1.Pytorch实现LeNet-5
一、LeNet-5模型结构图
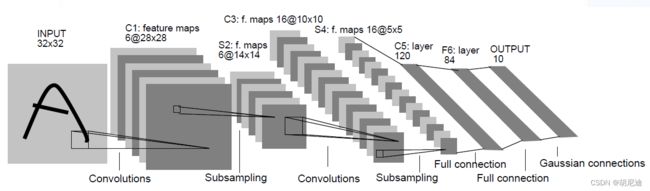
如上图,LeNet-5模型一共有七层,2个卷积层,2个池化层,3个全连接层
网络结构
从左至右,输入图片大小为32x32
第一个卷积层,卷积核个数为6,大小为5x5
第一个池化层,过滤器大小2x2,步长为2
第二个卷积层,卷积核个数为16,大小为5x5
第二个池化层,过滤器大小2x2,步长为2
第一个全连接层,节点个数为128
第二个全连接层,节点个数为84
第三个全连接层,节点个数为10
这里卷积核大小为什么是5x5,下面再讨论。
二、各层在Pytorch中的实现
卷积层
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
| 参数 | 参数类型 | |
|---|---|---|
| in_channels | int | 输入图像通道数 |
| out_channels | int | 卷积产生的通道数 |
| kernel_size | (int or tuple) | 卷积核尺寸,可以设为1个int型数或者一个(int, int)型的元组。例如(2,3)是高2宽3卷积核 |
| stride | (int or tuple, optional) | 卷积步长,默认为1。可以设为1个int型数或者一个(int, int)型的元组。 |
| padding | (int or tuple, optional) | 填充操作,控制padding_mode的数目。 |
| padding_mode | (string, optional) | padding模式,默认为Zero-padding 。 |
| dilation | (int or tuple, optional) | 扩张操作:控制kernel点(卷积核点)的间距,默认值:1。 |
| groups | (int, optional) | group参数的作用是控制分组卷积,默认不分组,为1组。 |
| bias | (bool, optional) | 为真,则在输出中添加一个可学习的偏差。默认:True。 |
详细参数说明可以参考这篇文章链接
池化层
在这里使用到的是最大池化层
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
| 参数 | |
|---|---|
| kernel_size | 表示做最大池化的窗口大小,可以是单个值,也可以是tuple元组 |
| stride | 步长,可以是单个值,也可以是tuple元组 |
| padding | 填充,可以是单个值,也可以是tuple元组 |
| dilation | 控制窗口中元素步幅 |
| return_indices | 布尔类型,返回最大值位置索引 |
| ceil_mode | 布尔类型,为True,用向上取整的方法,计算输出形状;默认是向下取整。 |
详细参数说明可以参考这篇文章 链接
全连接层
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
| 参数 | |
|---|---|
| in_features | 输入张量的大小 |
| out_features | 输出张量的大小 |
| bias | 偏置 |
全连接层的输入输出是二维张量
链接
三、各层输出形状的变化
卷积层

可简单记为:
N = W − F + 2 P S + 1 N=\frac{W-F+2P}{S}+1 N=SW−F+2P+1
其中,N为输出图片大小,W为图片大小,F为卷积核大小,S为步长Stride,P为填充Padding
池化层
池化层的输出形状大小可简单记为与卷积层相同
详细可看这篇文章 链接
下面来说一下为什么上面卷积核大小为5x5
首先,从模型结构图上可以看出,输入图片大小为32x32,而经过第一个卷积层后变为28x28
带入 N = W − F + 2 P S + 1 N=\frac{W-F+2P}{S}+1 N=SW−F+2P+1其中W为32,F未知,P为0,S为1,可算得F为5,即卷积核大小为5x5
后面同理。
四、定义模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 输入通道为3,输出通道为6,卷积核大小5x5
self.pool1 = nn.MaxPool2d(2, 2) # 过滤器大小2x2,步长2
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16*5*5, 120)
# 通过卷积池化后的是四维张量[batch_size,channels,height,width],要想接入全连接层就必须变为二维张量
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input_shape=(batch_size,3,32,32) output_shape=(batch_size,6,28,28)
x = self.pool1(x) # input_shape=(batch_size,6,28,28) output_shape=(batch_size,6,14,14)
x = F.relu(self.conv2(x)) # input_shape=(batch_size,6,14,14) output_shape=(batch_size,16,10,10)
x = self.pool2(x) # input_shape=(batch_size,16,10,10) output_shape=(batch_size,16,5,5)
x = x.view(-1,16*5*5) # input_shape=(batch_size,16,5,5) output_shape=(batch_size,400)
x = F.relu(self.fc1(x)) # input_shape=(batch_size,400) output_shape=(batch_size,120)
x = F.relu(self.fc2(x)) # input_shape=(batch_size,120) output_shape=(batch_size,84)
x = self.fc3(x) # input_shape=(batch_size,84) output_shape=(batch_size,10)
return x
五、完整代码
#导包
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as transforms
import time #用来计算训练用时
#导入数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
trainset = torchvision.datasets.CIFAR10('./data',train=True, download=True, transform = transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10('./data',train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=16, num_workers=0)
#查看trainloader中一个batch
features, targets = next(iter(trainloader)) #从dataloader中取出一个batch
print(features.shape)
print(targets.shape)
#用作训练中的验证
testdata_iter = iter(testloader)
test_image, test_label = testdata_iter.next()
#定义模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(-1,16*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model=LeNet()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
#开始训练
start_time = time.time()
for epoch in range(5):
running_loss = 0.0
for step, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
output = model(inputs)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if step%500 == 499:
with torch.no_grad():
test_outputs = model(test_image)
predict = torch.max(test_outputs,dim=1)[1]
accuracy = torch.eq(predict,test_label).sum().item()/test_label.size(0)
print("[{},{}] train_loss:{} test_acc:{}".format(epoch+1,step+1,running_loss/500,accuracy))
running_loss=0.0
end_time = time.time()
total_time = end_time - start_time
print('total_time:{}'.format(total_time))
六、写在最后
本文算是我在学习深度学习以及Pytorch过程中的记录,有误之处欢迎指正。
同时,有几位up主非常推荐
刘二大人
霹雳吧啦Wz