语义分割Backbone学习
目录
0.前言
1. AlexNet(2012年)
2. VGG(2014年)
3. GoogleNet(2014年)
3.1 GoogleNet简介
3.2 关于Inception的一步步演变
3.2.1 深度可分离卷积
3.2.2 InceptionV1
3.2.3 InceptionV1 -> InceptionV3
3.2.4 InceptionV3 -> Xception
4. Resnet(2015年)
0.前言
语义分割的backbone大多是由分类网络引申过来的,在这里我只是按照自己看的一些做了总结,并不是特别的全面(例如还有Lenet、NiN等),很多有参考别的博主的博客,这里只是作为自己的学习笔记存储。自己学习的时候,主要看了两位博主的笔记以及他们对应在b站的讲解,所以整理的内容可能和两位博主很相似,有兴趣的自己去看哈,我只是简单整理。
第一位:Bubbliiiing的博客_CSDN博客-神经网络学习小记录,睿智的目标检测,有趣的数据结构算法领域博主
第二位:
太阳花的小绿豆的博客_CSDN博客-深度学习,Tensorflow,软件安装领域博主
1. AlexNet(2012年)
网络亮点:
①首次使用GPU进行加速;
②使用了ReLu激活函数
③使用了LRN局部响应归一化
【注】a. 归一化有助于模型快速收敛 ;b. 对局部神经元的活动创建竞争机制,使得其中响应比较大的值相应变的更大,抑制反馈较小的神经元,增强模型泛化能力。
④在全连接层的前两层使用Dropout随机失活神经元,减少过拟合

图1 Alexnet网络结构图
2. VGG(2014年)
亮点:
堆叠多个3x3的卷积核替代大尺度的卷积核(这么做的目的是减少参数)
解释:2个3x3的卷积核可以替代5x5的卷积核,3个3x3的卷积核可以替代7x7的卷积核(具有相同感受野)
感受野计算公式:![]()
![]() 代表第i层的感受野
代表第i层的感受野
关于参数量:假设输入、输出的channel均为C,那么,
7x7的卷积核的参数量: 7x7xCxC=49![]()
3个3x3的卷积核的参数量:3x3xCxC+3x3xCxC+3x3xCxC=27![]()

图2 VGG网络结构图
3. GoogleNet(2014年)
PS:GoogleNet名字是向LeNet致敬,结构上其实和 LeNet差别较大;GoogleNet中的基础卷积块叫做Inception块,得名与同名电影《盗梦空间》,Inception后面被改进好几版,最新的Xception也是由此演变的,下面可以用一小节讲一下。
3.1 GoogleNet简介
亮点:
①引入了Inception结构(融合不同尺度特征信息);
②使用使用1×1的卷积核进行降维以及映射处理;
③添加两个辅助分类器帮助训练;
④丢弃全连接层,使用平均池化层(大大减少模型参数)

图3 Inception模块
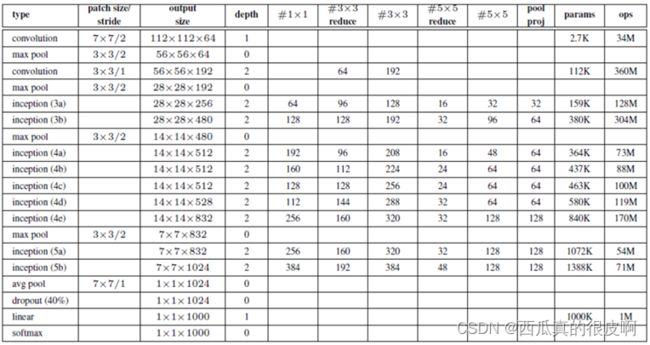
图4 GoogleNet网络结构
3.2 关于Inception的一步步演变
这一节是听b站一个up主讲解的,图都是从视频中截图的。
哔哩哔哩链接:【精读AI论文】谷歌Xception深度可分离卷积的极致Inception轻量化网络_哔哩哔哩_bilibili

图5 Inception的演变图
3.2.1 深度可分离卷积
在后面的演化过程中,会用到深度可分离卷积这一概念,大体思想就是我的输入数据,每一个通道和卷积核里对应通道做卷积运算,所有层运算完之后,再将其合并做1×1的卷积,如下图,看一下就差不多能懂吧。

图6 深度可分离卷积
3.2.2 InceptionV1
最最开始的Inception模块如下图(左)所示,人们在应用过程中做了一点改进(右),加入1×1的卷积层进行通道数的改变,这就是InceptionV1.

图7 InceptionV1
3.2.3 InceptionV1 -> InceptionV3
V1到V3的改进也不是很难理解,为了减少参数量,将5×5的卷积层替换成两个3×3的卷积。
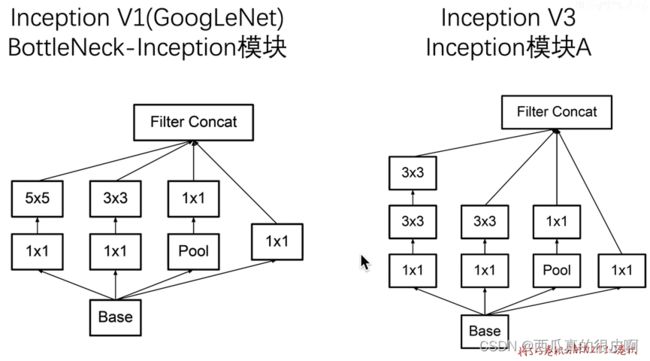
图8 InceptionV1 -> InceptionV3
3.2.4 InceptionV3 -> Xception
从V3到Xception经历了5次简化。
(1)第一次简化,去掉了网络中的1×1卷积层,将其改为3×3.

图9 第一次简化
(2) 第二次简化,只包含第一层为1×1的卷积层,且全部换为一个3×3的卷积层
 图10 第二次简化
图10 第二次简化
(3)进一步简化,合并1×1的卷积层
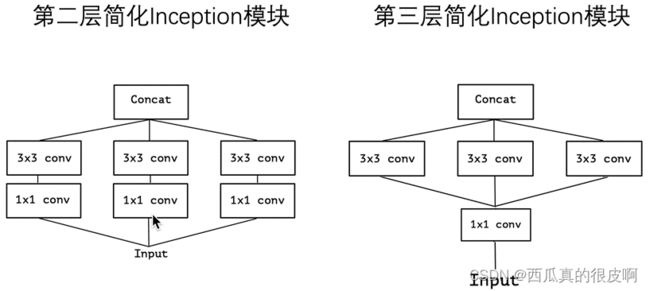
图11 第三次简化
(4)进一步简化,每一个3×3卷积只对输入的一部分channel进行卷积,这里的1×1卷积之后的通道数为3个3×3卷积的通道数,这样到第二层的时候,每一个3×3卷积只和其中的一部分做卷积运算,如下图所示:

图12 第四次简化
(5)最后一步简化,将上一步做到极致,每一个3×3卷积只对输入的一个channel进行卷积

图13 第五次简化
4. Resnet(2015年)
Resnet是目前应用最多的,效果也很好,大神不愧是大神,吾等只能膜拜~
亮点:
①超深的网络结构(突破1000层)
②提出residual模块(解决随着层数增加网络退化的问题)
③使用Batch Normalization加速训练,丢弃dropout层(解决梯度消失和梯度爆炸的问题)
【注】resnet50层一下称为浅层网络,50层及50层以上称为深层网络,二者在结构上稍微有一点点不同。
Resnet网络结构如下:
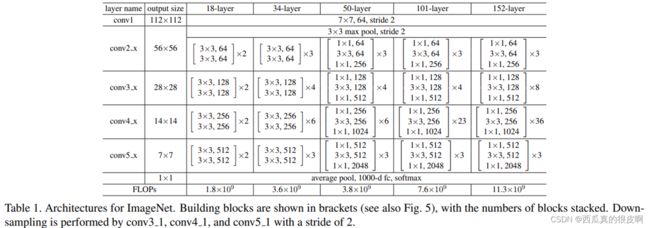
图14 Resnet网络结构
每个残差块结构如下:

图15 残差块(左:浅层网络;右:深层网络)
由于conv_2之后每个conv_i要在第一块进行降采样(图14),因此,每个conv_i的第一层不能直接进行相加(大小不一样),操作如下:
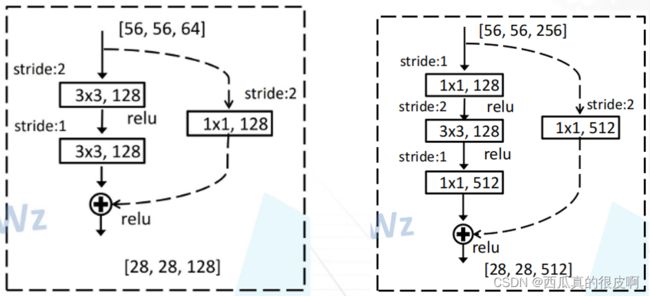
图16 每个Conv_i的第一层结构(左:浅层网络;右:深层网络)