数据导入与预处理——综合实验:网络招聘信息ETL自动化工程
文章目录
- 1. 实验内容
- 2. 问题解答
-
- 2.1 字段描述
- 2.2 自动化工程作业设计编排
-
- 2.2.1 总体设计
- 2.2.2 步骤设计
- 2.3 使用Kettle开发数据转换,完成数据导入、转换与导出
-
- 2.3.1 总体设计
- 2.3.2 步骤设计
- 2.4 成果展示
-
- 2.4.1 执行情况
- 2.4.2 最终数据输出
- 3. 常见错误处理
-
- 3.1 邮件问题
- 3.2 不能使用快捷键问题
- 3.3 对xml与json文件的树状显示
1. 实验内容
为了分析国内就业形势,指导毕业生求职,学校准备建立一个招聘信息发布平台。该平台设计从网络定期采集招聘网站信息并通过ETL工程完成数据自动化导入,ETL部分设计如下:
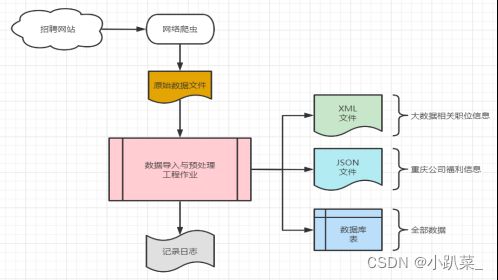
你需要通过Kettle创建一个ETL工程,完成从对原始数据文件的导入和预处理,实现以下数据需求:
1.数据转换要求
| 字段名 | 字段描述 | 转换要求 |
|---|---|---|
| 职位 | 职位名称,字符串 | |
| 公司 | 招聘单位,字符串 | |
| 平均薪资 | 平均薪资,字符串 | 统一到以单位“元/月”的整数,“面议”设置为空 |
| 地区 | 地区,字符串 | |
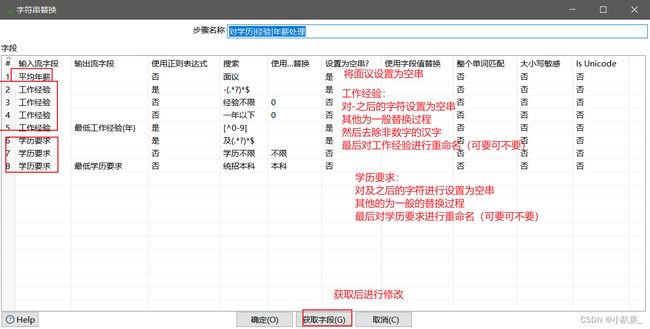
| 学历要求 | 学历要求,字符串 | 转换为最低学历要求,只包含【 不限,中职/中技, 大专, 本科, 硕士, MBA,博士 】 |
| 工作经验 | 工作经验,整数 | 转换为最低工作经验要求,“不限”和“1年以内”都用0表示 |
| 福利待遇 | 福利待遇,字符串 |
2.数据输出要求
(1)将大数据相关的职位信息以XML(.xml)文件格式导出。XML文件结构如下:
<jobs>
<job name=“大数据开发工程师”>
<company>中国太平洋保险(集团)股份有限公司招聘单位>
<salary>20000salary>
<region>上海region>
<edu>本科edu>
<exp>3<exp>
job>
jobs>
(2)将重庆招聘单位及其福利待遇信息以JSON(.json)文件格式导出。JSON文件结构如下:
{
"data": [
{
"company": "华夏航空",
"benefits": ["带薪年假","交通补助","午餐补助","定期体检","五险一金"]
}
]
}
注:只保存1个json文件;不包括重复记录。
(3)将原始数据全部字段存入MySQL数据库中保存。(数据库表结构自行设计创建)
3.工程要求
(1)工程作业可通过配置文件(.properties)进行设置文件路径,数据库连接参数等
(2)工程作业可自行创建目标数据库表(通过sql脚本)
(3)转换作业项需配置合理的监控步骤(如:保存日志记录、发送邮件等)
4.答题要求:
(1)文件名使用“姓名_学号_”前缀(如:张三_2020123456_转换1.ktr, 张三_2020123456_大数据职位信息.xml)
(2)请将完整的作业/转换全流程截图附在答题页上;
(3)请提供每个作业项/转换步骤/数据库连接的关键设置页面截图;
(4)请提供作业/转换运行结果及最终数据(数据库表、文件内容等)截图;
(5)请提供作业文件(.kjb)、转换文件(.ktr)、配置文件(.properties)、日志文件(.log)等附件;
5.数据源:
链接:https://pan.baidu.com/s/1wxKhy_-kJR21hXHJYQajkQ?pwd=k8e7
提取码:k8e7
2. 问题解答
首先从整个题目进行分析:整个项目是多个作业项,这些作业项是以某种顺序来执行。我们需要编排自动化作业。该工程顺序因人而异,得到的大数据工作流程也会不同,但是整体的大概方向是一致的:数据采集、数据导入、数据预处理、数据存储、数据挖掘与应用。中间的过程也是因人而异。下面我将分享一种自己的工程作业顺序经供参考。
步骤如下:
对数据进行初步分析,找出数据字段问题描述;自动化工程作业设计编排(因为这里存在模板可以套用,我为了方便就首先配置了工程作业,以变后续作业中方便操作);使用Kettle开发数据转换,完成数据导入、转换与导出
2.1 字段描述
| 字段 | 问题描述 | 示例 |
|---|---|---|
| 平均年资 | 该字段没有统一单位(元/月)以及不是整数,面议不为空,且字段名需要改为平均薪资(元/月)(注:这里单位可加可不加,我认为这样更加通俗易懂,因人而异) | 面议、45万/年、5千/月 |
| 学历要求 | 该字段包含全部学历要求,不是最低学历要求,且字段名改为最低学历要求(注:这里的字段名可改可不改,我认为这样更加通俗易懂,因人而异) | 统招本科、本科及以上、学历不限 |
| 工作经验 | 该字段不是最低工作要求,而且不为整数(不限跟一年以下为0)且字段名需要改为最低工作经验(注:这里的字段名可改可不改,我认为这样更加通俗易懂,因人而异) | 不限、一年以下、1-3年 |
| 公司 | 该字段存在*****认为其是错误字段(注:这里因人而异,你可以忽略它,但是一般在工程中这种是不可忽略的,还可以对整个工程进行相似匹配赋值等等) | ******** |
| 职位 | 无 | |
| 地区 | 无 | |
| 福利待遇 | 该字段存在空字符串,但是根据实际情况也可以认为真实存在。(注:根据实际情况我认为是存在这种的,福利待遇他并没有写到他的招聘上,我认为他是可以合理存在的,因人而异) | [ ] |
2.2 自动化工程作业设计编排
在 小趴菜_2020000000_作业配置.kjb 文件完成
2.2.1 总体设计
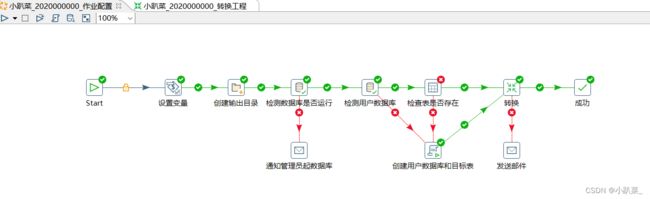
2.2.2 步骤设计
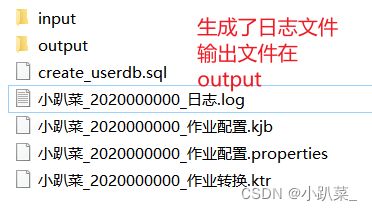
首先在你的目录创建以下文件(不是直接创建名字之类的,有些需要在kettle中创建)
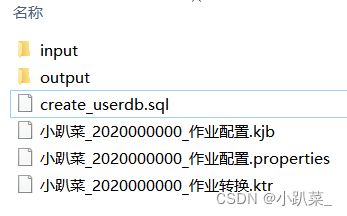
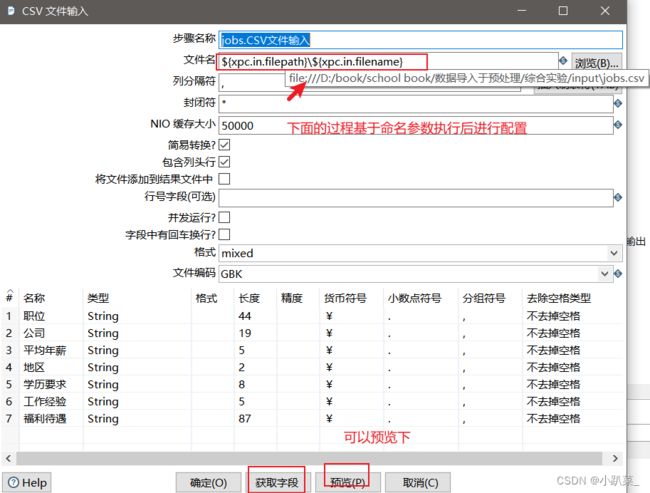
解释:input是输入的jobs.csv文件,output是即将输出的文件,其他的目录名+后缀明显。
1. 对 小趴菜_2020000000_作业配置.properties 配置文件编写命名参数
# 综合实践转换中定义的命名参数
xpc.db.defaultdb=mysql
xpc.db.host=localhost
xpc.db.port=3306
xpc.db.name=mydb
xpc.db.user=root
xpc.db.pass=root
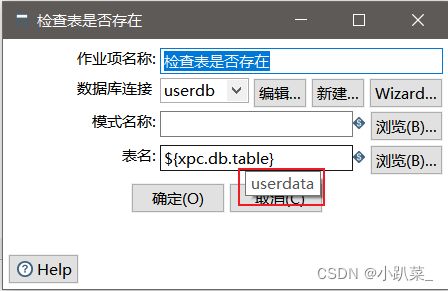
xpc.db.table=userdata
# 各种路径
# 创建数据库名称
xpc.sql.file=${Internal.Entry.Current.Directory}/create_userdb.sql
xpc.ktr.file=${Internal.Entry.Current.Directory}/小趴菜_2020000000_作业转换.ktr
# 输出路径
xpc.out.filepath=${Internal.Entry.Current.Directory}/output
# xml输出
xpc.out.filename1=小趴菜_2020000000_大数据职位信息
# json输出
xpc.out.filename2=小趴菜_2020000000_招聘待遇信息
# 输入路径
xpc.in.filepath=${Internal.Entry.Current.Directory}/input
xpc.in.filename=jobs.csv
2. 工程作业设计步骤
start作业定时调度(步骤:通用|start)
把小趴菜_2020000000_作业配置.properties 配置文件导入到设置变量中
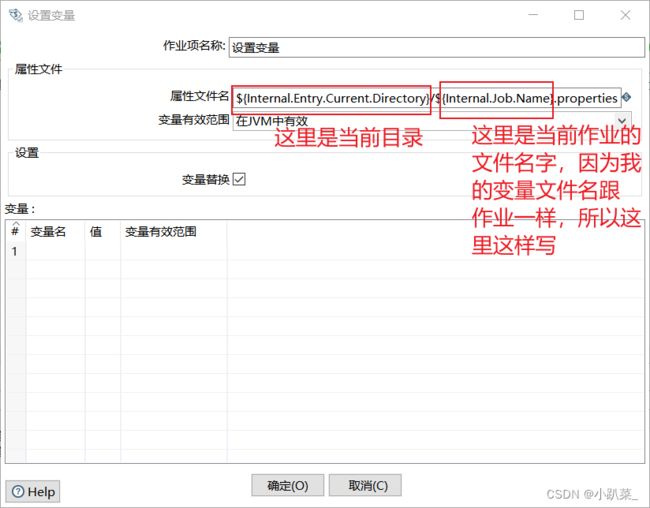
创建输出目录
在执行过前面配置文件后,配置文件里的参数变量就可以在后续使用了(使用中,鼠标指在目录上就会显示名字)
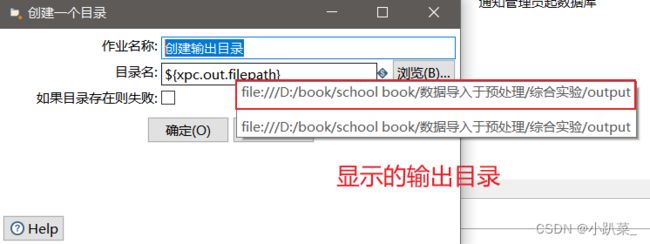
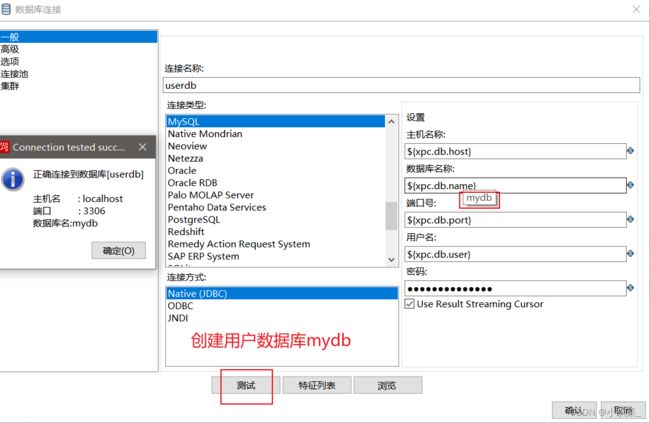
检测数据库是否运行
首先新建mysql数据库连接
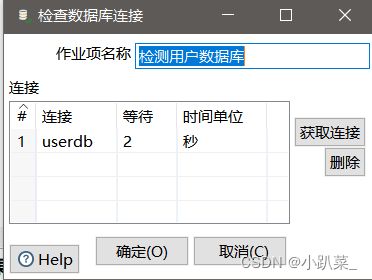
然后进行检查数据库的连接
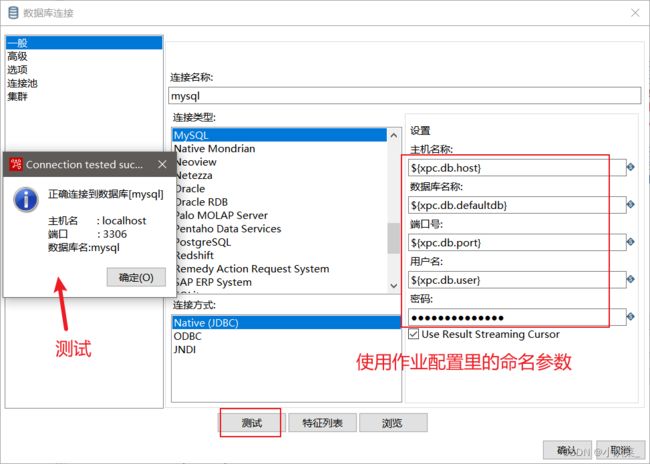
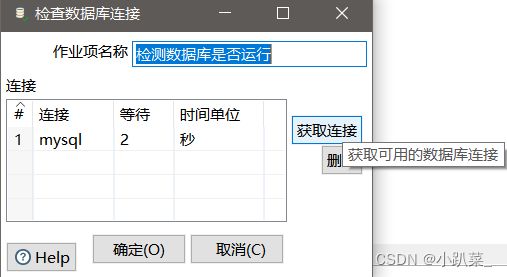
成功:检测用户数据库
同样步骤:首先创建用户数据库
然后进行检查用户数据库mydb
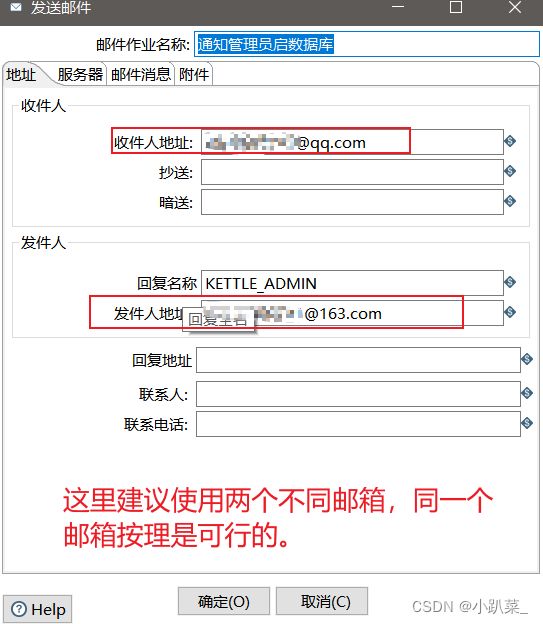
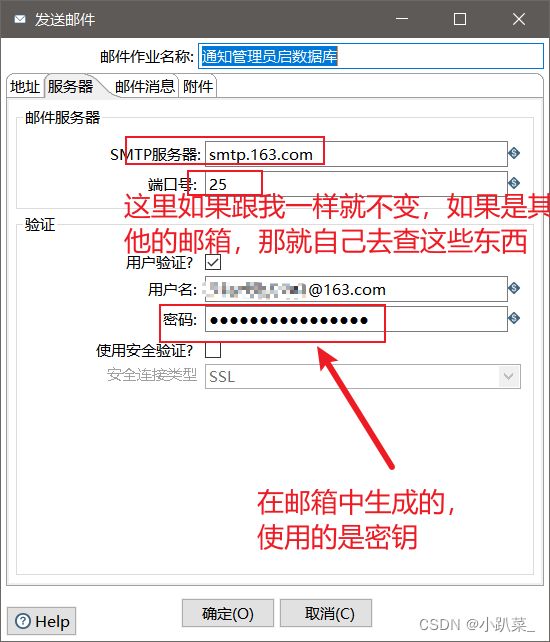
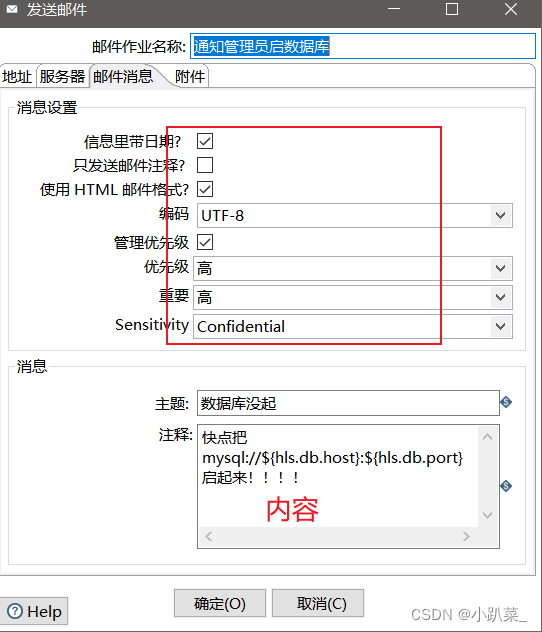
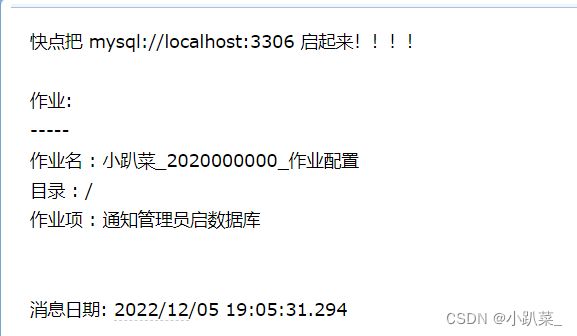
失败:进行通知管理员起数据库
(这里可能会出现错误,要开通邮件服务授权码。使用授权码进行登录,所有的问题该过程不予解释,如果出现了此类问题请跳转到文末:**常见错误处理**)地址
服务器
(这里密钥指授权码)
邮件信息
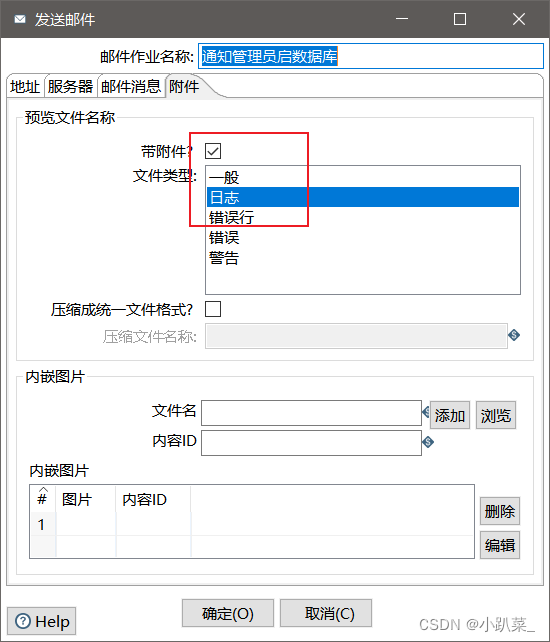
附件
检查用户数据库成功:检查表是否存在
检查用户数据库或检查表是否存在执行失败:创建用户数据库和目标表
(注:这里得出的sql语句是在转换步骤中提取过来的,如果是先做的自动化作业是暂时不知道sql语句的,需要把转换完成后再来补充sql语句,我这里提前拿过来了)
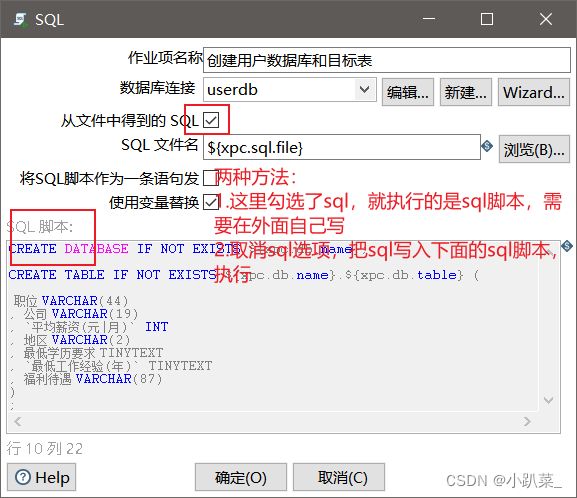
create_userdb.sql语句
CREATE DATABASE IF NOT EXISTS ${xpc.db.name};
CREATE TABLE IF NOT EXISTS ${xpc.db.name}.${xpc.db.table} (
职位 VARCHAR(44)
, 公司 VARCHAR(19)
, `平均薪资(元|月)` INT
, 地区 VARCHAR(2)
, 最低学历要求 TINYTEXT
, `最低工作经验(年)` TINYTEXT
, 福利待遇 VARCHAR(87)
)
;
都成功:进入转换步骤
options
设置日志
命名参数
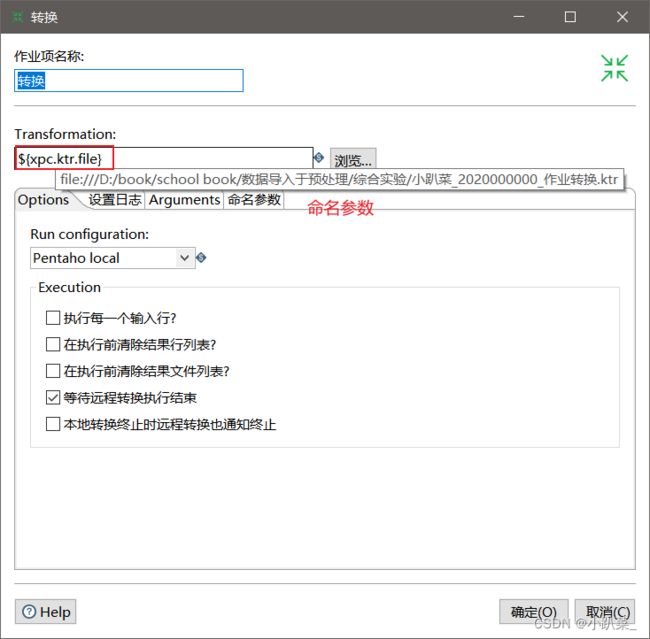
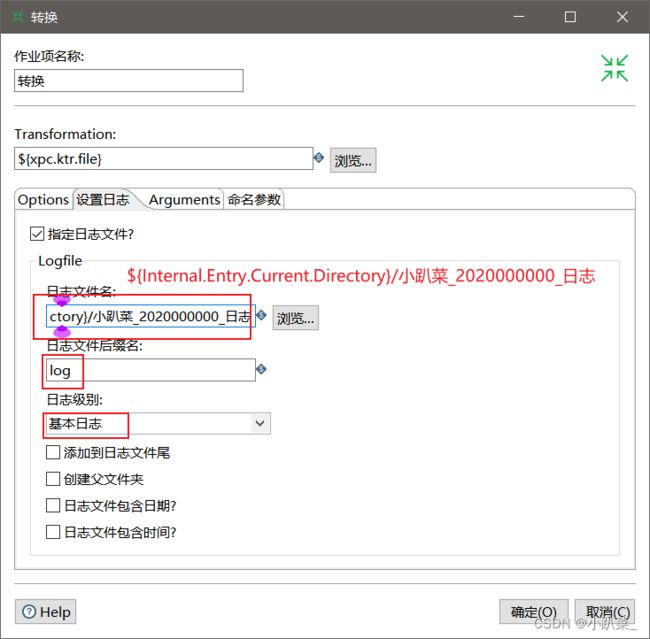
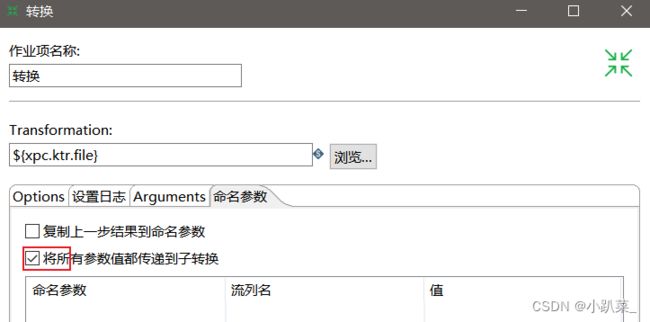
转换执行错误:同样进行发送邮件
内容跟前面邮件配置一样,只是邮件内容不一样。
成功
以上过程就是自动化工程作业设计编排
2.3 使用Kettle开发数据转换,完成数据导入、转换与导出
在 小趴菜_2020000000_作业转换.ktr 文件进行完成
2.3.1 总体设计
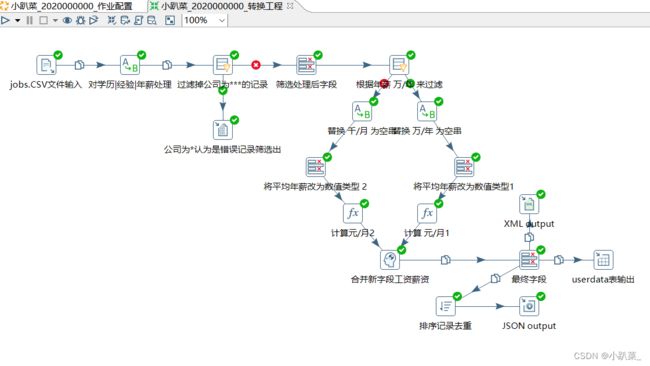
2.3.2 步骤设计
jobs.CSV文件输入
对学历|经验|年薪字段进行处理
过滤掉公司为**的记录
(注:这里是通过数据发现的,你可以发现更多你认为不正确的数据进行处理)

正确执行的错误的数据到日志里
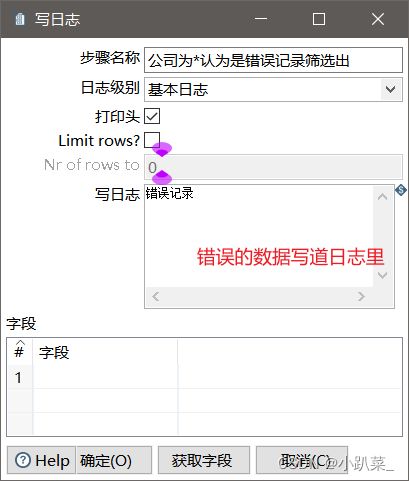
错误执行结果为正确的数据进行筛选处理
选择和修改
元数据
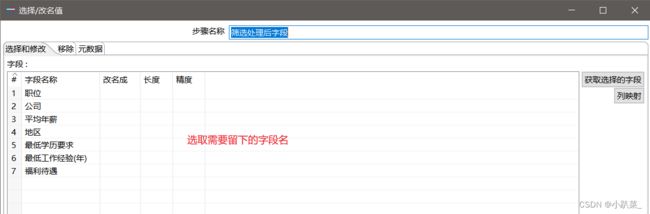
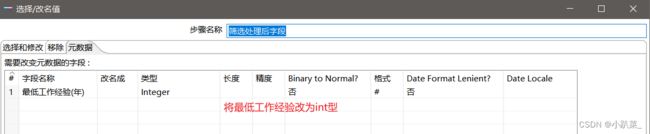
根据年薪 万/年 来过滤,以便进行后面步骤的计算

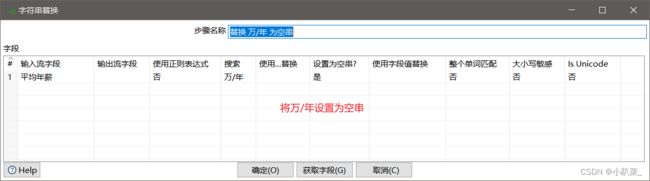
万/年数据的处理
替换 万/年 为空串
将平均年薪改为数值类型1方便进行计算
用公式计算平均年薪

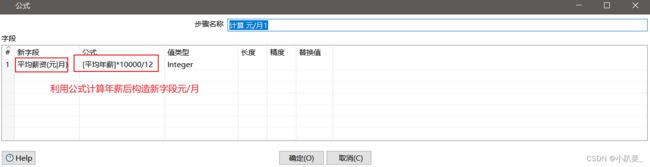
同理可得对其他的数据处理:处理过程跟万/年步骤一样
用空操作合并字段
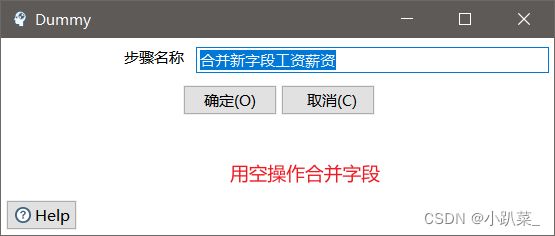
得到最终字段
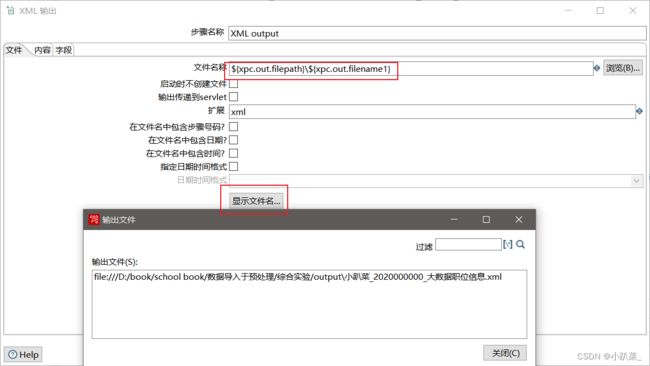
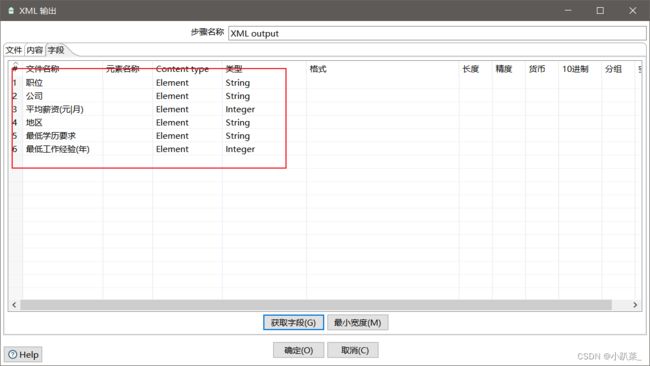
输出步骤:小趴菜_2020000000_大数据职位信息.xml 文件输出
文件
字段
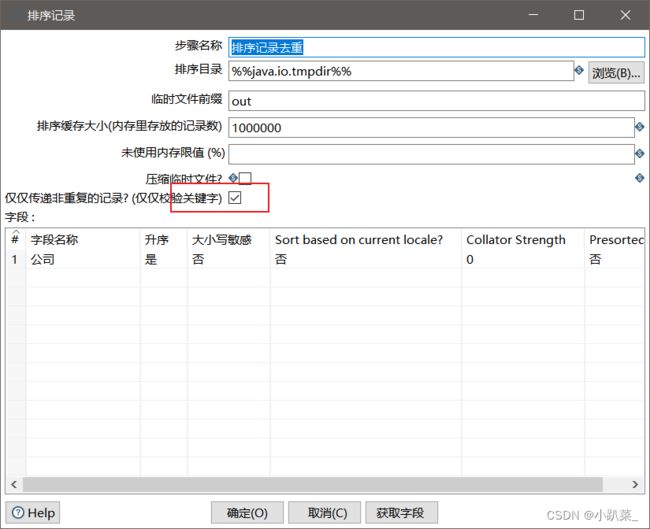
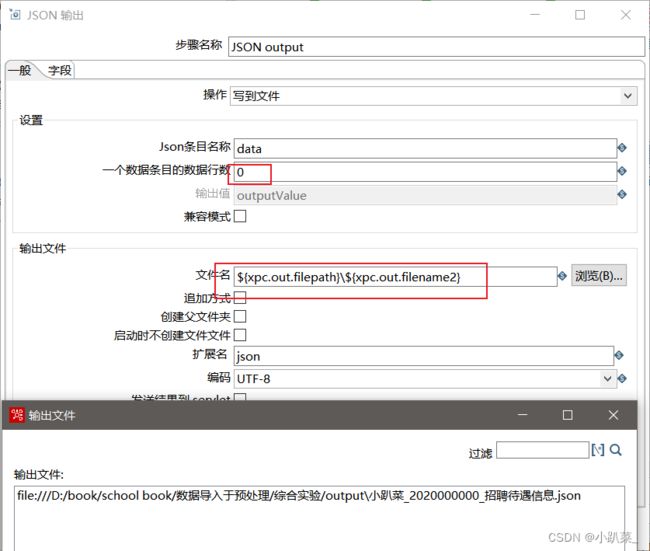
输出步骤:小趴菜_2020000000_招聘待遇信息.json 文件输出
首先排序记录进行去重
json输出
一般
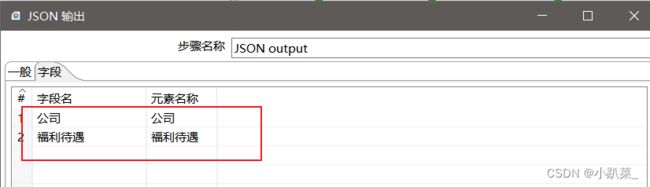
字段
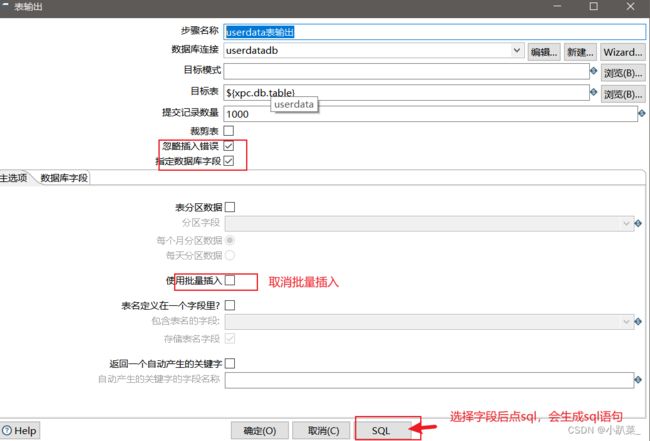
userdata表输出
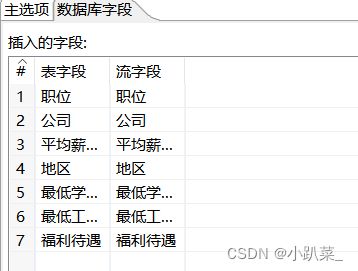
数据库·字段
2.4 成果展示
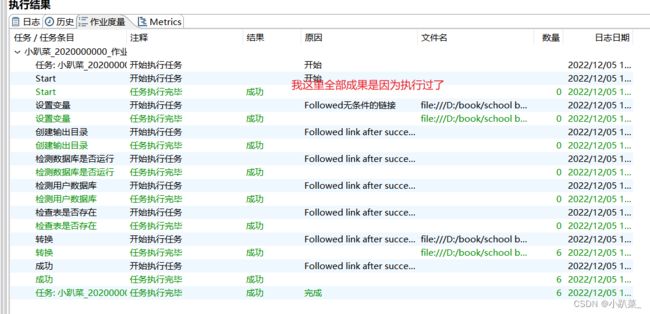
2.4.1 执行情况
作业度量
关闭sql服务器进行演示发送邮件
然后在执行作业,在邮件中可以看见接收到的文件
2.4.2 最终数据输出
小趴菜_2020000000_大数据职位信息.xml 文件

小趴菜_2020000000_招聘待遇信息.json 文件

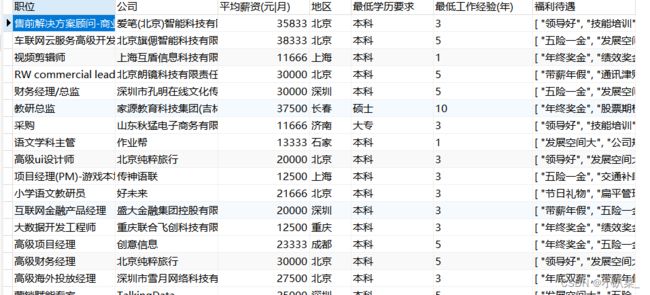
数据库userdata表文件
3. 常见错误处理
3.1 邮件问题
例如我是163邮件
首先登录进去


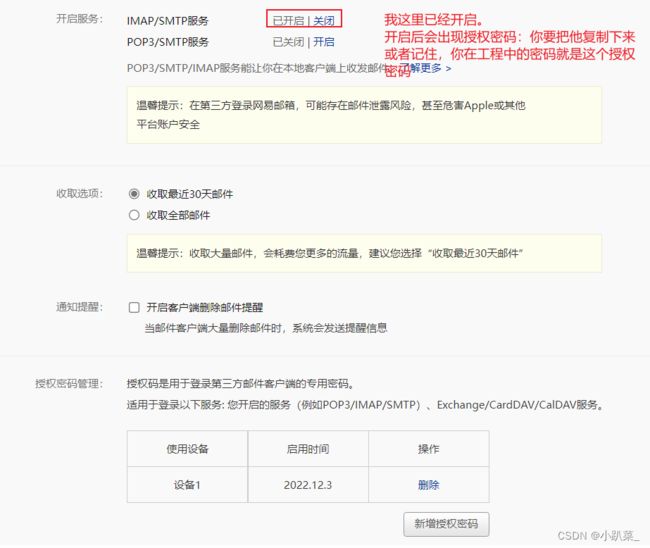
3.2 不能使用快捷键问题
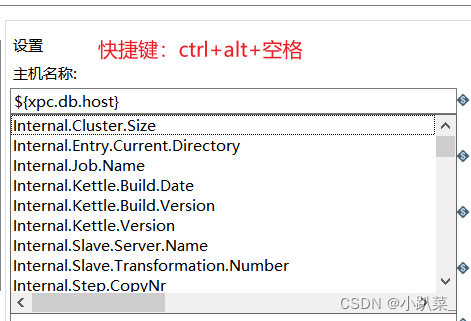
很多人因为快捷键重复,所以在kettke中不能直接使用快捷键。为了方便这里我说明可能大家重复的快捷键的关闭
可能重复的快捷键(我自己的问题)
在电脑自带的输入法中有一个快捷键重复了
右击输入法进入按键设置
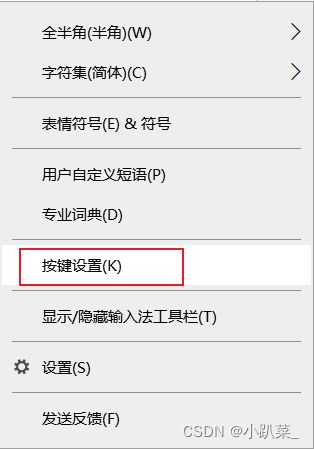
关闭ctrl+空格
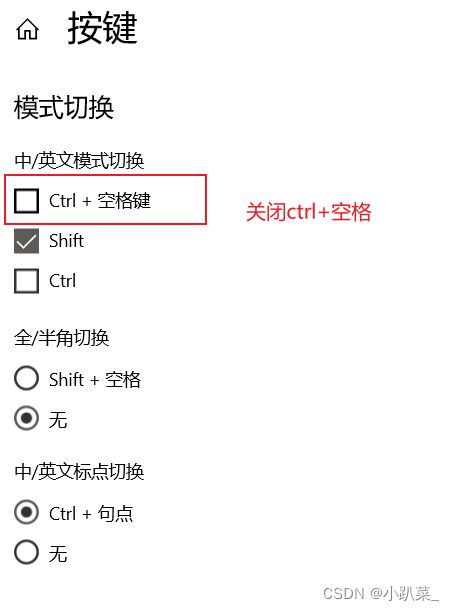
这样应该大部分都可成功了。如果你还没成功,那你可能按照了其他软件的快捷键什么的占用了。
3.3 对xml与json文件的树状显示
xml文件:
第一种:游览器直接打开
第二种:安装notepad++
在插件管理搜索xml安装xml tools
点击就可以显示了
json文件:
这里有个很好用的网址:打开就可以用了
https://www.5axxw.com/tools/v2/fjson.html
等待收集更多的问题