最常用的9个机器学习算法,解决99%的业务问题!
对于了解机器学习的人来说,数据挖掘无疑是一个范围更大且钱力无限的方向。但随着这两年越来越多的有IT编程经验的职场老鸟转行到数据分析大赛道,企业对人才的要求也越来越高了。前一阵,广大码农们被官方划成了“新生代农民工”,引起了咱圈里或多或少的不服不忿。咱作为技术人才,怎么就成了工具人了?
算法岗的你也别不服气,问个问题:虽然手上掌握大几套算法理论,但换个应用场景或业务需求,你还那么底气十足吗?
01
技术侧的数据挖掘,你缺了啥?
我在互联网公司工作多年,看过大量的类似案例,给我最深的感觉就是:同样一个算法大多用在同样的业务场景。我们在做精准营销的时候,大家往往会用逻辑回归做一个,神经网络再做一个,然后对比两者之间的结果,再从中选择最优者,其实这样的研究很多时候只能说是在浪费资源。
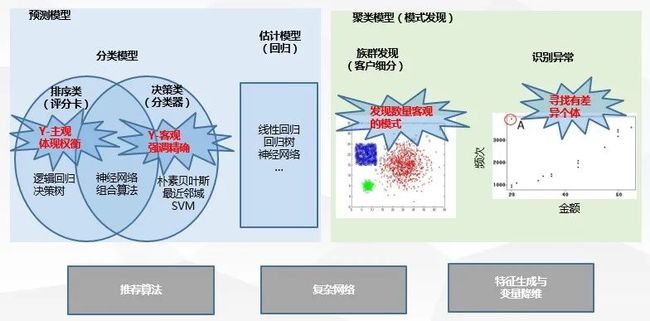
因为大家都知道神经网络是非线性模型,效果肯定好。但是做研究的目的并不是为了创造一个神经网络算法,所以类似的研究结果没有任何实质意义。
长此以往下,精于算法理论的你会产生一种挫败感:费了这么大功夫,产生的价值只是测试了这套算法的可行性。至于当被质问如何能用算法更好解决复杂多变的实际业务问题时,可能在一脸沧桑的淡定面孔下是慌乱一批的心。
所以,如果你才刚踏入这个行业或者还有心力把能力和薪资都往上提一提,那么你一定要看看更值钱的那批顶尖的人,除了技术比你强在哪里。


我们分析了BOSS上的3000个算法岗位发现,想要拿到年薪百万,把算法应用摸透了或者说将算法用到该用到的地方是你一定要具备的能力。

02
企业对数据的需求点
在企业当中,数据主要是为了支持我们做决策,一般也就是在四个层级产生价值:战略、管理、运营和操作。
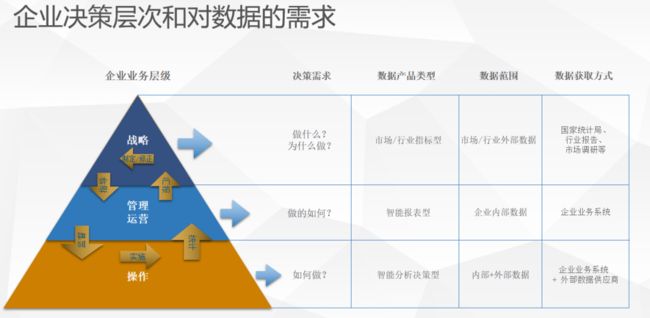
战略层级,毋庸置疑,C-Level的这群企业高管一般要定的是1年周期计划或是3-5年的战略方向。哪个赛道有机会?企业增长点在哪里?这时候,主要用到的是PEST分析,通过研究报告、行业分析、宏观经济等维度,对数据进行直接的采集和应用。
第二层级就是我们企业的中坚力量——重要部门的管理者,这一Part考验的是咱数据人商业策略的优化能力。再往下每个分支机构的管理者,就是咱最基层的广大执行部门小领导了。数据在这个层面主要就是以报表的形式帮助管理者进行业务决策。
最下面一个层级的执行操作层环境复杂,工作繁复,拿着民工的钱操着老板的心。这一层级绝对是数据和算法岗相爱相杀的好战友,既依赖你给策略又埋怨你不落地。如果你不懂应用场景,怎么能搞定这帮眼冒绿光的狼人呢?
比如做节点大促,需要通过你的算法支持进行用户运营和市场触达。如果你不清楚用户画像、没搞明白前后端的部门协同关系、SOP流转关键结点和流量的转化路径,再牛的算法理论都只能是纸上谈兵。
不管哪个行业,都需要这样一个能给操作层级进行AI赋能,让业务效果肉眼可见的蹭蹭涨起来的数据大神。
03
掌握解决你99%业务问题的算法绝对不靠耗命
看了上面这些,你一定想问:算法在我们实际工作中到底能应用于哪些领域?
在波特的价值链模型中,真正产生价值的是哪些呢?主要集中在最下端的基本活动。
比如说我们是卖手机的,从进料、后勤生产、后勤销售、售后服务,这个就是我们真正的价值链。
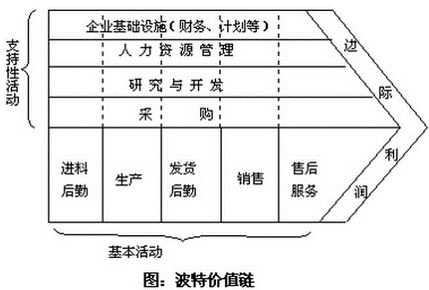
我们说工业革命,其实是实现了制造业的自动化,使得我们的物质极为丰富了。那么这次数字化,其实是在非生产领域产生颠覆性的价值体现。
有些学者会认为,生产领域也是数字化转型很重要的一个部分,这点不可否认。但是我们说在数字化概念提出之前,像德国这种制造业的老牌国家,它的生产领域已经非常智能,基本上实现了机器人的完全自动化。
那么问题来了,人家在数字化概念提出之前,就已经实现了完全智能化,那么我们的数字化特点体现在哪里?就像我上文所说的,非生产领域是我们数字化转型的重点方向。比如说库存管理阶段的进料、后勤、发货,销售营销,数字化运营,售后服务,还有研究与开发等等。
此外,如人力资源管理和一些其他的企业基础设施,比如说财务,在这次的数字化革命当中,体现的也非常多。
价值链上环节那么多,如果你还是不懂变通的花费大量精力去啃那些只适用于固定场景的算法理论,那么我劝你不如看看我们总结的能解决你99%业务需求的“三大分析范式,九大算法模板”。
04
三大分析范式,九大算法模板
学术研究讲求标新立异,而数据挖掘商业应用实践讲求的是标准化和模型质量稳定。因此CDA.F认证委员会提出数据挖掘建模框架的三个原则,即以成本-收益分析为单一分析框架、区分分析主体和客体两个视角、全模型生命周期工作模板。并且将纷繁多样的数据挖掘应用主题归纳为以下“三大分析范式和九大算法模板”。
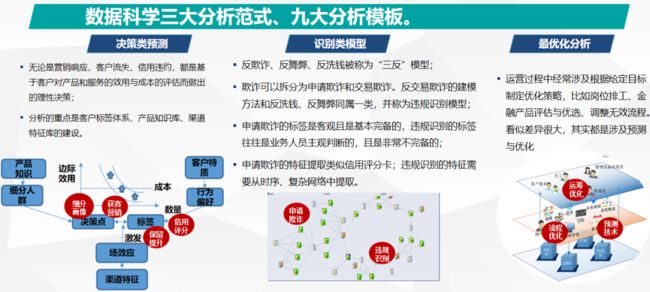
想要用好这些范式和模板,首先要明确的是要以“成本-收益分析”为单一分析框架。
世界万事万物都具有矛盾的两面性,数据挖掘建模力图通过数据反应行为背后的规律,紧抓主要矛盾就是找寻规律的捷径。大家都知道,挖掘有效的入模特征是数据挖掘建模的难点,一旦我们了解了分析课题的主要矛盾,这个难点就迎刃而解了。“天下熙熙皆为利来,天下攘攘皆为利往”,因此行为分析建模以成本-收益为主要矛盾便是不二的选择。下面讲解如何使用这个框架进行分析。
以金融行业为例,举三个常见应用:
01
信用评分模型中,是否逾期是被预测变量,而解释变量中经常出现的收入稳定性、职业稳定性、家庭稳定性、个人社会资本都是在度量其违约成本。信用历史既是被解释变量的滞后项,而且也反应了违约成本,这就是所谓“破罐子破摔”的人违约程度低。收益会用贷存比、贷收比、首付占比等指标来衡量。
02
申请欺诈模型,其标签往往是客观存在的。入模的特征构建以反应异常为主,比如异常高的收入、异常高的学历、异常密集的关系人网络等。这背后有其统一的成本-收益分析框架。之所以会显示出异常,是因为造假是有成本的,信用卡申请欺诈者知道收入证明造假可以获得更高的信用额度,但是由于其居住地、职业和学历没有造假,因此按照这三个维度对其收入进行标准化之后很容易发现其收入会异常的高。这个可以说是公开的秘密,因为信用卡公司会根据造假成本对非可靠申请者进行授信,使得欺诈者无利可图。
03
运营优化模型比如资产组合的持仓问题,其收益是资产的收益率,而成本是其带来的风险,即波动率。建模人员需要选择收益-成本最优的组合。
其次是要区分分析主体和客体两个视角。
在数据挖掘建模中,定义标签是主体视角。比如营销预测模型中客户是否响应,是建模人员自己定的规则,这个规则有可能是收到营销短信后三天内注册账号并产生订单。在构建入模的特征集时需要采用客体视角,比如手机银行的营销响应模型中,入模的特征应该反应客体的成本-收益的变量,比如年龄反应的是使用手机银行和去实体渠道的成本。当建模人员意识到标签是自己主观臆断的时候,便会对该标签的选择更用心,当意识到入模的特征来自于客体时,才会从客体的视角出发更高效的构建特征集。
最后讨论全模型生命周期工作模板。
CDA.F认证委员会在CRIP-DM和SEMMA的基础上提出 “高质量数据挖掘模型开发的七步法”。在以上七步中,前三步是蓄势阶段,更多的是从业务人员、数据中吸收经验、形成感知。制作特征、变量处理和建立模型阶段是丰富特征、寻找有效模型的阶段,几十个变量和一两个模型显然是没什么选择必要性的,因此需要通过各种手段探查到最有效的特征和精度最高的模型。最后,模型输出阶段,选出的模型不但精度高,还要稳定性强,在业务人员使用时要有清晰的业务表述。
9月15日晚8点直播课
CDA邀请数据分析大咖常国珍老师
实力(实例)演绎
敏捷算法建模训练营精讲系列第二期
为大家带来更详尽的
数据科学的“三大分析范式,九大算法模板”讲解
助你实现从BI到AI的能力跃层
解决实际业务问题,结果好,效率高
成为老板捧在心尖上的香饽饽
嘉宾介绍
常国珍
CDA科学研究院执行院长
腾讯云最有价值专家(TVP)
前毕马威咨询大数据总监
中银消费金融数据部高级经理
直播主题
「超实用案例分享
解决99%业务问题的算法建模模板」
扫描下图二维码
0元抢实战案例直播课,领取训练营资料
????????????
