目录
- 数据集读取
- 构建网络
-
- ==模型输入==
- ==卷积==
- ==反卷积==
- ==上采样==
- ==池化==
- ==BatchNormalization==
- ==激活==
- ==pytorch模型流程==
- ==实现VGG16过程对比==
- 训练
- 参考文章
数据集读取
构建网络
3、keras的Flatten操作可以视作pytorch中的view
模型输入
| 区别 |
pytorch |
keras |
| API |
torch.tensor |
Input |
| 形状 |
NCHW |
NHWC |
|
需要显示声明input_channels |
不需要input_channels,函数内部会自动获得 |
>API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。
NCHW和NHWC:
N代表数量, C代表channel,H代表高度,W代表宽度.
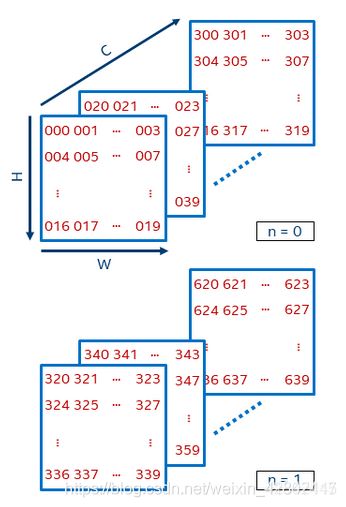

NCHW和NHWC
a = torch.randn(1,4,160,160)
a = Input(shape = (160, 160, 4), batch_size = 1)
卷积
| 区别 |
pytorch |
keras |
| API |
nn.Conv2D |
Conv2D |
| padding |
任意输入一个值 |
'valid’没填充,'same’有填充 |
| 输入通道 |
参数有输入通道 |
没有输入通道 |
padding:在原始图像的边缘用了像素填充
self.conv = Conv2d(in_channels, out_channels, kernel_size, stride, padding=padding, bias=bias)
output = Conv2D(input.shape[-1] // reduction, kernel = (1,1), padding = "valid", use_bias = False)(output)
反卷积
| 区别 |
pytorch |
keras |
| API |
nn.ConvTranspose2d |
Conv2DTranspose |
| 输入通道 |
参数有输入通道 |
没有输入通道 |
self.dconv = nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, bias=bias)
output = Conv2DTranspose(out_channels, kernel_size, stride, use_bias=bias)(input)
上采样
| 区别 |
pytorch |
keras |
| API |
nn.UpsamplingBilinear2d |
没有,需要自定义 |
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
import tensorflow.compat.v1 as tf
def my_upsampling(x,img_w,img_h,method=0):
"""0:双线性差值。1:最近邻居法。2:双三次插值法。3:面积插值法"""
return tf.image.resize_images(x,(img_w,img_h),0)
output = Lambda(my_upsampling,arguments={'img_w':input.shape[2] * 2,'img_h':input.shape[1] * 2})(input)
池化
| 区别 |
pytorch |
keras |
| API |
nn.AdaptiveAvgPool2d(1) |
没有自适应池化,需要利用自定义池化自定义 |
BatchNormalization
| 区别 |
pytorch |
keras |
| API |
nn.BatchNorm2d |
BatchNormalization |
| 输入通道 |
参数有输入通道 |
没有输入通道 |
nn.BatchNorm2d(in_size),
output = BatchNormalization()(output)
激活
| 区别 |
pytorch |
keras |
| API |
nn.ReLU |
Activation |
self.act = nn.Sigmoid()
self.act = nn.ReLU
output = Activation("sigmoid")(output)
output = Activation("relu")(output)
pytorch模型流程
class D():
def __init__(self, init_age):
print('我年龄是:',init_age)
self.age = init_age
def __call__(self, added_age):
res = self.forward(added_age)
return res
def forward(self, input_):
print('forward 函数被调用了')
return input_ + self.age
print('对象初始化。。。。')
a = D(10)
input_param = a(2)
print("我现在的年龄是:", input_param)
对象初始化。。。。
我年龄是: 10
forward 函数被调用了
我现在的年龄是: 12
1)__init__主要用来做参数初始化用,如 conv、pooling、Linear、BatchNorm 等,这点和tf里面的用法一样
2)forward是表示一个前向传播,构建网络层的先后运算步骤
3)__call__的功能和forward类似,所以很多时候,可以用__call__替代forward函数,两者区别是当网络构建完之后,调__call__的时候,会去先调forward,即__call__其实是包了一层forward,所以会导致两者的功能类似。
实现VGG16过程对比
'''
#pytorch---引入库
import torch
import torch.nn as nn
from .utils import load_state_dict_from_url
'''
from keras.models import Sequential
from keras.layers import Dense, Flatten
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
'''
#pytorch---搭建VGG16网络结构
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
'''
def generate_vgg16():
input_shape = (224, 224, 3)
model = Sequential([
Conv2D(64, (3, 3), input_shape=input_shape, padding='same', activation='relu'),
Conv2D(64, (3, 3), padding='same', activation='relu'),
MaxPooling2D(pool_size=(2,2), strides=(2,2)),
Conv2D(128, (3, 3), padding='same', activation='relu'),
Conv2D(128, (3, 3), padding='same', activation='relu'),
MaxPooling2D(pool_size=(2,2), strides=(2,2)),
Conv2D(256, (3, 3), padding='same', activation='relu'),
Conv2D(256, (3, 3), padding='same', activation='relu'),
Conv2D(256, (3, 3), padding='same', activation='relu'),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Conv2D(512, (3, 3), padding='same', activation='relu'),
Conv2D(512, (3, 3), padding='same', activation='relu'),
Conv2D(512, (3, 3), padding='same', activation='relu'),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Conv2D(512, (3, 3), padding='same', activation='relu'),
Conv2D(512, (3, 3), padding='same', activation='relu'),
Conv2D(512, (3, 3), padding='same', activation='relu'),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Flatten(),
Dense(4096, activation='relu'),
Dense(4096, activation='relu'),
Dense(1000, activation='softmax')
])
return model
model = generate_vgg16()
model.summary()
训练
用Keras训练模特只需.fit()
history = model.fit_generator(
generator=train_generator,
epochs=10,
validation_data=validation_generator)
在Pytorch中训练模型包括以下几个步骤:
- 在每批训练开始时初始化梯度
- 前向传播
- 反向传播
- 计算损失并更新权重
for epoch in range(2):
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
参考文章
pytorch转keras
keras pytorch 构建模型对比
keras 和 pytorch