基于企鹅数据集的决策树实战
基于企鹅数据集的决策树实战
实践要求:导入基础的函数库包括:numpy(Python进行科学计算的基础软件包),pandas(pandas是一种快速,强大,灵活且易于使用的开源数据分析和处理工具),matplotlib和seaborn绘图。
数据集下载地址:
https://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/6tree/penguins_raw.csv
实践步骤:
Step1:库函数导入
import numpy as np
import pandas as pd
import matplotlib as plt
import seaborn as sns
Step2:数据读取/载入
data = pd.read_csv(open(r'D:\算法作业\penguins_raw.csv'))
Step3:数据信息简单查看
>>>print(data.info())

data = data.fillna(-1)# 将缺失值补全
## 利用value_counts函数查看每个类别数量
print(pd.Series(data['Species']).value_counts())

Step4:可视化描述
仅从数据集中选择了几个特征
data = data[['Species','Culmen Length (mm)','Culmen Depth (mm)',
'Flipper Length (mm)','Body Mass (g)']]
sns.pairplot(data=data, diag_kind='hist', hue= 'Species')
plt.show()
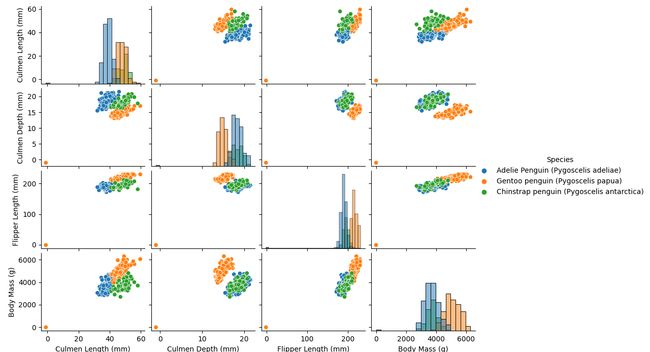
# 将分类变量转化成数字变量,方便后续计算
def translate(x):
if x == data['Species'].unique()[0]:
return 0
if x == data['Species'].unique()[1]:
return 1
if x == data['Species'].unique()[2]:
return 2
data['Species'] = data['Species'].apply(translate)
for col in data.columns:
if col != 'Species':
sns.boxplot(x='Species', y=col, saturation=0.5, palette='pastel', data=data)
plt.title(col)
plt.show()
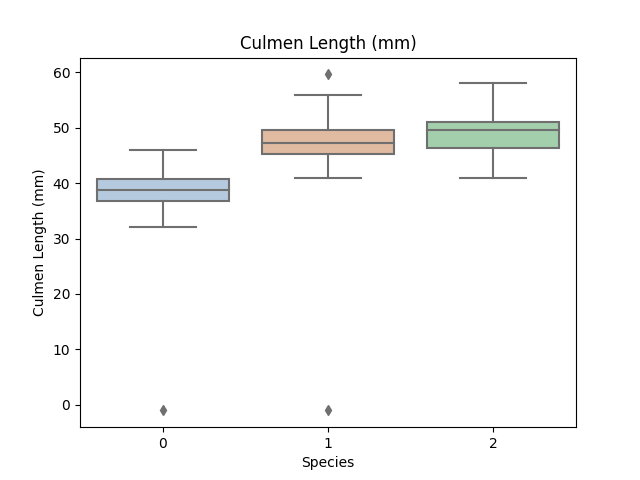
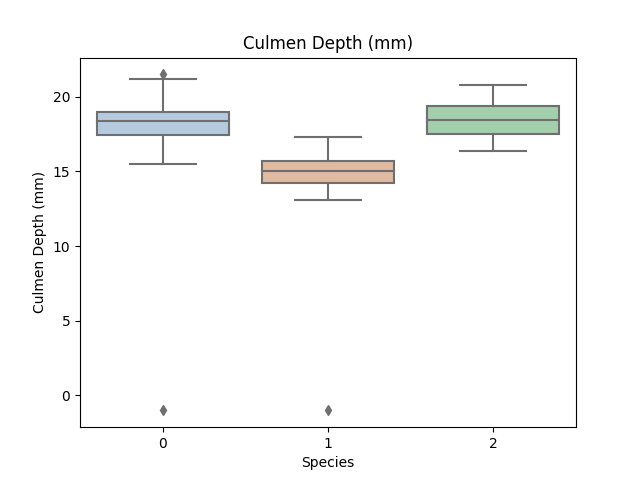

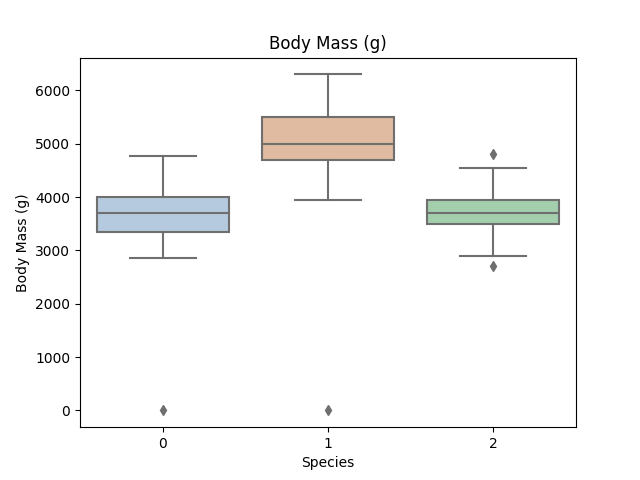
Step5:利用决策树模型在二分类上进行训练和预测
data_target_part = data[data['Species'].isin([0,1])][['Species']]
data_features_part = data[data['Species'].isin([0,1])][['Culmen Length (mm)','Culmen Depth (mm)','Flipper Length (mm)','Body Mass (g)']]
from sklearn.model_selection import train_test_split
from sklearn import metrics
# 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
x_train, x_test, y_train, y_test = train_test_split(data_features_part,data_target_part,test_size=0.2,random_state=2020)
# 导入决策树模型
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
## 定义 决策树模型
clf = DecisionTreeClassifier(criterion='entropy')# 信息熵,根据信息增益来划分
# 在训练集上训练clf模型
clf.fit(x_train, y_train)
## 在训练集和测试集上分别利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('准确度:', metrics.accuracy_score(y_train, train_predict))
print('准确度:', metrics.accuracy_score(y_test, test_predict))
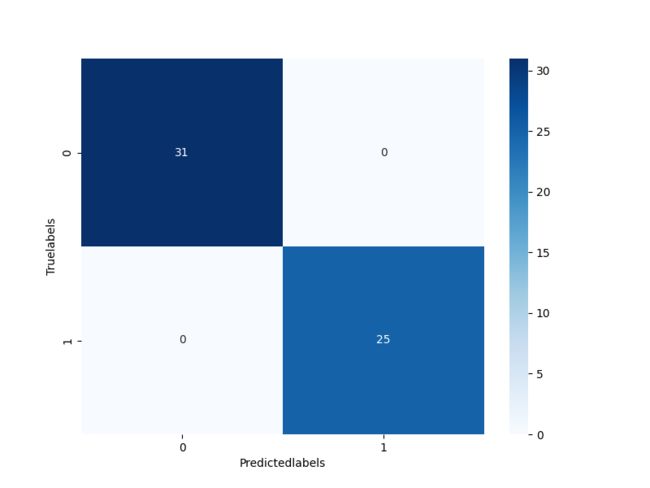
## 查看混淆矩阵
confusion_matrix_result = metrics.confusion_matrix(test_predict, y_test)
print('混淆矩阵结果:\n', confusion_matrix_result)
plt.figure(figsize=(8, 6)) # 指定figure的宽和高,单位为英寸
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predictedlabels')
plt.ylabel('Truelabels')
plt.show()
准确度: 0.9954545454545455
准确度: 1.0
Step6:利用决策树模型在三分类(多分类)上进行训练和预测
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(data[['Culmen Length (mm)', 'Culmen Depth (mm)',
'Flipper Length (mm)', 'Body Mass (g)']], data[['Species']],
test_size=0.2, random_state=2020)
## 定义 决策树模型
clf = DecisionTreeClassifier(criterion='entropy')
# 在训练集上训练决策树模型
clf.fit(x_train, y_train)
## 在训练集和测试集上分别利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('准确度:', metrics.accuracy_score(y_train, train_predict))
print('准确度:', metrics.accuracy_score(y_test, test_predict))
## 查看混淆矩阵
confusion_matrix_result = metrics.confusion_matrix(test_predict, y_test)
print('混淆矩阵结果:\n', confusion_matrix_result)
准确度: 0.9963636363636363
逻辑回归准确度: 0.9710144927536232
