语义分割:使用BiSeNet(Pytorch版本)训练自己的数据集
目录
- 下载BiSeNet源码
- 数据集准备
- 训练
- 模型推理测试
下载BiSeNet源码
请点击此位置进行源码下载,或者采用以下命令下载。
git clone https://github.com/CoinCheung/BiSeNet.git
需要注意的是官方使用的环境是Pytorch1.6.0 + cuda 10.2 + cudnn 7,并且采用了多卡分布式训练。为了方便在自己电脑上训练,我将采用自己的数据处理脚本和训练脚本进行单卡训练,我的显卡是GTX1650,显存容量为4G。
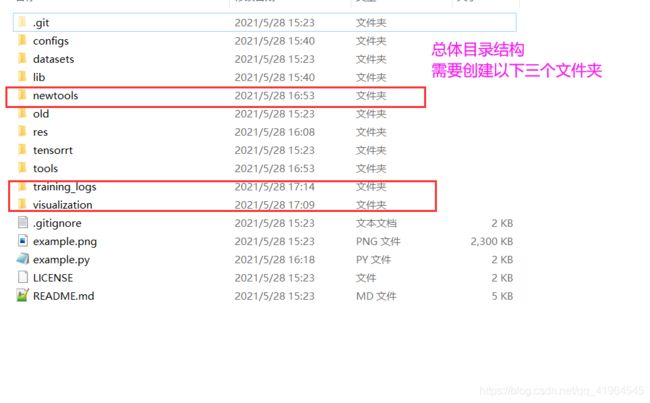
项目克隆下来以后,目录结构为以下,需要新建三个文件下
newtools-----------------------存放新增的脚本
training_logs------------------存放后续的训练模型与训练过程记录
visualization-------------------存放可视化代码
数据集准备
数据集使用UAVID无人机遥感图像语义分割数据集,有关UAVID数据集的介绍与使用见之前的博客,这里直接贴出数据集处理的代码dataset.py,并新建文件夹newtools,存放dataset.py。
'''
dataset.py
'''
import torch
import torch.utils.data
import numpy as np
import cv2
import os
train_dirs = ["seq1/", "seq2/", "seq3/", "seq4/", "seq5/",
"seq6/", "seq7/", "seq8/", "seq9/", "seq10/",
"seq11/", "seq12/", "seq13/", "seq14/", "seq15/",
"seq31/", "seq32/", "seq33/", "seq34/", "seq35/"]
val_dirs = ["seq16/", "seq17/", "seq18/","seq19/",
"seq20/", "seq36/", "seq37/"]
test_dirs = ["seq21/", "seq22/", "seq23/", "seq24/", "seq25/",
"seq26/", "seq27/", "seq28/", "seq29/", "seq30/",
"seq38/", "seq39/", "seq40/", "seq41/", "seq42/" ]
class DatasetTrain(torch.utils.data.Dataset):
def __init__(self, uavid_data_path, uavid_meta_path):
self.img_dir = uavid_data_path + "/train/"
self.label_dir = uavid_meta_path + "/labelimg/train/"
self.img_h = 2160
self.img_w = 3840
self.new_img_h = 512
self.new_img_w = 1024
self.examples = []
for train_dir in train_dirs:
train_img_dir_path = self.img_dir + train_dir + "Images/"
label_img__dir_path = self.label_dir + train_dir
file_names = os.listdir(train_img_dir_path)
for file_name in file_names:
img_id = file_name.split(".png")[0]
img_path = train_img_dir_path + file_name
label_img_path = label_img__dir_path + "TrainId/" + img_id + ".png"
example = {}
example["img_path"] = img_path
example["label_img_path"] = label_img_path
example["img_id"] = img_id
self.examples.append(example)
self.num_examples = len(self.examples)
def __getitem__(self, index):
example = self.examples[index]
img_path = example["img_path"]
img = cv2.imread(img_path, -1) # (shape: (512, 1024, 3))
# resize img without interpolation (want the image to still match
# label_img, which we resize below):
img = cv2.resize(img, (self.new_img_w, self.new_img_h),
interpolation=cv2.INTER_NEAREST) # (shape: (1536, 1536, 3))
label_img_path = example["label_img_path"]
label_img = cv2.imread(label_img_path, cv2.IMREAD_GRAYSCALE) # (shape: (2160, 3840))
# resize label_img without interpolation (want the resulting image to
# still only contain pixel values corresponding to an object class):
label_img = cv2.resize(label_img, (self.new_img_w, self.new_img_h),
interpolation=cv2.INTER_NEAREST) # (shape: (1536, 1536))
# flip the img and the label with 0.5 probability:
flip = np.random.randint(low=0, high=2)
if flip == 1:
img = cv2.flip(img, 1)
label_img = cv2.flip(label_img, 1)
########################################################################
# randomly scale the img and the label:
########################################################################
# scale = np.random.uniform(low=0.7, high=2.0)
# new_img_h = int(scale*self.new_img_h)
# new_img_w = int(scale*self.new_img_w)
# resize img without interpolation (want the image to still match
# label_img, which we resize below):
# img = cv2.resize(img, (new_img_w, new_img_h),
# interpolation=cv2.INTER_NEAREST) # (shape: (new_img_h, new_img_w, 3))
# resize label_img without interpolation (want the resulting image to
# still only contain pixel values corresponding to an object class):
# label_img = cv2.resize(label_img, (new_img_w, new_img_h),
# interpolation=cv2.INTER_NEAREST) # (shape: (new_img_h, new_img_w))
########################################################################
# # # # # # # # debug visualization START
# print (scale)
# print (new_img_h)
# print (new_img_w)
#
# cv2.imshow("test", img)
# cv2.waitKey(0)
#
# cv2.imshow("test", label_img)
# cv2.waitKey(0)
# # # # # # # # debug visualization END
########################################################################
# select a 768x768 random crop from the img and label:
########################################################################
# start_x = np.random.randint(low=0, high=(new_img_w - 256))
# end_x = start_x + 256
# start_y = np.random.randint(low=0, high=(new_img_h - 256))
# end_y = start_y + 256
# img = img[start_y:end_y, start_x:end_x] # (shape: (768, 768, 3))
# label_img = label_img[start_y:end_y, start_x:end_x] # (shape: (768, 768))
########################################################################
# # # # # # # # debug visualization START
# print (img.shape)
# print (label_img.shape)
#
# cv2.imshow("test", img)
# cv2.waitKey(0)
#
# cv2.imshow("test", label_img)
# cv2.waitKey(0)
# # # # # # # # debug visualization END
# normalize the img (with the mean and std for the pretrained ResNet):
img = img/255.0
img = img - np.array([0.485, 0.456, 0.406])
img = img/np.array([0.229, 0.224, 0.225]) # (shape: (768, 768, 3))
img = np.transpose(img, (2, 0, 1)) # (shape: (3, 768, 768))
img = img.astype(np.float32)
# convert numpy -> torch:
img = torch.from_numpy(img) # (shape: (3, 768, 768))
label_img = torch.from_numpy(label_img) # (shape: (768, 768))
return (img, label_img)
def __len__(self):
return self.num_examples
class DatasetVal(torch.utils.data.Dataset):
def __init__(self, uavid_data_path, uavid_meta_path):
self.img_dir = uavid_data_path + "/valid/"
self.label_dir = uavid_meta_path + "/labelimg/valid/"
self.img_h = 2160
self.img_w = 3840
self.new_img_h = 512
self.new_img_w = 1024
self.examples = []
for val_dir in val_dirs:
val_img_dir_path = self.img_dir + val_dir + "Images/"
label_img__dir_path = self.label_dir + val_dir
file_names = os.listdir(val_img_dir_path)
for file_name in file_names:
img_id = file_name.split(".png")[0]
img_path = val_img_dir_path + file_name
label_img_path = label_img__dir_path + "TrainId/" + img_id + ".png"
# label_img = cv2.imread(label_img_path, -1) # (shape: (1024, 2048))
example = {}
example["img_path"] = img_path
example["label_img_path"] = label_img_path
example["img_id"] = img_id
self.examples.append(example)
self.num_examples = len(self.examples)
def __getitem__(self, index):
example = self.examples[index]
img_id = example["img_id"]
img_path = example["img_path"]
img = cv2.imread(img_path, -1) # (shape: (2160, 3840, 3))
# resize img without interpolation (want the image to still match
# label_img, which we resize below):
img = cv2.resize(img, (self.new_img_w, self.new_img_h),
interpolation=cv2.INTER_NEAREST) # (shape: (768, 768, 3))
label_img_path = example["label_img_path"]
label_img = cv2.imread(label_img_path, cv2.IMREAD_GRAYSCALE) # (shape: (2160, 3840))
# resize label_img without interpolation (want the resulting image to
# still only contain pixel values corresponding to an object class):
label_img = cv2.resize(label_img, (self.new_img_w, self.new_img_h),
interpolation=cv2.INTER_NEAREST) # (shape: (768, 768))
# # # # # # # # debug visualization START
# cv2.imshow("test", img)
# cv2.waitKey(0)
#
# cv2.imshow("test", label_img)
# cv2.waitKey(0)
# # # # # # # # debug visualization END
# normalize the img (with the mean and std for the pretrained ResNet):
img = img/255.0
img = img - np.array([0.485, 0.456, 0.406])
img = img/np.array([0.229, 0.224, 0.225]) # (shape: (768, 768, 3))
img = np.transpose(img, (2, 0, 1)) # (shape: (3, 768, 768))
img = img.astype(np.float32)
# convert numpy -> torch:
img = torch.from_numpy(img) # (shape: (3, 768, 768))
label_img = torch.from_numpy(label_img) # (shape: (768, 768))
return (img, label_img, img_id)
def __len__(self):
return self.num_examples
class DatasetTest(torch.utils.data.Dataset):
def __init__(self, uavid_data_path, uavid_meta_path):
self.img_dir = uavid_data_path + "/test/"
self.img_h = 2160
self.img_w = 3840
self.new_img_h = 512
self.new_img_w = 1024
self.examples = []
for test_dir in test_dirs:
test_img_dir_path = self.img_dir + test_dir + "Images/"
file_names = os.listdir(test_img_dir_path)
for file_name in file_names:
img_id = file_name.split(".png")[0]
img_path = test_img_dir_path + file_name
example = {}
example["img_path"] = img_path
example["img_id"] = img_id
self.examples.append(example)
self.num_examples = len(self.examples)
def __getitem__(self, index):
example = self.examples[index]
img_id = example["img_id"]
img_path = example["img_path"]
img = cv2.imread(img_path, -1) # (shape: (2160, 3840, 3))
# resize img without interpolation (want the image to still match
# label_img, which we resize below):
img = cv2.resize(img, (self.new_img_w, self.new_img_h),
interpolation=cv2.INTER_NEAREST) # (shape: (512, 1024, 3))
# # # # # # # # debug visualization START
# cv2.imshow("test", img)
# cv2.waitKey(0)
#
# cv2.imshow("test", label_img)
# cv2.waitKey(0)
# # # # # # # # debug visualization END
# normalize the img (with the mean and std for the pretrained ResNet):
img = img/255.0
img = img - np.array([0.485, 0.456, 0.406])
img = img/np.array([0.229, 0.224, 0.225]) # (shape: (512, 1024, 3))
img = np.transpose(img, (2, 0, 1)) # (shape: (3, 512, 1024))
img = img.astype(np.float32)
# convert numpy -> torch:
img = torch.from_numpy(img) # (shape: (3, 768, 768))
label_img = torch.from_numpy(label_img) # (shape: (768, 768))
return (img,img_id)
def __len__(self):
return self.num_examples
class DatasetSeq(torch.utils.data.Dataset):
def __init__(self, uavid_data_path, uavid_meta_path, sequence):
self.img_dir = uavid_data_path + "/demoVideo/stuttgart_" + sequence + "/"
# self.img_dir = cityscapes_data_path + "/leftImg8bit/" + sequence + "/"
self.img_h = 2160
self.img_w = 3840
self.new_img_h = 512
self.new_img_w = 1024
self.examples = []
file_names = os.listdir(self.img_dir)
for file_name in file_names:
img_id = file_name.split(".png")[0]
img_path = self.img_dir + file_name
example = {}
example["img_path"] = img_path
example["img_id"] = img_id
self.examples.append(example)
self.num_examples = len(self.examples)
def __getitem__(self, index):
example = self.examples[index]
img_id = example["img_id"]
img_path = example["img_path"]
print(img_path)
img = cv2.imread(img_path, -1) # (shape: (1024, 2048, 3))
print(img.shape)
# resize img without interpolation:
img = cv2.resize(img, (self.new_img_w, self.new_img_h),
interpolation=cv2.INTER_NEAREST) # (shape: (512, 1024, 3))
# normalize the img (with the mean and std for the pretrained ResNet):
img = img/255.0
img = img - np.array([0.485, 0.456, 0.406])
img = img/np.array([0.229, 0.224, 0.225]) # (shape: (512, 1024, 3))
img = np.transpose(img, (2, 0, 1)) # (shape: (3, 512, 1024))
img = img.astype(np.float32)
# convert numpy -> torch:
img = torch.from_numpy(img) # (shape: (3, 512, 1024))
return (img, img_id)
def __len__(self):
return self.num_examples
训练
训练过很简单,重要是读取出模型。这里贴出新增的训练脚本train.py。将文件train.py放入newtools文件夹下。
'''
train.py
'''
import sys
sys.path.insert(0, '.')
import os
import os.path as osp
import random
import logging
import time
import argparse
import numpy as np
from tabulate import tabulate
import torch
import torch.nn as nn
import torch.distributed as dist
from torch.utils.data import DataLoader
from newtools.dataset import DatasetTrain,DatasetVal
from lib.models import model_factory
from configs import cfg_factory
from lib.cityscapes_cv2 import get_data_loader
from tools.evaluate import eval_model
from lib.ohem_ce_loss import OhemCELoss
from lib.lr_scheduler import WarmupPolyLrScheduler
from lib.meters import TimeMeter, AvgMeter
from lib.logger import setup_logger, print_log_msg
from tqdm import tqdm, trange
import torch
import torch.utils.data
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pickle
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import cv2
import time
if __name__ == "__main__":
# NOTE! NOTE! change this to not overwrite all log data when you train the model:
# network = DeepLabV3(model_id=1, project_dir="E:/master/master1/RSISS/deeplabv3/deeplabv3").cuda()
# x = Variable(torch.randn(2,3,256,256)).cuda()
# print(x.shape)
# y = network(x)
# print(y.shape)
model_id = "1"
num_epochs = 100
batch_size = 3
learning_rate = 0.0001
def parse_args():
parse = argparse.ArgumentParser()
parse.add_argument('--local_rank', dest='local_rank', type=int, default=-1,)
parse.add_argument('--port', dest='port', type=int, default=44554,)
parse.add_argument('--model', dest='model', type=str, default='bisenetv2',)
parse.add_argument('--finetune-from', type=str, default=None,)
return parse.parse_args()
args = parse_args()
cfg = cfg_factory[args.model]
network = model_factory[cfg.model_type](8)
network.cuda()
network.load_state_dict(torch.load("training_logs/checkpoint/model_1_epoch_12.pth"))
# network.load_state_dict(torch.load("training_logs/model_1/checkpoints/model_1_epoch_9.pth"))
train_dataset = DatasetTrain(uavid_data_path="D:/BaiduNetdiskDownload/uavid/uavid_v1.5_official_release_split/UAVidDataset",
uavid_meta_path="D:/BaiduNetdiskDownload/uavid/uavid_v1.5_official_release_split/UAVidDataset")
val_dataset = DatasetVal(uavid_data_path="D:/BaiduNetdiskDownload/uavid/uavid_v1.5_official_release_split/UAVidDataset",
uavid_meta_path="D:/BaiduNetdiskDownload/uavid/uavid_v1.5_official_release_split/UAVidDataset")
num_train_batches = int(len(train_dataset)/batch_size)
num_val_batches = int(len(val_dataset)/batch_size)
print ("num_train_batches:", num_train_batches)
print ("num_val_batches:", num_val_batches)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=1,drop_last=True)
val_loader = torch.utils.data.DataLoader(dataset=val_dataset,
batch_size=batch_size, shuffle=False,
num_workers=1,drop_last=True)
optimizer = torch.optim.Adam(network.parameters(), lr=learning_rate)
# with open("D:/BaiduNetdiskDownload/cityscapes/class_weights.pkl", "rb") as file: # (needed for python3)
# class_weights = np.array(pickle.load(file))
# class_weights = torch.from_numpy(class_weights)
# class_weights = Variable(class_weights.type(torch.FloatTensor)).cuda()
# loss function
loss_fn = nn.CrossEntropyLoss()
epoch_losses_train = []
epoch_losses_val = []
for epoch in range(num_epochs):
print ("###########################")
print ("######## NEW EPOCH ########")
print ("###########################")
print ("epoch: %d/%d" % (epoch+1, num_epochs))
############################################################################
# train:
############################################################################
network.train() # (set in training mode, this affects BatchNorm and dropout)
batch_losses = []
for step, (imgs, label_imgs) in tqdm(enumerate(train_loader)):
#current_time = time.time()
imgs = Variable(imgs).cuda() # (shape: (batch_size, 3, img_h, img_w))
# print(imgs.shape)
label_imgs = Variable(label_imgs.type(torch.LongTensor)).cuda() # (shape: (batch_size, img_h, img_w))
# print(label_imgs.shape)
outputs,*outputs_aux = network(imgs) # (shape: (batch_size, num_classes, img_h, img_w))
# print(outputs)
# print("shape of label_imgs: ",label_imgs.shape)
# print("shape of outputs: ",outputs.shape)
# compute the loss:
loss = loss_fn(outputs, label_imgs)
loss_value = loss.data.cpu().numpy()
batch_losses.append(loss_value)
# optimization step:
optimizer.zero_grad() # (reset gradients)
loss.backward() # (compute gradients)
optimizer.step() # (perform optimization step)
#print (time.time() - current_time)
epoch_loss = np.mean(batch_losses)
epoch_losses_train.append(epoch_loss)
with open("%s/epoch_losses_train.pkl" % "training_logs", "wb") as file:
pickle.dump(epoch_losses_train, file)
print ("train loss: %g" % epoch_loss)
plt.figure(1)
plt.plot(epoch_losses_train, "k^")
plt.plot(epoch_losses_train, "k")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.title("train loss per epoch")
plt.savefig("%s/epoch_losses_train.png" % "training_logs")
plt.close(1)
print ("####")
############################################################################
# val:
############################################################################
network.eval() # (set in evaluation mode, this affects BatchNorm and dropout)
batch_losses = []
for step, (imgs, label_imgs, img_ids) in tqdm(enumerate(val_loader)):
with torch.no_grad(): # (corresponds to setting volatile=True in all variables, this is done during inference to reduce memory consumption)
imgs = Variable(imgs).cuda() # (shape: (batch_size, 3, img_h, img_w))
label_imgs = Variable(label_imgs.type(torch.LongTensor)).cuda() # (shape: (batch_size, img_h, img_w))
outputs,*outputs_aux = network(imgs) # (shape: (batch_size, num_classes, img_h, img_w))
# compute the loss:
loss = loss_fn(outputs, label_imgs)
loss_value = loss.data.cpu().numpy()
batch_losses.append(loss_value)
epoch_loss = np.mean(batch_losses)
epoch_losses_val.append(epoch_loss)
with open("%s/epoch_losses_val.pkl" % "training_logs", "wb") as file:
pickle.dump(epoch_losses_val, file)
print ("val loss: %g" % epoch_loss)
plt.figure(1)
plt.plot(epoch_losses_val, "k^")
plt.plot(epoch_losses_val, "k")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.title("val loss per epoch")
plt.savefig("%s/epoch_losses_val.png" % "training_logs")
plt.close(1)
# save the model weights to disk:
checkpoint_path = "training_logs/checkpoint" + "/model_" + model_id +"_epoch_" + str(epoch+1) + ".pth"
torch.save(network.state_dict(), checkpoint_path)
在训练之前,还要在文件夹training_logs中补充新建以下文件夹和文件
checkpoint------------------------------存放训练模型
result-------------------------------------存放推理结果

之后便可以运行train.py进行训练了
模型推理测试
新增run_on_seq.py,放置于文件夹visualization下
'''
run_on_seq.py
'''
import sys
sys.path.insert(0, '.')
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import torch
import torch.utils.data
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import torch.nn.functional as F
import argparse
from lib.models import model_factory
from configs import cfg_factory
import numpy as np
import pickle
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import cv2
from newtools.dataset import DatasetSeq
from newtools.utils import label_img_to_color
if __name__ =="__main__":
batch_size = 2
def parse_args():
parse = argparse.ArgumentParser()
parse.add_argument('--local_rank', dest='local_rank', type=int, default=-1,)
parse.add_argument('--port', dest='port', type=int, default=44554,)
parse.add_argument('--model', dest='model', type=str, default='bisenetv2',)
parse.add_argument('--finetune-from', type=str, default=None,)
return parse.parse_args()
args = parse_args()
cfg = cfg_factory[args.model]
network = model_factory[cfg.model_type](8)
network.cuda()
network.load_state_dict(torch.load("training_logs/checkpoint/model_1_epoch_40.pth"))
for sequence in ["0"]:
print (sequence)
val_dataset = DatasetSeq(uavid_data_path="D:/BaiduNetdiskDownload/uavid/uavid_v1.5_official_release_split/UAVidDataset",
uavid_meta_path="D:/BaiduNetdiskDownload/uavid/uavid_v1.5_official_release_split/UAVidDataset",
sequence=sequence)
num_val_batches = int(len(val_dataset)/batch_size)
print ("num_val_batches:", num_val_batches)
val_loader = torch.utils.data.DataLoader(dataset=val_dataset,
batch_size=batch_size, shuffle=False,
num_workers=1)
network.eval() # (set in evaluation mode, this affects BatchNorm and dropout)
unsorted_img_ids = []
for step, (imgs, img_ids) in enumerate(val_loader):
with torch.no_grad(): # (corresponds to setting volatile=True in all variables, this is done during inference to reduce memory consumption)
imgs = Variable(imgs).cuda() # (shape: (batch_size, 3, img_h, img_w))
outputs,*outputs_aux = network(imgs) # (shape: (batch_size, num_classes, img_h, img_w))
####################################################################
# save data for visualization:
####################################################################
outputs = outputs.data.cpu().numpy() # (shape: (batch_size, num_classes, img_h, img_w))
pred_label_imgs = np.argmax(outputs, axis=1) # (shape: (batch_size, img_h, img_w))
pred_label_imgs = pred_label_imgs.astype(np.uint8)
for i in range(pred_label_imgs.shape[0]):
pred_label_img = pred_label_imgs[i] # (shape: (img_h, img_w))
img_id = img_ids[i]
img = imgs[i] # (shape: (3, img_h, img_w))
img = img.data.cpu().numpy()
img = np.transpose(img, (1, 2, 0)) # (shape: (img_h, img_w, 3))
img = img*np.array([0.229, 0.224, 0.225])
img = img + np.array([0.485, 0.456, 0.406])
img = img*255.0
img = img.astype(np.uint8)
pred_label_img_color = label_img_to_color(pred_label_img)
overlayed_img = 0.35*img + 0.65*pred_label_img_color
overlayed_img = overlayed_img.astype(np.uint8)
img_h = overlayed_img.shape[0]
img_w = overlayed_img.shape[1]
cv2.imwrite("training_logs/result" + "/" + img_id + ".png", img)
cv2.imwrite("training_logs/result" + "/" + img_id + "_pred.png", pred_label_img_color)
cv2.imwrite("training_logs/result" + "/" + img_id + "_overlayed.png", overlayed_img)
unsorted_img_ids.append(img_id)
############################################################################
# create visualization video:
############################################################################
out = cv2.VideoWriter("%s/stuttgart_%s_combined.avi" % ("training_logs/result", sequence), cv2.VideoWriter_fourcc(*"MJPG"), 20, (2*img_w, 2*img_h))
sorted_img_ids = sorted(unsorted_img_ids)
for img_id in sorted_img_ids:
img = cv2.imread("training_logs/result" + "/" + img_id + ".png", -1)
pred_img = cv2.imread("training_logs/result" + "/" + img_id + "_pred.png", -1)
overlayed_img = cv2.imread("training_logs/result" + "/" + img_id + "_overlayed.png", -1)
combined_img = np.zeros((2*img_h, 2*img_w, 3), dtype=np.uint8)
combined_img[0:img_h, 0:img_w] = img
combined_img[0:img_h, img_w:(2*img_w)] = pred_img
combined_img[img_h:(2*img_h), (int(img_w/2)):(img_w + int(img_w/2))] = overlayed_img
out.write(combined_img)
out.release()
新建文件utils.py,放置于newtools文件夹下
'''
utils.py
'''
import torch
import torch.nn as nn
import numpy as np
def add_weight_decay(net, l2_value, skip_list=()):
# https://raberrytv.wordpress.com/2017/10/29/pytorch-weight-decay-made-easy/
decay, no_decay = [], []
for name, param in net.named_parameters():
if not param.requires_grad:
continue # frozen weights
if len(param.shape) == 1 or name.endswith(".bias") or name in skip_list:
no_decay.append(param)
else:
decay.append(param)
return [{'params': no_decay, 'weight_decay': 0.0}, {'params': decay, 'weight_decay': l2_value}]
# function for colorizing a label image:
def label_img_to_color(img):
label_to_color = {
# 0: [128, 64,128],
# 1: [244, 35,232],
# 2: [ 70, 70, 70],
# 3: [102,102,156],
# 4: [190,153,153],
# 5: [153,153,153],
# 6: [250,170, 30],
# 7: [220,220, 0],
0: [0, 0, 0],
1: [0, 0, 128],
2: [128, 64, 128],
3: [192, 0, 192],
4: [0, 128, 0],
5: [0, 128, 128],
6: [0, 64, 64],
7: [128, 0, 64],
8: [107,142, 35],
9: [152,251,152],
10: [ 70,130,180],
11: [220, 20, 60],
12: [255, 0, 0],
13: [ 0, 0,142],
14: [ 0, 0, 70],
15: [ 0, 60,100],
16: [ 0, 80,100],
17: [ 0, 0,230],
18: [119, 11, 32],
19: [81, 0, 81]
}
img_height, img_width = img.shape
# print(img.shape)
# img_height, img_width = img.shape[1],img.shape[2]
img_color = np.zeros((img_height, img_width, 3))
for row in range(img_height):
for col in range(img_width):
label = img[row, col]
img_color[row, col] = np.array(label_to_color[label])
return img_color
在UAVID数据集下新增文件夹demoVideo
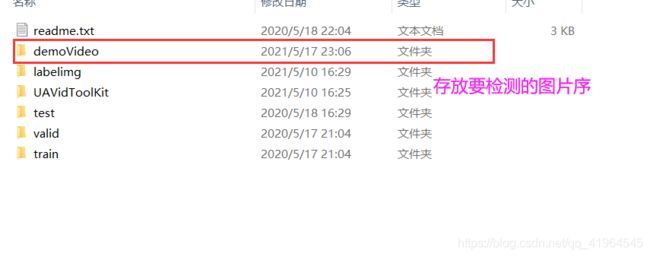
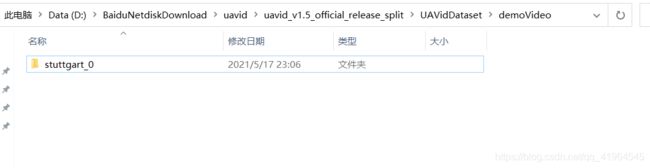
在demoVideo文件夹中新增文件夹stuttgart_0,文件夹stuttgart_0里面存放你要检测的图片。可以参考一下我的路径。

之后便可以运行run_on_seq.py,进行预测了,预测结果保存在BiSeNet\training_logs\result路径下。
修改好的工程代码,我已上传至此处,欢迎下载!
如果你觉得此篇博客对你有所帮助的话,不妨帮我点个赞哦!