机器学习之集成学习
集成学习是机器学习中的一大分支。本篇文章重在梳理整个集成学习这一大分支的框架,所以更多的是概念,具体到某一细枝末叶会在后续文章单独给出详细介绍。
出现背景:
单个机器学习模型所能解决的问题有限,泛化能力差,但是通过构建组合多个学习器来完成学习任务往往能够获得奇效,这些学习器可以看成是一个个基本单元,由他们组合最终形成一个强大的整体,该整体可以解决更复杂的问题,集成学习的思想可以形象的归结为一句话:三个臭皮匠顶一个诸葛亮。
分类:
根据上述单个学习器的产生过程的不同,集成学习大致可以分为两大类:串行和并行
串行:个体学习器们的产生依赖彼此,比如当前学习器的产生依赖上一个学习器的参数,所以最终将单个学习器们组合形式可以看 做是串行序列化方法,代表是Boosting.
并行:个体学习器间不存在强依赖关系、可并行化同时生产,代表是Bagging
Boosting:
Boosting一般需要考虑两个方面:
1)在每一轮如何改变训练数据的权值或概率分布?
2)通过什么方式来组合弱分类器?
AdaBoost便是Boosting思想的实践产物之一,该算法将上面的过程自动化,程序化,话句话说一切都可以自动完成训练。
对于第一个方面其是:
通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样本的权值,而误分的样本在后续受到更多的关注.
对于第二个方面其是:
通过加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值.
GBDT也是Boosting思想的实践产物之一,但其不同于AdaBoost其是提升树通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型(后续文章详细介绍)
XGBOOST是GBDT升级版,是其高效实现版本,极大地提升了模型训练速度和预测精度,也是目前最受欢迎的机器学习模型之一。
Bagging:
其主要的伎俩核心其实在于抽样方法,例如bootstrap aggregating
1)每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(有放回的抽取,即有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中).共进行k轮抽取,得到k个训练集.(k个训练集相互独立)
2)每次使用一个训练集去训练得到一个模型,k个训练集共得到k个模型.(具体到用什么模型可以根据具体问题而定)
3)预测结果:对分类问题便是将上述得到的k个模型采用投票的方式得到分类结果;对回归问题变数计算上述模型的均值作为最后的结果.
当模型选用决策树时,便是我们熟悉的随机森林,实践篇章:python_sklearn机器学习算法系列之RandomForest(随机森林算法)_爱吃火锅的博客-CSDN博客_randomforestregressor
Boosting和Bagging区别:
1)样本选择上:
Bagging:训练集多次在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的.
Boosting:每一轮的训练集个数不变
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大.
3)预测函数:
Bagging:所有预测函数的权重相等.
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重.
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
最后大致总结一下其关系图:
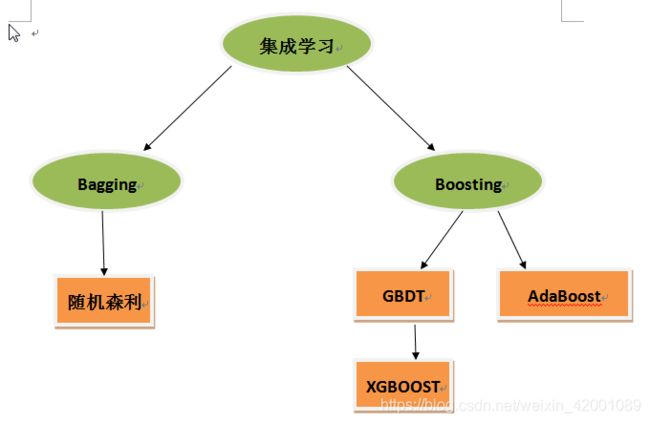
GBDT详细介绍:集成学习之GBDT超详细推导_爱吃火锅的博客-CSDN博客_gbdt推导
Xgboost详细介绍:集成学习之Xgboost超详细推导_爱吃火锅的博客-CSDN博客
最近预训练模型大火特火,我们在其上也可以将集成学习融入进去,可以看:
文本挖掘从小白到精通(二十七)--效果提升显著的BERT集成学习
欢迎关注笔者的微信公众号和知乎,会有更多的分享:
知乎:小小梦想 - 知乎
微信公众号
