102个模型、40个数据集,这是你需要了解的机器翻译SOTA论文
机器之心原创
作者:思源
机器翻译,是一条漫漫长路;SOTA 模型,都包含着作者们的深刻见解。
机器翻译一直是非常吸引研究者的「大任务」,如果某些方法被证明在该领域非常有效,那么它很可能可以扩展到其它问题上。例如 Transformer,它出生于机器翻译家族,却广泛应用于各种序列建模任务。
其实机器翻译也走过一条漫漫长路,从早期基于规则与实例的方法,到基于统计的机器翻译,再到目前基于深度神经网络的翻译系统,我们探索了非常多的可能性与思路。有的在刚提出来就受到很多关注,有的则受限于计算资源,直到今天才展现出其强大的能力。
1954 年,人类第一次尝试俄语到英语的自动翻译,这种基于规则的翻译第一次证明机器翻译是可行的。
1954 年的机器翻译报道。
自此之后,机器翻译主要历经了四种模式:
- 基于规则的方法:它首先会将源语言句子解析为语法树,再经过一系列操作转化为目标语言的语法树,最后只需要根据目标语法树生成目标语句就行了。
- 基于实例的方法:它的基本思想即将源语言句子分割为翻译实例中见过的短语片段,并根据相似性检索出与待翻句子片段相似的实例,最后对相似实例的翻译结果执行替代操作,我们就能得到源语短语片段的翻译结果。
- 统计机器翻译:将源语言句子分割为短语片段,利用基于双语语料库学习到的短语翻译知识,将源语言短语转化为合适的目标短语。最后对目标短语片段进行合理的调序,并生成完整的译文。
- 神经机器翻译:利用深度神经网络将原语言句子编码为一个低维向量,然后再直接解码为目标语言句子。
其实早几年我们可能感觉机器翻译还需要大量的人工调整,包括表达方式、专业词汇、句式结构等等。但是随着 GNMT 等神经机器翻译模型的崛起,尤其是 Transformer 展现出强大的能力,体验上,机器翻译效果已经非常惊人了。很多时候只需要调整少数词或表达就能得到满意的结果,甚至在特定领域上能超过人类的专业翻译水平。
那么,从 GNMT 到现在已经三年了,Transformer 的诞生也有两年了。我们可能很想知道,在最近的 NMT 研究中,到底有什么样的 SOTA 模型,翻译效果又有什么样的进步?
在这篇文章中,我们将一探机器翻译 102 个模型、40 个数据集,从中找找 SOTA 模型到底都有什么。
机器之心 SOTA 项目
以前我们找 SOTA 模型,基本上只能靠背景知识与各种 Benchmark,顶多也是 Follow 一些收集顶尖模型的 GitHub 项目。但随着任务细分与新数据集的不断公布,这些只关注主流数据集的 Benchmark 就有些不太够用了。机器之心构建的
SOTA 模型项目
,就旨在解决这个问题,我们可以直接从机器之心官网中找到 SOTA 平台,并搜索想要的顶尖模型。

为了探索当前最佳的 NMT 模型,我们选了几个常见的数据集,并看看在 Transformer 之后,还有哪些激动人心的研究成果。我们发现不同的 NMT 模型都有其侧重的数据集,但最常用的还是 WMT 英法数据集或英德数据集。除此之外,我们也特意找了中英数据集,看看适合翻译中文的模型又是什么样的。
如下是基于 WMT 2014 English-French 数据集的模型,展开后可以看到对应论文与代码。后面我们也会介绍 Transformer Big + BT 模型的核心思路,看看它如何继承了 Transformer 衣钵。

除此之外,当我们选择 WMT French-English 数据集后,我们发现当前的 SOTA 模型 MASS 是微软亚洲研究院刘铁岩等研究者提出来的,它的基本思想承接于 BERT 预训练模型,是另一个非常吸引人的方向。
最后在选择 NIST Chinese-English 数据集时,我们发现早一段时间冯洋等研究者提出的 Oracle Word 能获得当前 SOTA 结果,该研究也获得了 ACL 2019 最佳论文。
总体而言,这三个 SOTA 模型都有着独特的优化方向,其中 Transformer Big + BT 探索用更多的单语数据强化模型效果、MASS 探索预训练语言模型与无监督的翻译方法、Oracle Word 则探索如何能弥补训练与推断间的鸿沟。
Transformer Big + BT:回译是王道
一般而言,训练 NMT 模型需要原文与参考译文这种成对的双语数据。但是,双语数据相对于网络上常见的大量单语数据要有限地多。在这一项研究中,研究者展示了如何通过仅提供我们想要翻译的语言的文本来提升模型的翻译性能,他们表明利用大量的此类数据可以大幅提升模型准确度。
- 论文:Understanding Back-Translation at Scale
- 论文地址:https://arxiv.org/pdf/1808.09381v2.pdf
通过单语数据提升 NMT 模型最高效的方法之一是回译(back-translation)。如果我们的目标是训练一个英语到德语的翻译模型,那么可以首先训练一个从德语到英语的翻译模型,并利用该模型翻译所有的单语德语数据。然后基于原始的英语到德语数据,再加上新生成的数据,我们就能训练一个英语到德语的最终模型。
该论文表示,让模型理解数据的正反翻译过程是非常重要的,通过采样故意不总是选择最好的翻译同样也能得到性能提升。如下动图展示了回译的主要过程,相当于我们用左边较少的数据集生成了右边较大的数据集,并在两种数据集上训练而获得性能提升。

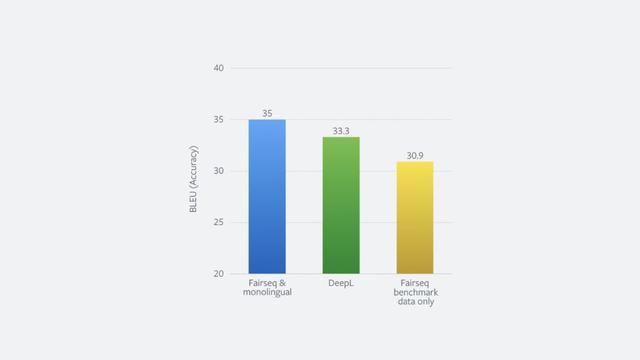
研究者表示,如果我们把 2.26 亿个反向翻译的句子添加到现有的包含 500 万个句子的训练数据中,我们就能大幅提升翻译质量。下图(左)显示了这一系统在标准 WMT』14 英-德基准测试集上的准确率,该系统在 16 个 DGX-1 机器上需要训练 22.5 小时。图中还显示了 DeepL 的准确率,这是一个依赖于高质量人工翻译的专业翻译服务,此前该服务在该基准测试上表现最佳。
MASS:预训练必不可少
BERT 或 XLNet 等预训练语言模型获得了非常好的效果,它们能学习到一些通用的语言知识,并迁移到下游 NLP 任务中。受到这种范式的启发,微软亚研刘铁岩等研究者提出了 MAsked Seq2Seq 预训练模型(MASS),用于基于编码器-解码器的语言生成任务,例如机器翻译。
- 论文:MASS: Masked Sequence to Sequence Pre-training for Language Generation
- 论文地址:https://arxiv.org/abs/1905.02450v5
MASS 采用了编码器-解码器框架,并尝试在给定部分句子的情况下修复整个句子。如下所示为 MASS 的框架图,其输入句子包含了一些连续的 Token,并且中间会带有一些连续的 Mask,模型的任务是预测出被 Mask 掉的词是什么。相比 BERT 只有编码器,MASS 联合训练编码器与解码器,能获得更适合机器翻译的表征能力。

MASS 整体框架,其中「_」表示被 Mask 掉的词。虽然关注自然语言理解的 BERT 只需要编码器就行,但这种关注语言生成的预训练模型需要同时保留编码器与解码器。
正因为这种联合训练编码器-解码器的方法,MASS 非常适合拥有较少双语语料的翻译任务。此外,它在无监督翻译中也能得到非常不错的效果,甚至超过早期基于注意力机制的有监督翻译模型。
在 MASS 中被 Mask 掉的词数量是可选的,如果输入只 Mask 掉一个词(k=1),那么它就等价于 BERT,因为解码器没有了额外的输入信息。如果 Mask 掉所有词,那么就等价于 GPT 这种标准的自回归语言模型,因为编码器完全没有输入信息。如果只 Mask 掉部分词,那么它就非常适合机器翻译这种生成任务了。
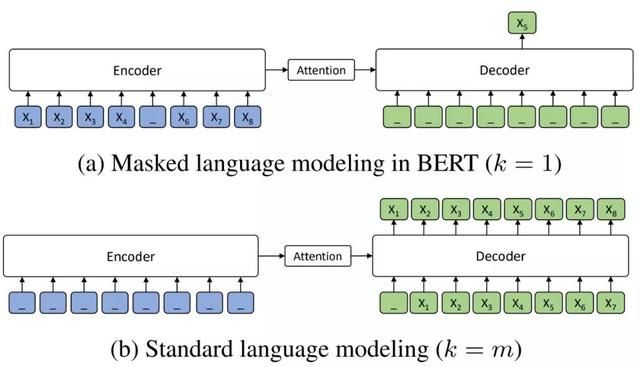
MASS 的两种极限选择,它们分别等价于 BERT 与 GPT。
MASS 这种架构可以强迫编码器理解输入句子的意义,并鼓励解码器从编码器中抽取有用的信息。此外,因为解码器预测的是连续的词,因此它也能构建更强大的语言建模能力。这种结构非常符合语言生成模型的要求,因此经过预训练后的模型只需要简要的微调就能有比较好的效果。
在该论文的实验结果中,这种预训练模型在无监督机器翻译(只有单语数据)和少样本机器翻译中效果都非常出众。此外,即使在通常较为充足的双语数据中,MASS 的预训练也能获得更多的性能提升。
Oracle Word:训练与预测之间有 Gap
目前 NMT 的训练范式有两大局限性。首先在训练过程中,每预测一个译文词,它都会以已知的标注词作为约束,然而在推断中,模型只能以已知的预测词作为约束,这种不匹配就造成了模型在测试集的效果没那么好。其次在训练中,我们要求模型预测的译文必须与标注的译文一一对应,很明显这也会限制翻译的多样性。
为了解决这两个问题,这项研究提出了在训练过程中用 Oracle Word 强化 Ground Truth Word。也就是说,在翻译模型的训练中,它不止会将标注数据作为指导,同时也会将预测结果作为指导。这很大程度上降低了训练和推断之间的差异,并大大提升了模型的预测效果。
- 论文:Bridging the Gap between Training and Inference for Neural Machine Translation
- 论文地址:https://arxiv.org/abs/1906.02448
其中 Oracle Word 可以简单理解为模型预测出的候选词,它的选择方法有两种,即 word-level oracle 和 sentence-level oracle。
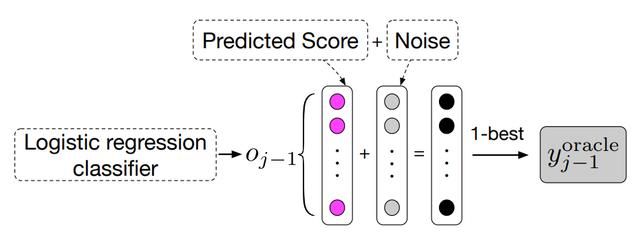
词语级别的 Oracle Word 选择方法。
- word-level oracle 的选择方法如图所示,在时间步为 j 时,获取前一个时间步模型预测出的分数。为了提高模型的鲁棒性,论文在预测分数基础上加上了 Gumbel noise,最终取分数最高的词语作为此时的 Oracle Word。
- sentence-level oracle 的选择方法则是在训练时的解码阶段中,使用束搜索的方法,选择前 k 个备选句子,然后计算每个句子的 BLEU 分数,最终选择分数最高的句子。这种方式选择出来的句子就可以作为模型的预测结果,并指导模型继续学习。
现在有了候选词,那么我们就要考虑如何将它们加入标注词,并共同训练模型。这篇研究的思路非常精炼,即在训练过程中,随机选择两者中的一个作为模型所需的信息。具体而言,如果模型要预测译文的第 j 个词,那么模型会以 p 的概率选择 Oracle Word、以 1-p 的概率选择 Ground Truth Word 作为所需的第 j-1 个译文词。
现在,在训练中,只需要令概率 p 递增,那么相当于从传统的训练过程逐步迁移到推断过程,这两者之间的鸿沟也就不存在了。
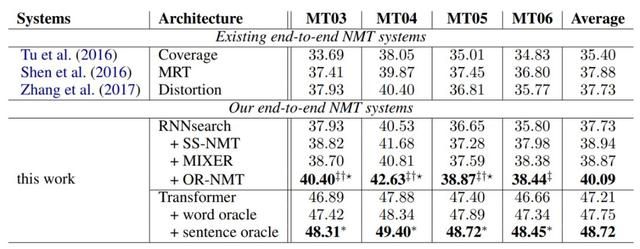
如下所示为该项研究在 NIST Chinese-English 数据集上的效果,其中 MT03 表示 NIST 2003 作为测试集的效果。我们可以看到,不论是将 Oracle Word 加到 RNN 架构还是加到 Transformer 架构,它都能得到性能上的提升(BLEU 值)。
最后,以上 3 个 SOTA 模型只是从不同的角度提升机器翻译效果,SOTA 项目中还能找到更多优秀的模型,它们都有各自的特点与关注的角度。总的而言,理解机器翻译最前沿的思想,这些 SOTA 模型都是要了解的,我们需要从各个角度看看神经机器翻译的潜力到底怎么样。