叉验证有关,根据版本不同,默认值不同,默认3折或5折。verbose:取值为整数,默认在运行过程中不输出任何东西,但如果设定取值,则取值越大,过程中输出的信息越详细。- 使用
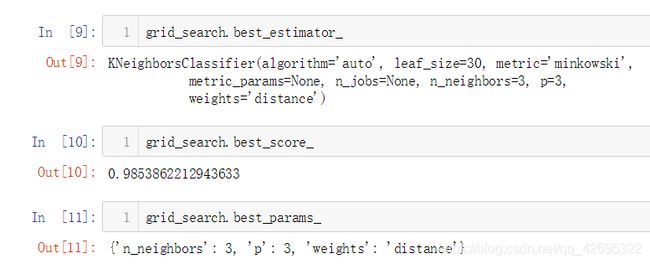
grid_search.fit进行具体的搜索,且会返回搜索器实例本身信息- 使用
grid_search.best_estimator_可以查看带有最优超参的搜索器的相关信息- 使用
grid_search.best_score_可以查看当前最优超参情况下的得分- 使用
grid_search.best_params_可以输出当前由最优的超参及其取值组成的字典
下面给出一段网格搜索实例代码:
from sklearn.model_selection import GridSearchCV
param_grid = [
{
'weights': ['uniform'],
'n_neighbors': [i for i in range(1, 11)]
},
{
'weights': ['distance'],
'n_neighbors': [i for i in range(1, 11)],
'p': [i for i in range(1, 6)]
}
]
# 创建KNN分类器
knn_clf = KNeighborsClassifier()
# 创建网格搜索实例
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs=-1, verbose=2)
# 进行网格搜索
grid_search.fit(X_train, y_train)
此外,还可以调用grid_search的相关东西:
参考
本次博客旨在记录初次学习到的网格搜索相关知识,并方便之后自己使用。
本次博客内容参考了以下相关资料:
GridSearchCV 简介
网格搜索官方文档
慕课网的机器学习课程