机器学习-----sklearn之随机森林
随机森林是一种集成算法。
sklearn中的集成算法模块:ensemble
随机森林分类器
class sklearn.ensemble.RandomForestClassifier ( n_estimators=’10’ , criterion=’gini’ , max_depth=None , min_samples_split=2 , min_samples_leaf=1 , min_weight_fraction_leaf=0.0 , max_features=’auto’ , max_leaf_nodes=None , min_impurity_decrease=0.0 , min_impurity_split=None , bootstrap=True , oob_score=False , n_jobs=None , random_state=None , verbose=0 , warm_start=False , class_weight=None )
1 . 随机森林分类器
基本代码:
from sklearn.ensemble import RandomForestClassifier重要属性:
1.1 n_estimators
基评估器的数量。值越大,模型的效果往往越好。但随着n_estimators增大,需要更大的计算量,同时当该值增大到某个值,会达到决策边界。默认为100。
***为什么随机森林的效果一定好于单一的决策树?
随机森林的本质是一种装袋集成算法(bagging),装袋集成算法是对基评估器的预测结果进行平均或用多数表决原则来决定集成评估器的结果。在刚才的红酒例子中,我们建立了25棵树,对任何一个样本而言,平均或多数表决原则下,当且仅当有13棵以上的树判断错误的时候,随机森林才会判断错误。
1.2 random_state
随机森林与决策树中的random_state参数有所区别。
决策树中,random_state决定某一棵树,不同的random_state对应不同的树。
在随机森林中,random_state决定的是一组树,对于一个random_state,建立的一个森林中的每一棵树的random_state是不一样的。
可以通过estimators查看随机森林中树的情况:
rfc.estimators_[0].random_state
for i in range(len(rfc.estimators_)):
print(rfc.estimators_[i].random_state)1.3 boostrap & obb_score
是随机森林增加随机性的一种方式。
装袋法是通过有放回的随机抽样方法形成不同的训练数据,bootstrap是用来控制抽样方法的参数。
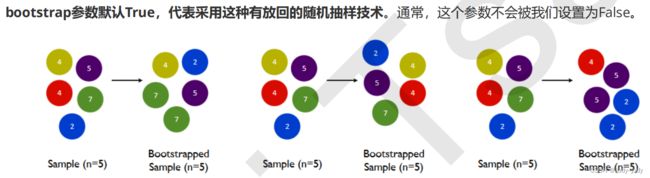
由于这种有放回抽样的方法,数据中有一部分实际上没有被用于训练,一般来说,自助集中包含63%的原始数据。
每个样本被抽中的概率:
当n足够大时,概率趋向0.632,因此约37%的训练数据被浪费掉,被称为袋外数据(out of bag data,简称oob)。
#无需划分训练集和测试集
rfc = RandomForestClassifier(n_estimators=25,oob_score=True)
rfc = rfc.fit(wine.data,wine.target)
#重要属性oob_score_
rfc.oob_score_#####需要注意:
随机森林的效果比单一决策树好的条件,除了基分类器各不相同之外,还需要基分类器的误差率小于50%,即准确率大于50%时,集成的效果更好。当误差率大于50%时,装袋法就失效了。因此在使用随机森林之前,一定要检查用来组成随即森林的分类树们是否都至少有50%的预测准确率。
2. 随机森林回归器
与分类器的主要不同点在于Criterion不一样。
其他参数基本一致。
要注意在不指定评判标准的情况下,回归树的score接口返回的是 ,在进行交叉验证时可以通过指定scoring属性指定打分指标。
,在进行交叉验证时可以通过指定scoring属性指定打分指标。
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor
boston = load_boston()
regressor = RandomForestRegressor(n_estimators=100,random_state=0)
cross_val_score(regressor, boston.data, boston.target, cv=10
,scoring = "neg_mean_squared_error")
想要查看打分指标:
sorted(sklearn.metrics.SCORERS.keys())
例:用随机森林回归填补缺失值
'''
-----用0填补、平均值填补和随机森林回归填补的方法对波士顿数据集进行填补-----
'''
##导入需要的包和数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
from sklearn.impute import SimpleImputer
##数据处理部分
data_full = load_boston() ##无缺损数据集,包括特征和标签
x_full = data_full.data ##无缺特征
y_full = data_full.target ##无缺标签
#添加缺失值
rng = np.random.RandomState(0) ##设置随机数
n_samples = x_full.shape[0]
n_features = x_full.shape[1]
missing_rate = 0.5 ##缺损率
n_missing = int(np.floor(n_samples*n_features*missing_rate)) ##缺失特征的个数
missing_samples = rng.randint(0,n_samples,n_missing)
missing_features = rng.randint(0,n_features,n_missing) ##随机指定缺失值的位置
x_missing = x_full.copy()
x_missing = pd.DataFrame(x_missing)
x_missing.iloc[missing_samples,missing_features] = np.nan ##选中的特征赋值为nan,得到缺失特征矩阵
##缺失值的填充
# 0填充
imputer_0 = SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0)
x_missing_0 = imputer_0.fit_transform(x_missing)
# 均值填充
imputer_mean = SimpleImputer(missing_values=np.nan,strategy='mean')
x_missing_mean = imputer_mean.fit_transform(x_missing)
# 随机森林回归填充
#首先要确定填充顺序
#按照缺失值的数量从少到多填
'''基本思想是把需要填补的数据特征当作新的标签,把原标签以及其他的特征组合作为新特征
在填补时需要注意,由于是将需要填补的数据作为标签,通过模型训练的方法对未知的标签进行训练和预测
在确定填补的顺序时,应该先填补缺失值少的特征,因为这样在训练时的有标签数据更多,更能得到有效的结果
'''
x_missing_rf = x_missing.copy()
order_list = np.argsort(x_missing_rf.isnull().sum(axis=0)).values ##对每个特征中的缺失值进行计数,并得到索引的排序
##遍历循环
for i in order_list:
##首先要构建新特征矩阵和新标签
df = x_missing_rf
fillc = df.iloc[:,i] ##第i个特征做为新标签
df = pd.concat([df.iloc[:,df.columns != i],pd.DataFrame(y_missing)],axis=1) ##其余特征和原标签组合为新特征
##在新特征矩阵中,对缺失值进行填0
imp_0 = SimpleImputer(missing_values=np.nan, strategy="constant",fill_value=0)
df_0 = imp_0.fit_transform(df)
#找出我们的训练集和测试集 要点是看新特征是否为nan
y_train = fillc[fillc.notnull()]
y_test = fillc[fillc.isnull()]
x_train = df_0[y_train.index,:]
x_test = df_0[y_test.index,:]
##随机森林填补
rfc = RandomForestRegressor(n_estimators=100)
rfc = rfc.fit(x_train,y_train)
y_predict = rfc.predict(x_test)
##将填补好的数据返回原始特征矩阵
x_missing_reg.iloc[x_missing_reg.iloc[:,i].isnull(),i] = y_predict
##三种填充效果可视化比较
X = [x_full,x_missing_mean,x_missing_0,x_missing_reg]
mse = []
std = []
for x in X:
estimator = RandomForestRegressor(random_state=0, n_estimators=100)
scores=cross_val_score(estimator,x,y_full,scoring='neg_mean_squared_error'
,cv=5).mean()
mse.append(scores * -1)
x_labels = ['Full data','Zero Imputation','Mean Imputation','Regressor Imputation']
colors = ['r', 'g', 'b', 'orange']
plt.figure(figsize=(12, 6))
ax = plt.subplot(111)
for i in np.arange(len(mse)):
ax.barh(i, mse[i],color=colors[i], alpha=0.6, align='center')
ax.set_title('Imputation Techniques with Boston Data')
ax.set_xlim(left=np.min(mse) * 0.9,right=np.max(mse) * 1.1)
ax.set_yticks(np.arange(len(mse)))
ax.set_xlabel('MSE')
ax.set_yticklabels(x_labels)
plt.show()