【论文解读】SKNet网络(自适应调整感受野尺寸)
Selective Kernel Networks
论文:https://arxiv.org/abs/1903.06586
代码:https://github.com/implus/SKNet
摘要
在标准卷积神经网络(CNN)中,每层中人工神经元的感受野被设计成共享相同的大小。在神经科学界众所周知,视觉皮层神经元的感受野大小受到刺激的调节,这在构建CNN时很少被考虑。我们在CNN中提出了一种动态选择机制,允许每个神经元根据输入信息的多个尺度自适应地调整其感受野大小。设计了一个名为Selective Kernel(SK)单元的构建块,其中使用由这些分支中的信息引导的softmax attention来融合具有不同卷积核大小的多个分支。对这些分支的不同关注产生了融合层中神经元的有效感受野的不同大小。多个SK单元被堆叠到称为Selective Kernel(SKNets)的深度网络中。在ImageNet和CIFAR基准测试中,我们凭经验证明SKNet在模型复杂度较低的情况下优于现有的最先进架构。详细分析表明,SKNet中的神经元可以捕获具有不同尺度的目标物体,从而验证神经元根据输入自适应地调整其感受野尺寸的能力。
1. Introduction
在本文中,我们提出了一种非线性方法来聚合来自多个卷积核的信息,以实现神经元的自适应感受野大小。我们引入了一个“选择性卷积核”(SK)卷积,它由三个操作组成:split,fuse和select。split操作生成具有各种卷积核大小(对应于神经元的不同感受野大小)的多个路径。融合操作组合并聚合来自多个路径的信息,以获得选择性权重的全局和综合表示。select操作根据选择权重聚合不同大小的卷积核的特征映射。
SK卷积可以是计算上轻量级的,并且仅是参数和计算成本的轻微增加。为了证明它们的一般适用性,我们还在较小的数据集CIFAR-10和100上提供了引人注目的结果,并成功地将SK嵌入到小模型中(例如,ShuffleNetV2)。
为了验证所提出的模型是否具有调整神经元感受野尺寸的能力,我们通过在自然图像中放大目标对象并缩小背景以保持图像大小不变来模拟刺激。发现当目标对象变得越来越大时,大多数神经元越来越多地从更大的卷积核路径收集信息。这些结果表明,所提出的SKNet中的神经元可以自适应感受野尺寸,这可能是该模型在物体识别中的优越性能的基础。
2 相关工作
Multi-branch convolutional networks :注意,提出的SKNets遵循InceptionNets的概念,包含多个分支的各种卷积核,但至少有两个重要方面不同:1)SKNets的方案更简单,没有大量的定制设计; 2)多个分支的自适应选择机制用于实现神经元的自适应感受野大小。
基于交错的分组卷积:例如IGCV1 ,IGCV2和IGCV3。卷积的特殊情况是depthwise convolution,其中组的数量等于通道的数量。Xception 和MobileNetV1 引入了深度可分离卷积,它将普通卷积分解为深度卷积和逐点卷积。深度卷积的有效性在随后的工作中得到验证,如MobileNetV2 和ShuffleNet。除了分组/深度卷积之外,扩张的卷积支持感受野的指数扩展而不会损失覆盖范围。例如,具有扩张2的3×3卷积可以近似覆盖5×5滤波器的RF,同时消耗不到一半的计算和存储器。在SK卷积中,较大尺寸(例如,> 1)的卷积核被设计成结合分组/深度/扩张的卷积,以避免繁重的开销。
注意力机制:SENet 带来了一种有效的,轻量级的门机制,可以通过channel-wise的重要性自校准特征图。相比之下,我们提出的SKNets是第一个通过引入注意机制明确地关注神经元的自适应感受野大小。
3方法
3.1. Selective Kernel Convolution
为了使神经元能够自适应地调整其感受野尺寸,我们在具有不同卷积核大小的多个卷积核中提出了自动选择操作SK卷积。具体来说,我们通过三个操作实现SK卷积 - Split,Fuse和Select,如图1所示,其中显示了一个双分支的情况。因此,在此示例中,只有两个卷积核具有不同的卷积核大小,但很容易扩展到多个分支的情况。
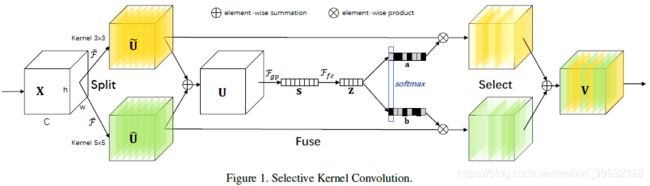
Split:对于任何给定的特征映射 X ∈ R H ′ × W ′ × C ′ X \in {{\rm{R}}^{H' \times W' \times C'}} X∈RH′×W′×C′,默认情况下,我们首先分别进行卷积大小为3和5的两个转换 F ∼ : X → U ∼ ∈ R H × W × C \mathop F\limits^ \sim :X \to \mathop U\limits^ \sim \in {{\rm{R}}^{H \times W \times C}} F∼:X→U∼∈RH×W×C和 F ^ : X → U ^ ∈ R H × W × C \hat F:X \to \hat U \in {{\rm{R}}^{H \times W \times C}} F^:X→U^∈RH×W×C。请注意,$\mathop F\limits^ \sim 和 和 和\hat F$均由高效的分组/深度卷积,批量标准化和ReLU函数组成。为了进一步提高效率,5×5卷积核的常规卷积被替换为3×3卷积核和扩张尺寸为2的扩散卷积。
Fuse: 基本思想是使用门来控制来自多个分支的信息流,这些分支携带不同尺度的信息到下一层的神经元中。为实现这一目标,门需要整合来自所有分支的信息。我们首先通过element-wise summation融合来自多个(图1中的两个)分支的结果:
U = U ~ + U ^ U = \tilde U + \hat U U=U~+U^
Fgp为全局平均池化操作,Ffc为先降维再升维的两层全连接层。需要注意的是输出的两个矩阵a和b,其中矩阵b为冗余矩阵,在如图两个分支的情况下b=1-a。
通过简单地使用全局平均池化以生成channel-wise统计信息 s ∈ R C s \in {{\rm{R}}^C} s∈RC来生成全局信息。具体来说,s的第c个元素是通过空间尺寸 H × W {H \times W} H×W收缩U来计算的:
s c = F g p ( U c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W U c ( i , j ) {s_c} = {F_{gp}}({U_c}) = \frac{1}{{H \times W}}\sum\limits_{i = 1}^H {\sum\limits_{j = 1}^W {{U_c}(i,j)} } sc=Fgp(Uc)=H×W1i=1∑Hj=1∑WUc(i,j)
此外,还创建了一个紧凑的特征 z ∈ R d × 1 z \in {{\rm{R}}^{d \times 1}} z∈Rd×1,以便为精确和自适应选择提供指导。这是通过一个简单的完全连接(fc)层实现的,降低了维度以提高效率:
z = F f c ( s ) = δ ( B ( W s ) ) z = {F_{fc}}(s) = \delta (B(Ws)) z=Ffc(s)=δ(B(Ws))
其中δ是ReLU函数,B表示批量标准化, W ∈ R d × C W \in {{\rm{R}}^{d \times C}} W∈Rd×C。为了研究d对模型效率的影响,我们使用reduction ratio r来控制其值:
d = max ( C / r , L ) d = \max (C/r,L) d=max(C/r,L)
其中L表示d的最小值(L=32是我们实验中的典型设置)
Select:Select操作对应于SE模块中的Scale。区别是Select使用a和b两个权重矩阵对 U ~ \tilde U U~和 U ^ \hat U U^进行加权操作,然后求和得到最终的输出向量V。
跨通道的软关注用于自适应地选择信息的不同空间尺度,空间尺度由紧凑特征描述符z引导。具体而言,softmax运算符应用于channel-wise数字:
a c = e A c z e A c z + e B c z , b c = e B c z e A c z + e B c z {a_c} = \frac{{{e^{{A_c}z}}}}{{{e^{{A_c}z}} + {e^{{B_c}z}}}},{b_c} = \frac{{{e^{{B_c}z}}}}{{{e^{{A_c}z}} + {e^{{B_c}z}}}} ac=eAcz+eBczeAcz,bc=eAcz+eBczeBcz
其中 A , B ∈ R C × d A,B \in {{\rm{R}}^{C \times d}} A,B∈RC×d,a、b表示 U ~ \tilde U U~和 U ^ \hat U U^的soft attention, A c ∈ R 1 × d {A_c} \in {{\rm{R}}^{1 \times d}} Ac∈R1×d是A的第c行, a c {a_c} ac是a的第c个元素。在两个分支的情况下,矩阵B是冗余的,因为 a c + b c = 1 {a_c} + {b_c} = 1 ac+bc=1。最终的特征映射V是通过各种卷积核的注意力权重获得的:
V c = a c ⋅ U ~ c + b c ⋅ U ^ c , a c + b c = 1 {V_c} = {a_c} \cdot {\tilde U_c} + {b_c} \cdot {\hat U_c},{a_c} + {b_c} = 1 Vc=ac⋅U~c+bc⋅U^c,ac+bc=1
其中 V = [ V 1 , V 2 , . . . , V C ] , V c ∈ R H × W V = [{V_1},{V_2},...,{V_C}],{V_c} \in {{\rm{R}}^{H \times W}} V=[V1,V2,...,VC],Vc∈RH×W,注意,这里我们提供了一个双分支情况的公式,并且可以通过扩展轻松推断出具有更多分支的情况。
3.2. Network Architecture

使用SK卷积,表1列出了整体SKNet架构。我们从ResNeXt开始,原因有两个:1)它具有较低的计算成本和广泛使用的分组卷积,以及2)它是具有高性能的对象识别的最先进的网络架构之一。与ResNeXt类似,提出的SKNet主要由一堆重复的瓶颈块组成,称为“SK单位”。每个SK单元由1×1卷积,SK卷积和1×1卷积的序列组成。通常,ResNeXt中原始瓶颈块中的所有大卷积核卷积都被SK卷积所取代,使网络能够以自适应方式选择适当的感受野大小。由于SK卷积在我们的设计中非常有效,与ResNeXt-50相比,SKNet-50只使参数数量增加10%,计算成本增加5%。
在SK单位中,有三个重要的超参数决定了SK卷积的最终设置:确定要聚合的不同卷积核核的选择数量的路径数M,控制每条路径基数的组数G,以及控制fuse 操作中参数数量的reduction ratio r。在表1中,我们将SK convolutions SK 的一个典型设置表示为 S K [ M , G , r ] SK[M,G,r] SK[M,G,r]。
表1显示了50层SKNet的结构,其分别具有{3,4,6,3} SK单元的四个阶段。通过改变每个阶段中SK单元的数量,可以获得不同的体系结构。在这项研究中,我们尝试了其他两种架构,有{2,2,2,2} SK单元的SKNet-26,有{3,4,23,3} SK单元的SKNet-101。
注意,所提出的SK卷积可以应用于其他轻量级网络,例如MobileNet,ShuffleNet,其中广泛使用3×3深度卷积。通过将这些卷积替换为SK卷积,我们还可以在紧凑的架构中实现非常吸引人的结果。
4. Experiments
4.1. ImageNet Classification
Comparisons with state-of-the-art models.
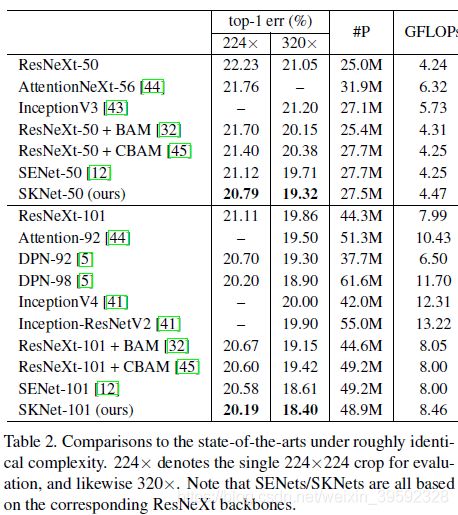
Selective Kernel vs. Depth/Width/Cardinality.
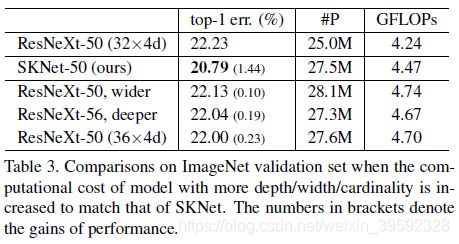
Performance with respect to the number of parameters.
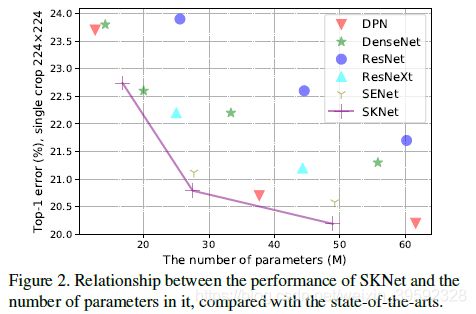
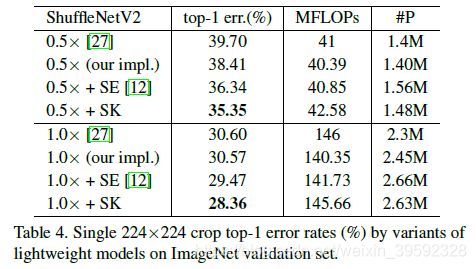
Lightweight models.
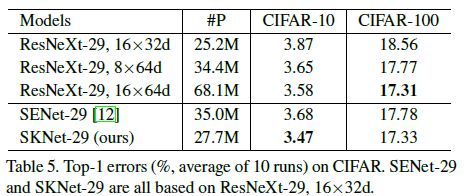
4.2. CIFAR Classification
为了评估SKNets在较小数据集上的性能,我们在CIFAR-10和100上进行了更多的实验。
4.3. Ablation Studies
The dilation D and group number G
扩张D和组数G是控制感受野尺寸的两个关键因素,为了研究它们的影响,我们从双分支情况开始,并在SKNet-50的第一个卷积核分支中设置3×3卷积核,其中扩张D = 1,组G = 32。
在类似整体复杂度的约束下,有两种方法可以放大第二卷积核分支的感受野:1)增加扩张率D同时固定组号G,2)同时增加卷积核大小和组号G.
表6显示了另一个分支的最佳设置是卷积核大小为5×5(最后一列),它大于第一个固定大小为3×3的卷积核。事实证明,使用不同的卷积核大小是有益的,我们将原因归结为多尺度信息的聚合。
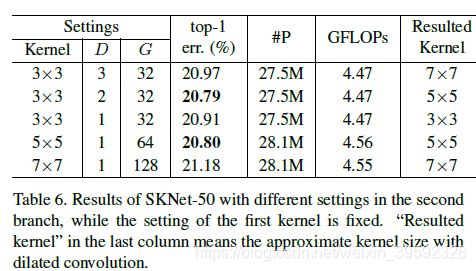
有两种最佳配置:卷积大小为5×5,D = 1,卷积核大小为3×3,D = 2,后者的模型复杂度略低。一般来说,我们根据经验发现,具有各种扩张的3×3卷积核系列在性能和复杂性方面均优于具有相同RF(大卷积核,无扩展)的相应结构。
Combination of different kernels.
接下来我们研究不同内卷积核组合的效果。某些卷积核的大小可能大于3×3,并且可能有两个以上的卷积核。为了限制搜索空间,我们只使用三个不同的卷积核,称为“K3”(标准3×3卷积内核),“K5”(3×3卷积,扩展2到大约5×5卷积核大小)和“K7” (3×3,扩张3,大约7×7核尺寸)。请注意,我们只考虑大型卷积核(5×5和7×7)的扩张版本,如表6所示。 G固定为32.如果勾选表7中的“SK”,则意味着我们在同一行中勾选相应卷积核的SK attention(每个SK单元的输出在图1中为V),否则我们简单地用这些卷积核总结结果(然后每个SK单位的输出在图1中为U)作为一个naive baseline 模型。
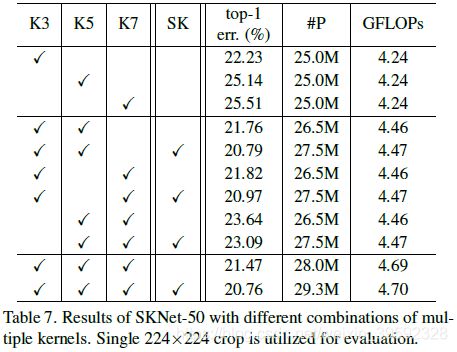
表7中的结果表明,SKNets的优异性能可归因于多卷积的使用及其中的自适应选择机制。从表7中,我们得到以下观察结果:(1)当路径M的数量增加时,通常识别误差减小。表的第一个块中的top-1 error(M = 1)通常高于第二个块中的top-1 error(M = 2),并且第二个块中的错误通常高于第三个块(M = 3) )。 (2)无论M = 2还是3,基于SK注意的多路径聚合总是比简单聚合方法(naive baseline模型)实现更低的top-1 error。 (3)使用SK注意,从M = 2到M = 3的模型的性能增益是marginal(top-1 error从20.79%减少到20.76%)。为了在性能和效率之间进行更好的权衡,M = 2是首选。
4.4. Analysis and Interpretation
为了理解自适应卷积核选择的工作原理,我们通过输入相同的目标对象但在不同的尺度上分析注意力。我们从ImageNet验证集中获取所有图像实例,并通过中心裁剪和随后的大小调整逐步将中心对象从1.0倍扩大到2.0倍(参见图3a,b中的左上角)。
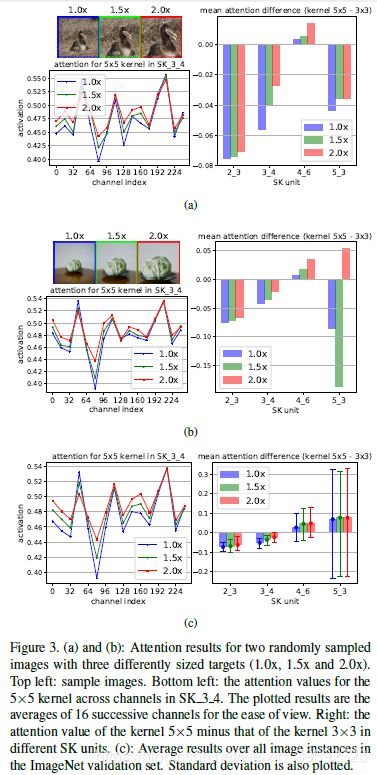
首先,我们计算每个SK单元中每个通道中大卷积核(5×5)的attention value。图3a,b(左下)显示了SK_3_4中两个随机样本的所有通道中的注意值,图3c(左下)显示了所有验证图像中所有通道的平均注意值。可以看出,在大多数通道中,当目标物体扩大时,大卷积核(5×5)的注意力增加,这表明神经元的RF尺寸自适应地变大,这与我们的预期一致。
然后,我们计算每个SK单元中所有通道上与两个卷积核相关的平均注意力之间的差异(较大减去较小)。图3a,b(右)显示了不同SK单位的两个随机样本的结果,图3c(右)显示了所有验证图像的平均结果。我们找到了一个令人惊讶的模式关于通过深度自适应选择:目标对象越大,在中低阶段(例如,SK_2_3,SK_3_4)中选择性kernel机制将更多的注意力分配给更大的内核。然而,在更高层(例如,SK_5_3),所有比例信息都会丢失并且这种模式也消失。
此外,我们从类的角度深入研究选择分布。对于每个类别,我们在属于该类别的所有50个图像上绘制1.0×和1.5×对象的代表性SK单元的平均平均注意力差异。我们在图4中提供了1,000个类别的统计数据。我们观察到之前的模式适用于所有1,000个类别,如图4所示,其中卷积核5×5的重要性在目标大小增长时始终如一地同时增加。这表明在网络的早期部分,可以根据对象大小的语义感知来选择合适的卷积核大小,从而有效地调整这些神经元的RF大小。然而,这种模式不存在于像SK_5_3那样的非常高的层中,因为对于高级表示,“scale”部分地编码在特征向量中,并且与较低层中的情况相比,卷积核大小更少。
5 Conclusion
受视觉皮层中神经元的自适应感受野(RF)大小的启发,我们提出了具有新颖选择性卷积核(SK)卷积的SKNets,以通过软注意力中的自适应核选择来提高对象识别的效率和有效性。 SKNets在各种基准测试中展示了最先进的性能,从大模型到小模型。此外,我们还发现了跨通道,深度和类别的卷积核核选择的几个有意义的行为,并且经验验证了SKNets的RF尺寸的有效适应,这使得更好地理解其机制。