【自然语言处理】【ChatGPT系列】大模型的涌现能力
论文地址:https://arxiv.org/pdf/2206.07682.pdf
相关博客
【自然语言处理】【ChatGPT系列】大模型的涌现能力
【自然语言处理】【文本生成】CRINEG Loss:学习什么语言不建模
【自然语言处理】【文本生成】使用Transformers中的BART进行文本摘要
【自然语言处理】【文本生成】Transformers中使用约束Beam Search指导文本生成
【自然语言处理】【文本生成】Transformers中用于语言生成的不同解码方法
【自然语言处理】【文本生成】BART:用于自然语言生成、翻译和理解的降噪Sequence-to-Sequence预训练
【自然语言处理】【文本生成】UniLM:用于自然语言理解和生成的统一语言模型预训练
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
一、简介
语言模型已经彻底改变了自然语言处理 (NLP) \text{(NLP)} (NLP)。总所周知,增加语言模型的规模能够为一系列下游的 NLP \text{NLP} NLP任务带来更好的效果和样本效率。在某些场景中,模型规模对于模型的效果可以通过 scaling laws \text{scaling laws} scaling laws预测。但是,某些下游任务的效果并没有随着规模的上升而改善。
本文讨论了大规模语言模型的涌现能力 (Emergent Ability) \text{(Emergent Ability)} (Emergent Ability),一种不可预测的现象。涌现这一概念已经在物理、生物、计算机科学等领域被讨论了很长时间。本文考虑涌现的一般性定义,来自于诺贝尔物理学奖得主Philip Anderson1972年的一篇文章《More is Different》。
Emergence is when quantitative changes in a system result in qualitative changes in behavior. \text{Emergence is when quantitative changes in a system result in qualitative changes in behavior.} Emergence is when quantitative changes in a system result in qualitative changes in behavior.
本文将讨论与模型规模相关的涌现能力,并通过训练计算量和模型参数进行衡量。本文定义大规模语言模型的涌现能力为:在小模型上没有,但是会出现在大模型上的能力。因此,该能力不能通过简单的对小规模模型的改善了预测。本文总结了先前工作中一系列观察到的涌现能力,并将其分类为 few-shot prompting \text{few-shot prompting} few-shot prompting和 augmented prompting strategies \text{augmented prompting strategies} augmented prompting strategies。涌现现象也会激发更多的研究,包括为什么能有这样的能力、是否更大的模型将带来进一步的涌现。
二、涌现能力定义
涌现是一个广泛的概念,通常有着不同的解释。本文主要是专注在大规模语言模型的涌现能力:
An ability is emergent if it is not present in smaller models but is present in larger models. \text{An ability is emergent if it is not present in smaller models but is present in larger models.} An ability is emergent if it is not present in smaller models but is present in larger models.
涌现能力无法使用 scaling law \text{scaling law} scaling law来从较小模型上进行预测。当绘制一个尺度曲线, x x x轴是模型的尺寸, y y y轴是某种能力的效果,那么涌现能力有一个清晰的模式:在某个阈值之前的效果接近随机,但是超过该阈值后效果将大大高于随机。
当今的语言模型根据三个因素进行扩展:计算量、模型参数量和训练集规模。本文将绘制各种"训练量-效果"曲线,每个模型的训练量通过 FLOPs \text{FLOPs} FLOPs来衡量。由于语言模型使用更多的计算量,也意味着更多的参数量,所以也额外绘制了 x x x轴为模型参数量的图。由于大多数稠密 Transformer \text{Transformer} Transformer语言模型都会基于模型的参数量来粗略估计训练计算量(也就是参数量和训练计算量大致线性相关),因此使用训练 FLOPs \text{FLOPs} FLOPs或者模型参数量作为 x x x轴,最终得到的曲线将是相似的。
虽然训练集的尺寸也很重要,但是许多语言模型族对所有尺寸的模型使用了固定数量的训练样本,所以没办法绘制相关的图。因此,本文专注在训练计算量和模型尺寸,但是没有一种单独的指标能够充分捕获所有规模的性质。例如, Chinchilla \text{Chinchilla} Chinchilla的参数量是 GOpher \text{GOpher} GOpher的四分之一,但是使用相似的训练计算量。稀疏混合专家模型在每次训练/推断时要比稠密模型具有更多的参数量。总的来说,明智的做法是将涌现看作是许多相关变量的函数。
某种能力的涌现尺度取决于许多因素,且这些因素也不是不可改变的属性。例如,涌现可能出现在高质量数据上训练的更少训练量、更少模型参数的模型。此外,涌现能力也可能会依赖其他的因素,而不是数据量、数据质量或者模型的参数量。当今训练语言模型的方法可能不是最优的,并且对于最优模型的理解随着时间推移而进化。
三、 Few-Shot Prompted \text{Few-Shot Prompted} Few-Shot Prompted任务
首先讨论 GPT-3 \text{GPT-3} GPT-3中流行的 prompting \text{prompting} prompting范式的涌现能力。给预训练语言模型一个任务相关的 prompt \text{prompt} prompt,其不需要任何训练或者梯度更新就能完成应答。Brown et al.提出了 few-shot prompting \text{few-shot prompting} few-shot prompting,其在模型的输入中包含少量的"输入-输出"示例,并要求模型在未见过的样本上完成任务。上图是一个 prompt \text{prompt} prompt例子。
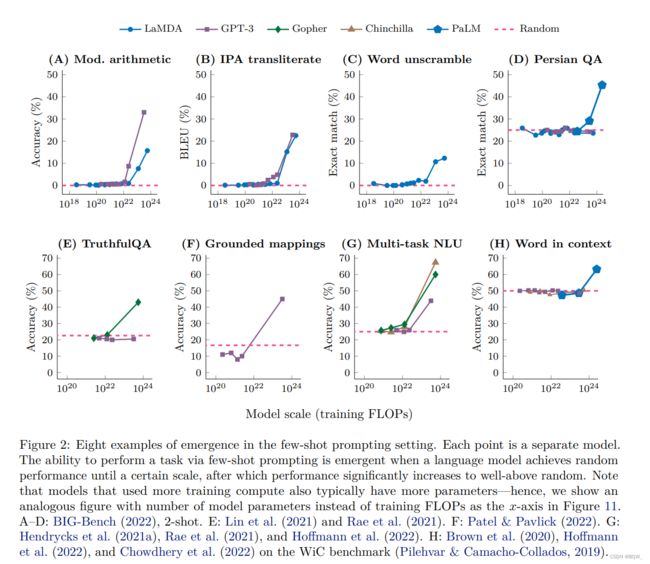
"通过 few-shot prompting \text{few-shot prompting} few-shot prompting来执行任务的能力"是一种涌现现象,当模型规模达到某个阈值之前效果基本等于随机,超高该阈值够则会显著的改善。下图展示了5个语言模型的8种涌现能力。
1. BIG-Bench \text{BIG-Bench} BIG-Bench
图A-D是来自于基准 BIG-Bench \text{BIG-Bench} BIG-Bench中的4个涌现 few-shot prompted \text{few-shot prompted} few-shot prompted任务,该基准包含了200多个评估语言模型的基准套件。图A是一个算术基准测试,用于测试3位加减法和2位的乘法。 GPT-3 \text{GPT-3} GPT-3和 LaMDA \text{LaMDA} LaMDA的训练量较小时的效果基于接近于0,而 GPT-3 \text{GPT-3} GPT-3在训练量达到 2 ⋅ 1 0 22 FLOPs 2\cdot 10^{22}\text{ FLOPs} 2⋅1022 FLOPs后效果突然超越随机,而 LaMDA \text{LaMDA} LaMDA的阈值为 1 0 23 FLOPs 10^{23}\text{ FLOPs} 1023 FLOPs。对于其他任务来说,类似的涌现能力也发生在相同的规模,包含:国际音标翻译(图B)、从混乱的字母中恢复出单词(图C)、以及波斯语问答。文章的附录E中给出了 BIG-Bench \text{BIG-Bench} BIG-Bench上更多的涌现能力。
2. TruthfulQA \text{TruthfulQA} TruthfulQA
上图E展示了 TruthfulQA \text{TruthfulQA} TruthfulQA基准上的 few-shot prompted \text{few-shot prompted} few-shot prompted涌现能力,该基准用来衡量诚实回答问题的能力。该基准是通过对抗的方式针对 GPT-3 \text{GPT-3} GPT-3构建的,所以即使将 GPT-3 \text{GPT-3} GPT-3放大到最大的规模,其效果也不会高于随机。小尺寸的 Gopher \text{Gopher} Gopher模型效果也接近随机,但是当模型放大至 5 ⋅ 1 0 23 FLOPs(280B) 5\cdot 10^{23} \text{ FLOPs(280B)} 5⋅1023 FLOPs(280B),其效果会突然高于随机20%。
3. Grounded conceptual mappings \text{Grounded conceptual mappings} Grounded conceptual mappings
上图F展示了 Grounded conceptual mappings \text{Grounded conceptual mappings} Grounded conceptual mappings任务,该任务中语言模型必须学会映射一个概念领域,例如:理解文本中方向的表示。同样,使用大的 GPT-3 \text{GPT-3} GPT-3模型效果才能超过随机。
4. Multi-task language understanding \text{Multi-task language understanding} Multi-task language understanding
上图G展示了 Massive Multi-task Language Understanding(MMLU) \text{Massive Multi-task Language Understanding(MMLU)} Massive Multi-task Language Understanding(MMLU)基准,该基准包含了57个测试,覆盖主题包含数学、历史、法律等等。对于模型 GPT-3、Gopher、Chinchilla \text{GPT-3、Gopher、Chinchilla} GPT-3、Gopher、Chinchilla,当训练计算量小于 1 0 22 FLOPs 10^{22} \text{FLOPs} 1022FLOPs时,在所有的主题上效果都解决随机,但是当训练计算量达到 3-5 ⋅ 1 0 23 FLOPs(70B-280B) \text{3-5}\cdot 10^{23}\text{ FLOPs(70B-280B)} 3-5⋅1023 FLOPs(70B-280B)后效果将远远超过随机。该结果并不令人惊奇,这意味着解决那些需要大量主题集合并且基于知识的问题的能力可能需要超过某个阈值。
5. Word in Context \text{Word in Context} Word in Context
最后,上图H展示了 Word in Context \text{Word in Context} Word in Context基准,该基准是一个语义理解基准。显然, GPT-3 \text{GPT-3} GPT-3和 Chinchilla \text{Chinchilla} Chinchilla即使放大至最大的尺寸 ∼ 5 ⋅ 1 0 23 FLOPs \sim 5\cdot 10^{23} \text{ FLOPs} ∼5⋅1023 FLOPs,也不能通过one-shot实现比随机更好的效果。目前为止的结果表明单纯的发大模型并不能解决 Word in Context \text{Word in Context} Word in Context基准,但是当 PaLM \text{PaLM} PaLM被缩放至 2.5 ⋅ 1 0 24 FLOPs(540B) 2.5\cdot10^{24}\text{ FLOPs(540B)} 2.5⋅1024 FLOPs(540B)时,高于随机的效果出现了。
四、 Augmented Prompting \text{Augmented Prompting} Augmented Prompting策略
虽然 few-shot prompting \text{few-shot prompting} few-shot prompting是目前与大规模语言模型交互最常用的方法,但近期的工作提出了其他prompting和微调策略来进一步增强语言模型的能力。若某一项技术对于baseline没有改进或者是有害的,但是当模型达到某个规模后该技术就生效了,则认为该技术也是涌现能力。
1. 多步推理
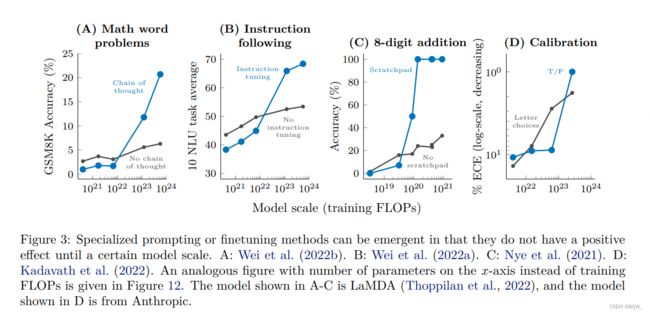
多步推理对于语言模型来说非常有挑战。近期,一种称为 chain-of-thought prompting \text{chain-of-thought prompting} chain-of-thought prompting的 prompting \text{prompting} prompting策略能够使模型解决多步推理问题,该策略要求语言模型在给出答案之前产生出一系列的中间步骤。如上图A所示,当模型规模达到 1 0 23 FLOPs ( ∼ 100B ) 10^{23}\text{ FLOPs}(\sim\text{100B}) 1023 FLOPs(∼100B), chain-of-thought prompting \text{chain-of-thought prompting} chain-of-thought prompting就会超越标准的 prompting \text{prompting} prompting。
2. 指令遵循 (Instruction following) \text{(Instruction following)} (Instruction following)
另一个正则快速发展的工作时,通过让语言模型来阅读描述任务的指令来让其更好的执行新任务。通过对混合任务的指令进行微调,语言模型可以对一个未见过的任务做出适当的应答。如上图B所示,Wei et al.发现该 instruction-finetuning \text{instruction-finetuning} instruction-finetuning技术对于训练量小于 7 ⋅ 1 0 21 FLOPs(8B) 7\cdot10^{21}\text{ FLOPs(8B)} 7⋅1021 FLOPs(8B)的模型效果有害,仅能够改善训练量大于 1 0 23 FLOPs ( ∼ 100B ) 10^{23}\text{ FLOPs}(\sim\text{100B}) 1023 FLOPs(∼100B)的模型。
3. Program execution
对于多步计算问题,Nye et al.的研究显示,对语言模型进行微调来预测中间输出可以使模型成功执行这种多步运算。如上图C所示,对于8位数加法,仅对训练量为 ∼ 9 ⋅ 1 0 19 FLOPs \sim 9\cdot 10^{19}\text{ FLOPs} ∼9⋅1019 FLOPs的模型有用。
4. Model calibration
最后一个重要的语义模型研究方向是模型校准,也就是衡量模型是否能够预测出其对哪些问题能够回答正确。Kadavath et al.比较了两种校准方法:1. True/False技术,模型先给出答案,然后让模型评估这个答案的正确性;2. 更标准的校验方法,使用正确答案的概率与其他答案进行对比。如上图D所示,True/False技术只有当模型规模达到 ∼ 3 ⋅ 1 0 23 FLOPs \sim 3\cdot10^{23}\text{FLOPs} ∼3⋅1023FLOPs才能有效。
五、讨论
上面的实验中的能力只有在足够大的语义模型上才能观察到,因此这些能力的涌现并不能通过外推小规模模型来简单预测。涌现出来的 few-shot prompted \text{few-shot prompted} few-shot prompted能力是不可预测的,因为这些能力并没有包含预训练任务中,并且我们无法知道语言模型执行 few-shot prompted \text{few-shot prompted} few-shot prompted任务的全部范围。语言模型目前还有很多不能通过涌现实现的能力,包括 BIG-Bench \text{BIG-Bench} BIG-Bench中数十个任务,这些任务即使是最大的 GPT-3 \text{GPT-3} GPT-3和 PaLM \text{PaLM} PaLM模型都不能实现高于随机的表现。
1. 涌现的潜在解释
虽然已经有数十个涌现能力的例子,但是对于这种能力为什么会以这种方式出现还没有令人信服的解释。对于某个任务为什么涌现需要模型规模超过某个阈值,可能有一种直觉上的解释。例如,若一个多步推理需要 l l l步的序列计算,这可能需要模型至少有 O ( l ) O(l) O(l)层的深度。一个合理的假设,更多的参数和更多的训练能够确保更好的记忆那些有助于各类任务的世界知识。例如,要在closed book问答上取得好的表现,可能需要一个模型具有足够的参数来捕获知识库本身(基于语言模型的压缩要比传统的压缩器具有更高的比例)。
评估涌现能力的指标也很重要。例如,若使用精确字符串匹配作为长序列的评估指标,真实情况可能是逐步的改善,只不过评估指标导致看起来是涌现现象。类似的逻辑也可能发生在多步推理或者数学推理,模型只对多步推理的最终结果进行评分,而没有对部分正确的解决方案进行评分。然而,最终答案准确率的跳跃式改善并不能解释中间步骤突然高于随机。
我们使用交叉熵损失函数来替代评估指标,在6个 BIG-Bench \text{BIG-Bench} BIG-Bench任务上虽然下游指标仍然接近随机,但是损失函数值在小规模模型上仍然改善,这表明模型的此次改善被下游的评估指标所掩盖。然而,该分析也并不能解释为什么下游指标的涌现现象。总的来说,还需要更多的工作来梳理是什么使得规模能够导致解锁涌现的能力。
2. 超越规模
虽然某个确定的尺寸能够观察到涌现能力,但是该能力随后在更小尺寸被实现。也就是说,模型的尺寸并不是解锁涌现能力的唯一因素。例如, LaMDA 137B \text{LaMDA 137B} LaMDA 137B和 GPT-3 175B \text{GPT-3 175B} GPT-3 175B模型在14个 BIG-Bench \text{BIG-Bench} BIG-Bench任务上都是解决随机的,但是 PaLM 62B \text{PaLM 62B} PaLM 62B使用更少的参数和训练 FLOPs \text{FLOPs} FLOPs实现了高于随机的效果。尽管还没有实证研究来消除 PaLM 62B \text{PaLM 62B} PaLM 62B与先前模型的区别, PaLM \text{PaLM} PaLM表现更好的潜在原因可能包括高质量的训练数据和架构的不同。另一个潜在的解锁涌现能力的方法是通过不同的预训练目标。
一旦某种涌现能力被发现,进一步的研究将使该能力在更小规模的模型上可用。在使用自然语言描述新任务来使用语言模型的新方向中,Wei et al.发现 instruction-based finetuning \text{instruction-based finetuning} instruction-based finetuning仅在 68B \text{68B} 68B或者更大的模型,随后Sanh et al.在 11B \text{11B} 11B的编码器-解码器架构上诱导出了相似的行为。另一个例子,Ouyang et al.提出d的 InstructGPT \text{InstructGPT} InstructGPT模型基于人类反馈进行强化学习和微调,其能够在 1.3B \text{1.3B} 1.3B模型上超越大多数的模型。
还有一些工作尝试改善语言模型的通用 few-shot prompting \text{few-shot prompting} few-shot prompting能力。对"为什么语言建模目标可以促进某些下游行为"这件事的理解和解释性研究,反过来也会对在小规模模型上实现这些能力带来影响。例如,预训练数据的某些特征(一致性、包含稀有类型)也已经被证明其与涌现 few-shot prompting \text{few-shot prompting} few-shot prompting相关,并且可以使更小的模型具有相同的能力。计算语言学的研究进一步表明,当模型参数和训练 FLOPs \text{FLOPs} FLOPs保持不变时,训练数据的阈值频率能够激活语法规则学习的涌现能力。随机预训练研究的发展,降低涌现能力的规模阈值将会对研究这些能力越来越重要。
仅通过增加规模对于应用和研究来说是有限制的。例如,规模可能会受到硬件瓶颈的约束,并且某些能力在这个点上可能还没有涌现。某些能力可能不会涌现,即使是一个非常大的训练集,但是远离分布的任务可能永远不能实现好的效果。
3. 涌现风险
few-shot prompting \text{few-shot prompting} few-shot prompting并没有包含在预训练中,但是其能够通过涌现来实现,风险可能也会以类似的方式出现。大规模语言模型的社会风险,包含真实性、偏见和毒性都是一个增长的研究领域。这类风险需要着重考虑,无论其是否通过涌现能力出现。涌现能力会随着语言模型增大而出现,那么随着模型规模的增加,风险也在增加。
这里总结一些先前的发现。在 WinoGender \text{WinoGender} WinoGender上,随着模型规模的增加,职业中的性别歧视被改善了。而 BIG-Bench \text{BIG-Bench} BIG-Bench的 BBQ \text{BBQ} BBQ偏见基准上,对于模糊的上下文,偏见会随着规模的增加而增加。对于毒性, Askell et al. \text{Askell et al.} Askell et al.发现较大 的语言模型能够从 RealToxicityPrompts \text{RealToxicityPrompts} RealToxicityPrompts数据中生成更多毒性的响应,这种行为可以通过给模型一些无毒的示例来缓解。 TruthfulQA \text{TruthfulQA} TruthfulQA基准展示了 GPT-3 \text{GPT-3} GPT-3模型越大就越有可能模仿人类说谎言。
4. 未来的方向
一些潜在的未来方向包含但不限于:
-
进一步扩大模型规模
目前为止,进一步扩大模型的规模是能够增加语言模型的能力,并且也是一种未来工作的方向。然而,简单的增加语言模型规模是计算昂贵的,并且需要解决巨大的硬件挑战,因此其他方法将会在未来语言模型的涌现能力扮演重要的角色。
-
改善模型架构和训练
改善模型的架构或者训练过程可能会带来具有涌现能力的高质量模型,并减少计算量。一种方向是使用稀疏混合专家架构,其在保持恒定输入成本时具有更好的计算效率,使用更加局部的学习策略,而不是在神经网络的所有权重上进行反向传播,以及使用外部存储来增强模型。这些新兴的方向已经在许多设置中展现出了前景,但是仍然没有被广泛的使用,这需要未来的工作。
-
扩大数据规模
在一个足够大的数据集上训练足够长的时间被证明是语言模型获得语法、语义和其他世界知识的关键。近期,
Hoffmann et al.认为先前的工作低估了训练一个最优模型的训练数据量,低估了训练数据的重要性。收集模型可以在其上训练更长时间的大量数据,允许在一个固定模型尺寸的约束下有更大范围的涌现能力。 -
prompting \text{prompting} prompting更好的技术和更好的理解
虽然 few-shot prompting \text{few-shot prompting} few-shot prompting简单有效,对 prompting \text{prompting} prompting通用性的改善将进一步扩展语言模型的能力。例如,使用校准输出概率或者噪音通道已经改善了广泛的任务。用带有中间步骤的 few-shot \text{few-shot} few-shot示例增强后,能够使模型执行多步推理任务,这是标准 prompting \text{prompting} prompting无法实现的。此外,更好的解释为什么 prompting \text{prompting} prompting有效,可能对在更小模型上引导涌现能力具有帮助。充分的理解模型为什么能够工作通常会滞后于技术的开发和流行,并且随着更加强大的模型被开发出来,
prompting的最佳实践也可能改变。 -
前沿任务
虽然语言模型能够执行广泛的任务,但仍然有很多任务即使是最大的语言模型都无法超过随机的准确率。 BIG-Bench \text{BIG-Bench} BIG-Bench中存在大量的这类任务,这些任务涉及到抽象推理(例如扮演象棋、挑战数学)。未来的研究可能需要调查为什么这些能力还没有出现,以及如何使得模型能够执行这些任务。展望未来,另一个增长的方向可能是多语言涌现;多语言 BIG-Bench \text{BIG-Bench} BIG-Bench任务表明:模型规模和训练数据在涌现中扮演着重要的角色。其他的前沿任务包括多模态prompting。
-
理解涌现
除了研究如何进一步解锁涌现能力,一个未来研究方向是,涌现能力是如何以及为什么出现在大语言模型。本文对 BIG-Bench \text{BIG-Bench} BIG-Bench上的交叉熵损失与规模的关系、生成任务的不同度量、以及哪种任务会出现涌现。这个分析并不能完整解释为什么会出现涌现。未来的研究可能会以新的方式来分析涌现。总的来说,理解涌现是一个非常重要的方向,这有助于我们确定模型可以拥有哪些涌现能力以及如何训练一个能够更强的语义模型。