keras实现-台大李宏毅深度学习作业HW3-基于CNN(卷积神经网络)的面部表情识别
一、项目说明:
卷积神经网络(CNN)在图像识别中已经获得了很大的进展,此项目旨在使用TensorFlow的keras接口来搭建CNN模型,来体验一下CNN的作用。对已有的数据集 train.csv,训练处一个分类模型,然后用该模型来判断每一个样本图片的表情。
数据集介绍:
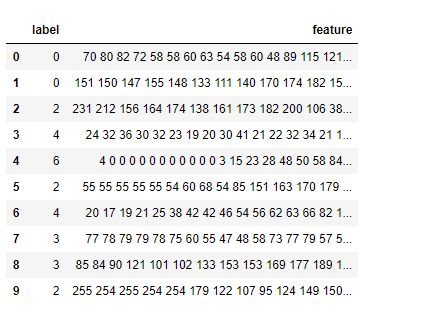
(1)该数据集为一个CSV文件,是一个28710行,2305列的数据。
(2) 第一行为描述信息,“label“和“feature“,剩下的每一行都是样本。
(3) 这个数据集总共有7种标签,对应不同的表情。分别是:0代表生气,1代表恶心,2代表恐惧,3高兴,4难过,5惊讶,6木讷。
(4) 对于每一个样本,第一列是样本的标签,数值在(0-6之间)。其余2304(=48*48)列是图片的像素值,每个像素值取值范围在(0-255之间)。
(5) 数据集地址:https://pan.baidu.com/s/1hwrq5Abx8NOUse3oew3BXg ,提取码:ukf7 。
数据预处理:
(1)、用pandas读取train.csv,并查看前10条的数据。
:![]()
(2)、切训练数据(x)和对应的标签(y)(label下面的是标签,feature下面的是训练数据):

切完的数据并转为array(CNN要接收矩阵输入),然后进行查看:
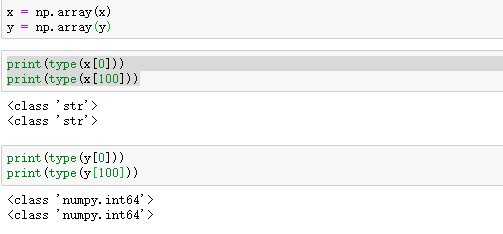
可以看出x的每一个元素都是str, 也就是说每一张图片48*48的像素值都是一个字符串:

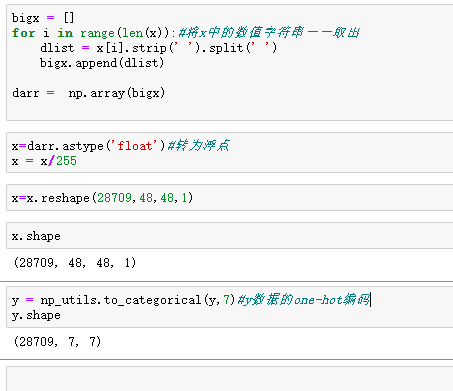
但是CNN要求的输入是一个三维的矩阵,维度为(48,48,1),前面两个数值表示每张图片样本的像素值48*48,1表示颜色,这里是黑白图片,所以颜色值维度为1。由上图,每个图片被存储成了字符串,要将字符串个是每个数值字符转为浮点型,总共有22709张图片,所以要将x转为(22709,48,48,1)的浮点型矩阵x,然后x/255(图片数据归一化)。
对于y的数据中,第一列数据是整型。我们把它用one-hot的方式编码,即在第几个位置置1,就表示数字几。其他位置置0。这里总共有6个数字(0,1,2,3,4,5,6),即用一个7维的向量表示。比如0=[1,0,0,0,0,0,0],1=[0,1,0,0,0,0,0],2=[0,0,1,0,0,0,0].....,总共有22709个样本,所以y为(22709,7)的矩阵。
到这里数据就处理完毕了!下面就开始分割数据(因为没有测试集,所以把一部分数据分割为测试集),然后用keras搭建CNN模型。

注意CNN模型的最后面需要将数据平坦化(Flattern),这里后面接了好几层的全连接层(不接训练准确率上不去),但是用了全连接层后,虽然训练准确率达到80%几,即使正则化和Dropout用上去,模型还是过拟合了。最终测试数据的准确率一直在50%左右上不去。
我猜测可能是数据集有点不干净,或者是参数没有调好。大家可以自己调一下网络层和超参数,如果有好的解决办法,请留言给我,非常感谢!
源代码如下:
from sklearn.model_selection import train_test_split
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Conv2D,MaxPooling2D,Flatten
from tensorflow.python.keras.layers import Dense,Dropout,Activation
from tensorflow.python.keras.utils import np_utils
from tensorflow.python.keras.optimizers import Adam,SGD
import tensorflow as tf
import pandas as pd
import numpy as np
from tensorflow.python.keras import regularizers
data = pd.read_csv('train_data.csv')
data.head(10)
x = data['feature']
y = data['label']
x = np.array(x)
y = np.array(y)
print(type(x[0]))
print(type(x[100]))
print(type(y[0]))
print(type(y[100]))
bigx = []
for i in range(len(x)):#将x中的数值字符串一一取出
dlist = x[i].strip(' ').split(' ')
bigx.append(dlist)
darr = np.array(bigx)
x=darr.astype('float')#转为浮点
x = x/255
x=x.reshape(28709,48,48,1)
x.shape
y = np_utils.to_categorical(y,7)#y数据的one-hot编码
y.shape
X_train,X_test,y_train,y_test=train_test_split(x_train,y,train_size=0.8,random_state=12)
model = Sequential()#建立神经网络结构
model.add(Conv2D(20,(3,3),input_shape=(48,48,1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(25,(3,3),kernel_regularizer=regularizers.l2(0.01)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(50,(3,3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(250, activation='relu'))
Dropout(0.2)
model.add(Dense(250, activation='relu'))
Dropout(0.5)
model.add(Dense(250, activation='relu',kernel_regularizer=regularizers.l2(0.01)))
Dropout(0.5)
model.add(Dense(250, activation='relu',kernel_regularizer=regularizers.l2(0.01)))
model.add(Dense(500, activation='relu',kernel_regularizer=regularizers.l2(0.01)))
Dropout(0.5)
model.add(Dense(7, activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=[tf.keras.metrics.categorical_accuracy])
# 查看神经网络结构
model.summary()
model.fit(X_train,y_train,validation_split=0.2,batch_size=100,epochs=20)
result = model.evaluate(X_test, y_test)
print("准确率:",result[1]):