经典CNN的实现 InceptionNet
经典CNN的实现 InceptionNet
InceptionNet
InceptionNet诞生于2014年,当年ImageNet竞赛冠军,Top5错误率为6.67%
论文出处:Szegedy C, Liu W, Jia Y, et al. Going Deeper with Convolutions. In CVPR, 2015.
InceptionNet旨在通过增加网络的宽度来提升网络的能力,与 VGGNet 通过卷积层堆叠的方式(纵向)相比,是一个不同的方向(横向)。要理解 InceptionNet 的结构,首先要理解它的基本单元:InceptionNet 结构块:
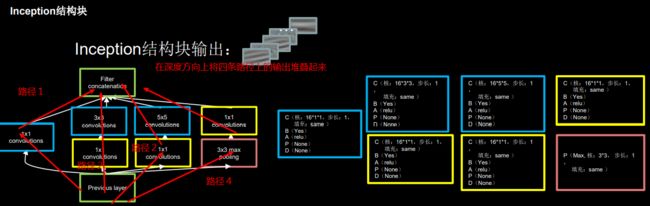
对于一Inception结构块,它的输入会经过四条路径的运算,然后将四天路径的运算在深度方向堆叠在一起,形成输出。
可以看到的是,InceptionNet 的基本单元中,卷积部分是比较统一的 CBA结构,即 卷积→BN→激活,且激活均采用 Relu 激活函数,同时包含最大池化操作。因此我们可以把CBA封装成一个新的类,ConvBNRelu类,以减少代码量,且易于阅读。
class ConvBNRelu(Model):
# 参数 ch 代表特征图的通道数,也即卷积核个数;kernelsz 代表卷积核尺寸;strides 代表 卷积步长;padding 代表是否进行全零填充。
def __init__(self,ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.model=tf.keras.Sequential([
Conv2D(ch,kernelsz,strides=strides,padding=padding),
BatchNormalization(),
Activation('relu')
])
def call(self, x):
x = self.model(x, training=False) #在training=False时,BN通过整个训练集计算均值、方差去做批归一化,training=True时,通过当前batch的均值、方差去做批归一化。推理时 training=False效果好
return x
完成了这一步后,就可以开始构建 InceptionNet 的基本单元了,同样利用class定义的方式,定义一个新的 InceptionBlk 类。

class InceptionBlk(Model):
# 参数 ch 代表通道数,strides 代表卷积步长
def __init__(self,ch,strides=1):
super(InceptionBlk, self).__init__()
self.ch=ch
self.strides=strides
# 路径1
self.r1=ConvBNRelu(ch,kernelsz=1,strides=strides)
# 路径2
self.r2_1=ConvBNRelu(ch,kernelsz=1,strides=strides)
self.r2_2=ConvBNRelu(ch,kernelsz=3,strides=1)
# 路径3
self.r3_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.r3_2 = ConvBNRelu(ch, kernelsz=5, strides=1)
# 路径4
self.r4_1=MaxPooling2D(3,strides=1,padding='same')
self.r4_2=ConvBNRelu(ch,kernelsz=1,strides=strides)
def call(self,x):
x1 = self.r1(x)
x2_1 = self.r2_1(x)
x2_2 = self.r2_2(x2_1)
x3_1 = self.r3_1(x)
x3_2 = self.r3_2(x3_1)
x4_1 = self.r4_1(x)
x4_2 = self.r4_2(x4_1)
# 在深度方向上堆叠
x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3)
return x
InceptionNet网络的主体就是由其基本单元构成的:
注意:这里仅仅搭建了一个深度为 10 的精简版本(完整的 InceptionNet v1,即 GoogLeNet 有 22 层,训练难度很大)
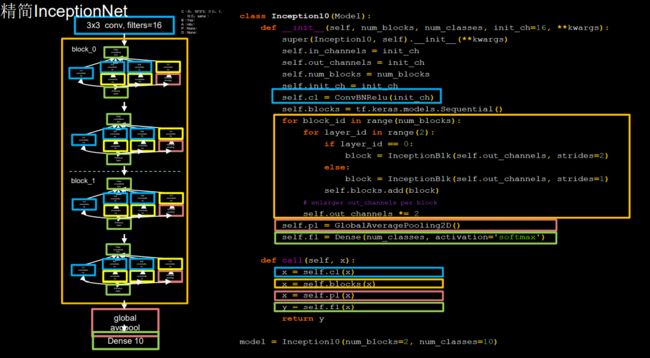
class MyInceptionnet(Model):
# 参数 num_layers 代表 InceptionNet 的 Block 数,每个 Block 由两个基本单元构成,每经 过一个 Block,特征图尺寸变为 1/2,通道数变为 2 倍
# num_classes 代表分类数,对于 cifar10数据集来说即为 10
# init_ch 代表初始通道数,也即 InceptionNet 基本单元的初始卷积核个数。
def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs):
super(MyInceptionnet, self).__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch
self.num_blocks = num_blocks
self.init_ch = init_ch
self.c1 = ConvBNRelu(init_ch)
self.blocks = tf.keras.models.Sequential()
for block_id in range(num_blocks):
for layer_id in range(2):
if layer_id==0:
block=InceptionBlk(self.init_ch,strides=2)
else:
block = InceptionBlk(self.init_ch, strides=2)
self.blocks.add(block)
self.out_channels *= 2
self.p1 = GlobalAveragePooling2D()
self.f1 = Dense(num_classes, activation='softmax')
def call(self,x):
x = self.c1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = MyInceptionnet(num_blocks=2, num_classes=10)
InceptionNet 网络的最后不再像 VGGNet 一样有三层全连接层(全连接层的参数量占 VGGNet 总参数量的 90 %),而是采用“全局平均池化+全连接层”的方式,这减少了大量的参数。
全局平均池化,在 tf.keras 中用 GlobalAveragePooling2D 函数实现,相比于平均池化(在特征图上以窗口的形式滑动,取窗口内的平均值为采样值),全局平均池化 不再以窗口滑动的形式取均值,而是直接针对特征图取平均值,即每个特征图输出一个值。 通过这种方式,每个特征图都与分类概率直接联系起来,这替代了全连接层的功能,并且不 产生额外的训练参数,减小了过拟合的可能,但需要注意的是,使用全局平均池化会导致网络收敛的速度变慢。
总体来看,InceptionNet 采取了多尺寸卷积再聚合的方式拓宽网络结构,并通过 1 * 1 的卷积运算来减小参数量,取得了比较好的效果,与同年诞生的 VGGNet 相比,提供了卷积神经网络构建的另一种思路。但 InceptionNet 的问题是,当网络深度不断增加时,训练会十分困难,甚至无法收敛(这一点被 ResNet 很好地解决了)。