单阶段目标检测模型YoLo系列(一):YoLoV3详解及代码实现
目录
1、YoLoV3网络结构
1.1 Backbone:Darknet-53
1.2 构建特征金字塔
1.3 YoLo Head
2、yolov3模型预测结果的解码
2.1 先验框
2.2 检测框解码
2.3 置信度解码
2.4 类别解码
3、yolov3模型的训练策略和损失函数
1、YoLoV3网络结构
YoLoV3模型的网络结构大致如下图所示,其主要由三部分组成:Backbone网络提取图像特征、构建特征金字塔FPN实现特征融合、使用YoLo Head获取预测结果。

1.1 Backbone:Darknet-53
YoLoV3模型采用Darknet-53作为Backbone网络用来提取图像特征,Darknet-53网络中堆叠了多个残差模块,相邻残差模块之间间隔了一个kernel-size=3×3,stride=2的卷积层,其作用主要是downsample。Darknet-53网络最初应用在图像分类任务上,它一共53层结构,包括52个卷积层用来提取图像特征和尾部的1个全连接层用来图像分类,如下图所示,下图以输入图像常用尺寸416×416为例进行介绍的(输入图像尺寸只要是32的倍数就行,因为Darknet-53网络中有5次下采样操作,每次下采样后特征图的尺寸都降为原来的1/2)。另外,需要注意的是yolov3中的Backbone网络只采用了Darknet-53前面的52个卷积层用来提取图像特征。

Darknet-53网络的残差模块输入特征图和输出特征图中间经过卷积核大小为1×1和3×3大小的两次卷积并且采用了Residual残差连接方式,其与Resnet网络残差连接方式基本相同,就是将残差模块的输入特征图和经过两次卷积的输入特征图进行Add操作,如下图所示。

另外,Darknet-53网络中的Convolutional模块=conv2d+bn+leaky relu,如下图所示。

Darknet-53网络代码实现如下:
import math
from collections import OrderedDict
import torch.nn as nn
# ---------------------------------------------------------------------#
# 残差结构
# 利用一个1x1卷积下降通道数,然后利用一个3x3卷积提取特征并且上升通道数
# 最后接上一个残差边
# ---------------------------------------------------------------------#
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out
class DarkNet(nn.Module):
def __init__(self, layers):
super(DarkNet, self).__init__()
self.inplanes = 32
# 416,416,3 -> 416,416,32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu1 = nn.LeakyReLU(0.1)
# 416,416,32 -> 208,208,64
self.layer1 = self._make_layer([32, 64], layers[0])
# 208,208,64 -> 104,104,128
self.layer2 = self._make_layer([64, 128], layers[1])
# 104,104,128 -> 52,52,256
self.layer3 = self._make_layer([128, 256], layers[2])
# 52,52,256 -> 26,26,512
self.layer4 = self._make_layer([256, 512], layers[3])
# 26,26,512 -> 13,13,1024
self.layer5 = self._make_layer([512, 1024], layers[4])
self.layers_out_filters = [64, 128, 256, 512, 1024]
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
# ---------------------------------------------------------------------#
# 在每一个layer里面,首先利用一个步长为2的3x3卷积进行下采样
# 然后进行残差结构的堆叠
# ---------------------------------------------------------------------#
def _make_layer(self, planes, blocks):
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3, stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))
# 加入残差结构
self.inplanes = planes[1]
for i in range(0, blocks):
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
out3 = self.layer3(x)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
return out3, out4, out5
def darknet53():
model = DarkNet([1, 2, 8, 8, 4])
return model
1.2 构建特征金字塔
在讲解yolov3构建特征金字塔之前,先来简单介绍一下特征金字塔结构。特征金字塔结构是《Feature Pyramid Networks for Object Detection》这篇论文首次提出的,主要解决的问题是目标检测在处理多尺度变化问题时的不足,现在很多网络都只使用单个深层特征来进行目标检测(比如说Faster R-CNN利用下采样四倍的卷积层进行后续的物体的分类和bounding box的回归),但是这样做有一个明显的缺陷,即小物体本身具有的像素信息较少,在下采样的过程中极易被丢失,为了处理这种物体大小差异十分明显的检测问题,经典的方法是利用图像金字塔的方式进行多尺度变化增强,但这样会带来极大的计算量。所以这篇论文提出了特征金字塔的网络结构,如下图所示,能在增加极小计算量的情况下,处理好物体检测中的多尺度变化问题。
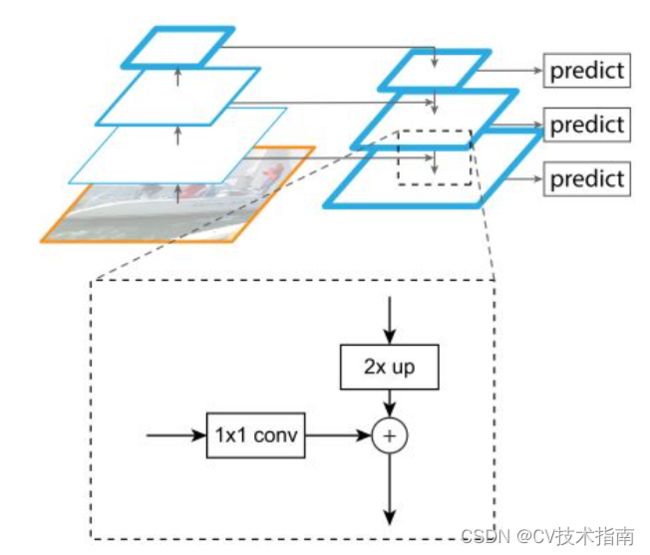
但需要注意的是,在这篇论文中低分辨率的特征图在上采样之后和高分辨率的特征图进行特征融合时是采用add方式(即特征图上对应特征值相加,首次在ResNet中出现),其实还有另外一种更常用的特征融合方式就是concat方式(即对通道数进行拼接,首次在DenseNet中出现),yolov3中构建的特征金字塔就是采用concat方式实现特征融合。
Darknet-53提取输入图像的特征之后,从提取的众多特征层中选取三个特征层用来构建特征金字塔,实现不同等级特征的有效融合,这三个特征层位于Darknet-53网络的不同位置,它们的shape分别为(52,52,256)、(26,26,512)、(13,13,1024),如下图所示。

采用这三个有效特征层构建特征金字塔FPN的过程如下:
①对13×13×1024的特征层进行5次卷积操作之后得到第一个加强特征层13×13×512,然后将这个加强特征层进行上采样UmSampling2d后与26x26x512特征层进行通道数拼接,从而实现特征融合,融合后得到的新特征层的shape为(26,26,768);
②对shape为(26,26,768)的新特征层进行5次卷积操作之后得到第二个加强特征层26×26×256,然后将这个加强特征层进行上采样UmSampling2d后与52x52x512特征层进行通道数拼接,从而实现特征融合,融合后得到的新特征层的shape为(52,52,384);
③对shape为(52,52,384)的新特征层进行5次卷积操作之后得到第三个加强特征层52×52×128。
注意:5次卷积操作的顺序都是1×1,3×3,1×1,3×3,1×1,其中1×1卷积主要用来降通道数,3×3卷积主要用来进一步提取图像特征,并且增加通道数。
1.3 YoLo Head
上面通过构建特征金字塔,我们获得了3个加强特征层,这三个加强特征层的shape分别为(13,13,512)、(26,26,256)、(52,52,128),然后我们把这3个加强特征层分别传入Yolo Head中获得模型预测结果。Yolo Head本质上是一次3x3卷积加上一次1x1卷积,以VOC数据集(20类目标)为例,这3个加强特征层输入到YoLo Head中首先经过3×3卷积分别获得(13,13,1024)、(26,26,512)、(52,52,256)的特征图,然后经过1×1卷积获得3个shape为(13,13,75)、(26,26,75)、(52,52,75)的输出特征图,其中75与数据集中目标类别总数有关,75=3×(20+1+4),3代表输出特征图上的每个特征点上存在3个预测框,20代表数据集包含20类物体,1代表预测框中是否包含物体,4代表预测框的调整参数,即预测框的中心点坐标参数x_offset、y_offset以及预测框的高h和宽w。
YoLoV3网络结构的完整代码实现如下:
from collections import OrderedDict
import torch
import torch.nn as nn
from nets.darknet import darknet53
def conv2d(filter_in, filter_out, kernel_size):
pad = (kernel_size - 1) // 2 if kernel_size else 0
return nn.Sequential(OrderedDict([
("conv", nn.Conv2d(filter_in, filter_out, kernel_size=kernel_size, stride=1, padding=pad, bias=False)),
("bn", nn.BatchNorm2d(filter_out)),
("relu", nn.LeakyReLU(0.1)),
]))
# ------------------------------------------------------------------------#
# make_last_layers里面一共有七个卷积,前五个用于提取特征。
# 后两个用于获得yolo网络的预测结果
# ------------------------------------------------------------------------#
def make_last_layers(filters_list, in_filters, out_filter):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
nn.Conv2d(filters_list[1], out_filter, kernel_size=1, stride=1, padding=0, bias=True)
)
return m
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, pretrained=False):
super(YoloBody, self).__init__()
# ---------------------------------------------------#
# 生成darknet53的主干模型
# 获得三个有效特征层,他们的shape分别是:
# 52,52,256
# 26,26,512
# 13,13,1024
# ---------------------------------------------------#
self.backbone = darknet53()
if pretrained:
self.backbone.load_state_dict(torch.load("model_data/darknet53_backbone_weights.pth"))
# ---------------------------------------------------#
# out_filters : [64, 128, 256, 512, 1024]
# ---------------------------------------------------#
out_filters = self.backbone.layers_out_filters
# ------------------------------------------------------------------------#
# 计算yolo_head的输出通道数,对于voc数据集而言
# final_out_filter0 = final_out_filter1 = final_out_filter2 = 75
# ------------------------------------------------------------------------#
self.last_layer0 = make_last_layers([512, 1024], out_filters[-1], len(anchors_mask[0]) * (num_classes + 5))
self.last_layer1_conv = conv2d(512, 256, 1)
self.last_layer1_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.last_layer1 = make_last_layers([256, 512], out_filters[-2] + 256, len(anchors_mask[1]) * (num_classes + 5))
self.last_layer2_conv = conv2d(256, 128, 1)
self.last_layer2_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.last_layer2 = make_last_layers([128, 256], out_filters[-3] + 128, len(anchors_mask[2]) * (num_classes + 5))
def forward(self, x):
# ---------------------------------------------------#
# 获得三个有效特征层,他们的shape分别是:
# 52,52,256;26,26,512;13,13,1024
# ---------------------------------------------------#
x2, x1, x0 = self.backbone(x)
# ---------------------------------------------------#
# 第一个特征层
# out0 = (batch_size,255,13,13)
# ---------------------------------------------------#
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
out0_branch = self.last_layer0[:5](x0)
out0 = self.last_layer0[5:](out0_branch)
# 13,13,512 -> 13,13,256 -> 26,26,256
x1_in = self.last_layer1_conv(out0_branch)
x1_in = self.last_layer1_upsample(x1_in)
# 26,26,256 + 26,26,512 -> 26,26,768
x1_in = torch.cat([x1_in, x1], 1)
# ---------------------------------------------------#
# 第二个特征层
# out1 = (batch_size,255,26,26)
# ---------------------------------------------------#
# 26,26,768 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
out1_branch = self.last_layer1[:5](x1_in)
out1 = self.last_layer1[5:](out1_branch)
# 26,26,256 -> 26,26,128 -> 52,52,128
x2_in = self.last_layer2_conv(out1_branch)
x2_in = self.last_layer2_upsample(x2_in)
# 52,52,128 + 52,52,256 -> 52,52,384
x2_in = torch.cat([x2_in, x2], 1)
# ---------------------------------------------------#
# 第一个特征层
# out3 = (batch_size,255,52,52)
# ---------------------------------------------------#
# 52,52,384 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
out2 = self.last_layer2(x2_in)
return out0, out1, out2
2、yolov3模型预测结果的解码
假设VOC数据集(一共有20类目标)中图像尺寸为416×416×3,将其输入到yolov3网络中,得到的3种不同尺度的输出特征图分别表示3种不同的预测结果,它们的shape分别为13 × 13 × 75、26 × 26 × 75、52 × 52 × 75,小尺度的特征图预测大目标,大尺度的特征图预测小目标。在这里我们简单了解一下每种预测结果分别对输入图像进行了怎样的转化,以尺寸为13 × 13 × 75的输出特征图为例,它相当于将原始输入图像划分成13×13个网格,也就是说原始输入图像上每32×32个像素点经过yolov3网络映射到输出特征图上就成了1个特征点(因为13 × 13的输出特征图相当于输入图像下采样了32倍)。然后每种输出特征图上的每个特征点都存在3种不同宽高比的先验框,这些先验框的h和w是网络训练前根据以往经验预先设定好的,后续会通过网络训练对先验框进行参数调整,yolov3网络的预测结果包括:检测框包含物体的置信度,检测框的调整参数x,y,w,h以及这个物体所属种类的置信度,3×(1+4+20)=75,这就是3种输出特征图的通道数都为75的原因。下面详细描述怎么将检测信息解码出来。
2.1 先验框
先验框一共有9种尺寸,分别为(10×13),(16×30),(33×23),(30×61),(62×45),(59× 119), (116 × 90), (156 × 198),(373 × 326),顺序为w × h,其中尺度为13×13的输出特征图对应(116,90),(156,198),(373,326)这3种宽高比的先验框,尺度为26×26的输出特征图对应(30×61),(62×45),(59× 119)这3种宽高比的先验框,尺度为52×52的输出特征图对应(10×13),(16×30),(33×23)这3种宽高比的先验框。需要注意的是:这9种尺寸的先验框是相对于输入图像而言的,而代码实现时往往是在输出特征图上进行操作,所以需要注意转化一下;另外,先验框只与检测框的w、h有关,与x、y无关。
2.2 检测框解码
有了先验框与输出特征图,就可以通过下面公式解码检测框:
![]()
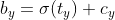
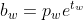
![]()
其中,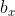 ,
,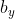 ,
, ,
, 代表检测框解码之后中心点坐标,宽,高的4个参数,
代表检测框解码之后中心点坐标,宽,高的4个参数, ,
,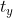 ,
, ,
, 代表yolov3模型输出特征图(预测结果)的其中4个参数,
代表yolov3模型输出特征图(预测结果)的其中4个参数, ,
, 代表矩形框左上角格点的坐标(实际代码实现中就是预先以矩形框左上角格点作为先验框的中心点的,也就是输出特征图中的特征点),
代表矩形框左上角格点的坐标(实际代码实现中就是预先以矩形框左上角格点作为先验框的中心点的,也就是输出特征图中的特征点),![]() ,
,![]() 代表检测框中心点相对于矩形框左上角格点坐标的偏移量, σ 是sigmoid激活函数,
代表检测框中心点相对于矩形框左上角格点坐标的偏移量, σ 是sigmoid激活函数, ,
,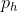 代表先验框的宽高,如下图所示,虚线代表先验框,蓝色代表检测框,红色就是上面提到的矩形框,检测框中心点调整范围约束在矩形框范围内。
代表先验框的宽高,如下图所示,虚线代表先验框,蓝色代表检测框,红色就是上面提到的矩形框,检测框中心点调整范围约束在矩形框范围内。

为了让大家更加清楚的理解检测框解码的过程,可以继续参考下图,以13×13的输出特征图为例,下图的蓝点就相当于输出特征图的特征点,下图中左边的图是以标记特征点为中心点对应的3个先验框,下图中右边的图是根据yolov3预测结果通过上面四个公式得到的调整之后的检测框,先验框中心点的位置,宽高都进行了调整。

2.3 置信度解码
物体的检测置信度在Yolo设计中非常重要,关系到算法的查准率与召回率。置信度在输出25维中占固定一位,由sigmoid函数解码即可,解码之后数值区间在[0,1]中,代表检测框中有物体的概率。
2.4 类别解码
VOC数据集有20个类别,所以类别数在25维输出中占了20维,每一维代表一个类别的置信度,使用sigmoid激活函数替代了Yolov2中的softmax,取消了类别之间的互斥,可以使网络更加灵活。3种不同尺度的输出特征图一共可以解码出 13 × 13 × 3 + 26 × 26 × 3 + 52 × 52 × 3 = 10647 个box以及相应的类别、置信度,这10647个box在训练和推理时,使用方法不一样:
①训练时10647个box全部送入打标签函数,进行后一步的标签以及损失函数的计算。
②推理时,选取一个置信度阈值,过滤掉低阈值box,再经过nms(非极大值抑制),就可以输出整个最终的预测结果了。
3、yolov3模型的训练策略和损失函数
神经网络模型训练计算损失时,实际上是预测结果和真实标签之间的对比,大部分可以直接求MSE,MAE,交叉熵等,而yolov3模型的训练策略相对复杂一点,它需要经过以下几个步骤:
①对训练时产生的10647个box打标签,box一共有正例、负例以及忽略样例3种标签:
正例:任取一个Ground Truth,与10647个box全部计算IOU,IOU最大的预测框即为正例(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例)。并且一个预测框,只能分配给一个Ground Truth。例如第一个Ground Truth已经匹配了一个正例检测框,那么下一个Ground Truth就在余下的10647个box中寻找IOU最大的检测框作为正例,Ground Truth的先后顺序可忽略。正例产生置信度损失、检测框损失、类别损失。预测框为对应的Ground Truth box标签;类别标签对应类别为1,其余为0;置信度标签为1。
负例:既不是正例,同时与全部Ground Truth的IOU又都小于阈值的,为负例。负例只产生置信度损失,置信度标签为0。
忽略样例:正例除外,与任意一个ground truth的IOU大于阈值的,为忽略样例。忽略样例不产生任何loss。之所以定义了忽略样例,是因为由于Yolov3使用了多尺度特征图,不同尺度的特征图之间会有重合检测部分,比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想。
②计算损失。检测框x,y,w,h的损失,使用MSE作为损失函数,也可以使用smooth L1 loss(出自Faster R-CNN)作为损失函数,smooth L1可以使训练更加平滑,在后续发表的论文中,也有使用GIOU损失来进行网络训练的;置信度、类别标签由于是0,1二分类,所以使用交叉熵作为损失函数。