cifar10数据集pytorch
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- cifar10数据集
-
- 导入库
- 导入数据集
- 定义网络
- 标定义损失函数和优化器
- 训练结果
- 采用其他网络进行优化
-
- LeNet
- VGG16
提示:以下是本篇文章正文内容,下面案例可供参考
cifar10数据集
CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机( a叩lane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练圄片和 10000 张测试图片。 CIFAR-10 的图片样例如图所示

这里一共有十个类别,每一个类别随机列举了十张图片。
cifar10数据集和mnist数据集的差别:
• CIFAR-10 是 3 通道的彩色 RGB 图像,而 MNIST 是灰度图像。
• CIFAR-10 的图片尺寸为 32×32, 而 MNIST 的图片尺寸为 28×28,比 MNIST 稍大。
• 相比于手写字符, CIFAR-10 含有的是现实世界中真实的物体,不仅噪声很大,而且物体的比例、 特征都不尽相同,这为识别带来很大困难。 直接的线性模型如 Softmax 在 CIFAR-10 上表现得很差。
导入库
import torch
import torchvision
import torchvision.transforms as transforms
import ssl
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F #交叉熵
import torch.optim as optim
import matplotlib.pyplot as plt #图像绘制
import numpy as np
import time #时间
导入数据集
关于cifar10数据集,可以访问它的官网http://www.cs.toronto.edu/~kriz/cifar.html
transform = transforms.Compose(
[transforms.RandomHorizontalFlip(),
transforms.RandomGrayscale(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]#数据类型的转化,以及将数据进行归一化
)
trainset = torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True, num_workers=2)
#训练集
testset = torchvision.datasets.CIFAR10(root='./cifar10', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)
#测试集
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')#数据的分类
我查了许多代码,有些代码里会出现下面的一行代码,这个是和前面import ssl相对应的。
ssl._create_default_https_context = ssl._create_unverified_context # 解决访问https时不受ssl信任证书的问题
定义网络
这里采用的是简单网络处理的具体代码如下:
class Net(nn.Module):#简单网络
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)#卷积
self.pool = nn.MaxPool2d(2, 2)#池化
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)#全连接层
self.fc3 = nn.Linear(84, 10)
def forward(self,x):#构建模型
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
标定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(20):
timestart = time.time()
running_loss = 0.0
for i,data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 500 == 499:
print('[%d ,%5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 500))
running_loss = 0.0
print('epoch %d cost %3f sec' % (epoch + 1, time.time()-timestart))
print('Finished Training')
这里我用的损失函数是交叉熵,优化器是随机梯度下降,学习率设置的是0.001。使用enumerate() 函数用于将一个可遍历的data数据对象组合为一个索引序列,同时列出数据和数据下标。
当然你也可以使用其他的优化器,比对测试的结果,看看哪一个的优化效果更好。
训练结果
dataiter = iter(testloader)
images, labels = dataiter.__next__()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth:', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data,1)
print('Predicted:', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
correct = 0
total = 0
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the network on the 10000 test images: %d %%' % (100*correct/total))
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))
在这个代码中,我并没有使用全部的数据,全部的数据训练测试的时间太长了,然后分批次输出,计算损失函数,以及测试每一轮所需要的时间,最后它会输出每个类别测试的准确率。
测试结果如下:
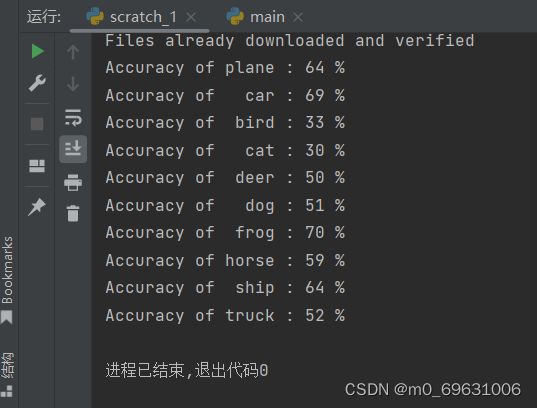
很明显看出准确率并不是很高。
采用其他网络进行优化
我这里只尝试了lenet和vgg16两种网络
LeNet
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(out))
x = F.max_pool2d(x, 2)
x = out.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x) return out
测试的结果如下:

这里和简单网络对比差别不大,基本都是百分之六十左右。
VGG16
vgg16模型这里先不介绍,不了解的可以去看看http://t.csdn.cn/5f3vW
这里是vgg16网络部分的代码
class VGGTest(nn.Module):
def __init__(self, pretrained=True, numClasses=10):
super(VGGTest, self).__init__()
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.relu1_2 = nn.ReLU(inplace=True)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2_1 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.relu2_2 = nn.ReLU(inplace=True)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3_1 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.relu3_2 = nn.ReLU(inplace=True)
self.conv3_3 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.relu3_3 = nn.ReLU(inplace=True)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv4_1 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu4_2 = nn.ReLU(inplace=True)
self.conv4_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu4_3 = nn.ReLU(inplace=True)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu5_2 = nn.ReLU(inplace=True)
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.relu5_3 = nn.ReLU(inplace=True)
self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)
# 从原始的 models.vgg16(pretrained=True) 中预设值参数值。
if pretrained:
pretrained_model = torchvision.models.vgg16(pretrained=pretrained) # 从预训练模型加载VGG16网络参数
pretrained_params = pretrained_model.state_dict()
keys = list(pretrained_params.keys())
new_dict = {}
for index, key in enumerate(self.state_dict().keys()):
new_dict[key] = pretrained_params[keys[index]]
self.load_state_dict(new_dict)
self.classifier = nn.Sequential( # 定义自己的分类层
nn.Linear(in_features=512 * 1 * 1, out_features=256), # 自定义网络输入后的大小。
# nn.Linear(in_features=512 * 7 * 7, out_features=256), # 原始vgg16的大小是 512 * 7 * 7 ,由VGG16网络决定的,第二个参数为神经元个数可以微调
nn.ReLU(True),
nn.Dropout(),
nn.Linear(in_features=256, out_features=256),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(in_features=256, out_features=numClasses),
)
这里我是自己按照vgg16 的网络定义,写了其前5层的卷积的网络结构,并且为了加速收敛,将model.vgg16()的参数初始化了过来。当然了,这里也可以不用自己模仿写出前5层的卷积的网络结构,可以直接利用model.vgg16()的模型,只不过需要把最后的全连接层全部替换掉罢了。这里写一个一模一样的。
至于全连接层则是自定义的,因为原始的model.vgg16()输入图片是224x224大小的,而我们测试cifar10是32x32大小的,尺寸小了7x7倍,因此我们需要自行做出一些改变。
这种拿现成的模型结构和参数来初始化训练的思路也是迁移学习的一种思想。
vgg16网络的层次相对比较深,所以代码比较多,最后也是测出的准确率比另两种网络要高。