Linux03: shell编程
1. 几个概念
1.1 shell中的变量
(1)shell中变量的命名要求: 只能使用数字、字母和下划线,且不能以数字开头
(2)变量赋值是通过"="进行赋值,在变量、等号和值之间不能出现空格!

1.2 打印变量的值
(1)完整写法: echo $name
(2)简化写法: echo ${name}

二者有什么区别:
如果我们想在变量的结果后面直接无缝拼接其它字符串,那就只能使用带花括号的形式

如果带空格的话就无所谓了

1.3 变量的分类
1、 本地变量
2、 环境变量
3、 位置变量
4、 特殊变量
1.3. 1本地变量
本地变量的格式是VAR_NAME=VALUE,其实就是我们刚才在shell中那样直接定义的变量,这种变量一 般用于在shell脚本中定义一些临时变量,只对当前shell进程有效,关闭shell进程之后就消失了,对当前 shell进程的子进程和其它shell进程无效, 注意了,我们在这开启一个shell的命令行窗口其实就是开启了一个shell进程 克隆一个会话, 在这两个shell进程中执行echo $name 会发现在克隆的shell进程中获取不到name的值,表示本地变量对 其它shell进程无效
1.3.2 环境变量

使配置生效
source /etc/profile
1.3.3 位置变量
在进行shell编程的时候,有时候我们想给shell脚本动态的传递一些参数,这个时候就需要用到位置变 量,类似于 $0 $1 $2 这样的,$后面的数字理论上没有什么限制, 它的格式是: location.sh abc xyz

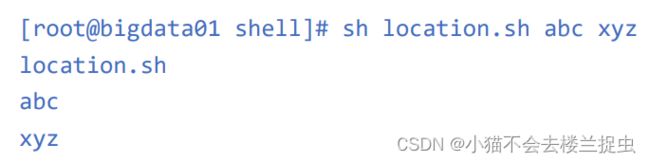 结果发现 :
结果发现 :
$0的值是这个脚本的名称
$1 是脚本后面的第一个参数
$2 是脚本后面的第二个参数
$3 为空,是因为脚本后面就只有两个参数
理论上来说,脚本后面有多少个参数,在脚本中就可以通过$和角标获取对应参数的值。 多个参数中间使用空格分隔。
1.3.4 特殊变量
(1)$? :它表示是上一条命令的返回状态码,状态码在0~255之间。如果命令执行成功,这个返回状态码是0,如果失败,则是在1~255之间,不同的状态码代表着不同的错 误信息,也就是说,正确的道路只有一条,失败的道路有很多。

这里的127状态码表示是没有找到命令。 具体的状态码信息也可以在网上查到,搜索【linux $? 状态码】
这个状态码在工作中的应用场景是这样的,我们有时候会根据上一条命令的执行结果来执行后面不同的业 务逻辑
(2)$# : 它表示的是shell脚本所有参数的个数


这个特殊变量的应用场景是这样的,假设我们的脚本在运行的时候需要从外面动态获取三个参数,那么在 执行脚本之前就需要先判断一下脚本后面有没有指定三个参数,如果就指定了1个参数,那这个脚本就没 有必要执行了,直接停止就可以了,参数个数都不够,执行是没有意义的。
1.4 变量和引号的特殊使用
1. 单引号'' : 不解析变量
2. 双引号"" : 解析变量
3. 反引号`` : 执行并引用命令的执行结果,等价于$() , 具体使用哪个就看你喜欢哪个
1. 单引号

2. 双引号

3. 单引号

在变量的值外面套一层引号

使用场景:什么时候需要在结果里面带引号呢?在后面课程中我们在脚本中动态拼接sql的时候会用到。
2. shell中的循环和判断
2.1 for循环
2.1.1 第一种格式for循环

实例:

注意了,这里的do也可以和for写在一行,只是需要加一个分号;

2.1.2 第二种格式for循环

2.2 while 循环
2.2.1 测试条件
- while 循环格式

注意这里面的测试条件,测试条件为"真",则进入循环,测试条件为"假",则退出循环
- 测试条件
那这个测试条件该如何定义呢? 它支持两种格式
(1)test EXPR
(2)[ EXPR ]
第二种形式里面中括号和表达式之间的空格不能少
1. 整型测试:
-gt(大于)、-lt(小于)、-ge(大于等于)、-le(小于等于)、-eq(等于)、-ne(不等于)
2.字符串测试
=(等于)、!=(不等于)
2.2.2 for循环实例

其实我是不太喜欢这里面测试条件的格式,我喜欢使用中括号这种,看起来比较清晰 只是这种一定要注意,中括号和里面的表达式之间一定要有空格,否则就报错

2.3 if 判断
f判断分为三种形式
• 单分支
• 双分支
• 多分支
2.3.1 if 单分支
格式

注意:这里面也用到了测试条件,所以和while中的一致

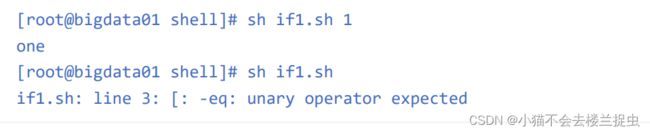
在这里发现,如果脚本后面没有传参数的话,执行程序会抱错,错误信息看起来也不优雅,这说明我们的 程序不够健壮,所以可以进行优化 先判断脚本后面参数的个数,如果参数个数不够,直接退出就行,在这里使用exit可以退出程序,并且可 以在程序后面返回一个状态码,这个状态码其实就是我们之前使用$?获取到的状态码,如果这个程序不 传任何参数,就会执行exit 100,结束程序,并且返回状态码100,我们来验证一下


2.3.2 if 双分支
- 双分支格式

- 实例

2.3.3 if 多分支
- 多分支格式


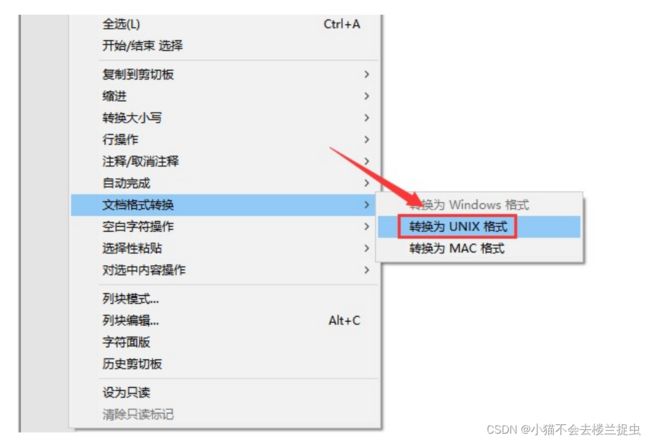
注意:如果在windows中使用notepad++开发shell脚本,需要将此参数设置为UNIX。 否则在windows中开发的脚本直接上传到linux中执行会报错。
3. shell扩展
3.1 后台运行程序
(1)前台运行程序: sh while2.sh , 会一直占用shell窗口
(2)后台运行程序1 : sh while2.sh & , 关闭shell窗口,后台的shell脚本也停止了。
(3)后台运行程序2: nohup sh while2.sh & , 会一直在后台运行。原理就是,默认情况下,当我们关闭shell窗口时,shell窗口会向之前通过它启动的所有shell 脚本发送停止信号,当我们加上nohup之后,就会阻断这个停止信号的发送,所以已经放到后台的shell脚 本就不会停止了。
注意:使用nohup之后,脚本输出的信息默认都会存储到当前目录下的一个nohup.out日志文件中,后期 想要排查脚本的执行情况的话就可以看这个日志文件。
3.2 标准输出、标准错误输出、重定向
1、标准输出:表示是命令或者程序输出的正常信息, 可以用文件描述符1来表示。
2、标准错误输出:表示是命令或者程序输出的错误信息, 可以用文件描述符2来表示。
3、重定向:针对标准输出和标准错误输出,可以使用重定向操作将这些输出信息保存到文件中 演示一下重定向 > , 追加使用 >>
- 标准输出和标准错误输出

这里的ll执行成功了,所以下面输出的信息就是标准输出 这里的lk是一个不存在的命令,执行失败了,所以下面输出的信息就是标准错误输出。
- 将标准输出重定向到文件中
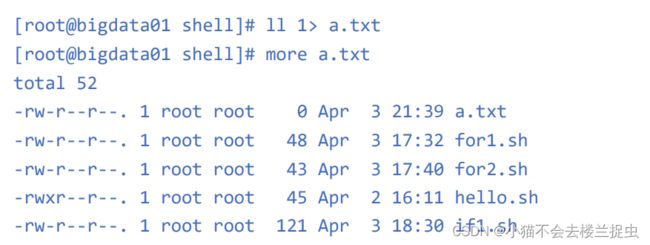
注意,这里的1可以省略,因为默认情况下不写也是1
- 将标准错误输出重定向到文件中

- 综合案例
nohup hello.sh >/dev/null 2>&1 &说明:
(1)nohup和&:可以让程序一直在后台运行
(2)/dev/null:是linux中的黑洞,任何数据扔进去都找不到了 。>/dev/null:把标准输出重定向到黑洞中,表示脚本的输出信息不需要存储
(3)2>&1 :表示是把标准错误输出重定向到标准输出中
3.3 linux中的定时器crontab
crontab在使用的是也很简答,只需要配置一条命令即可,连代码都不需要写,这可比java中的timer要方 便多了
crontab的格式是这样的: * * * * * user-name command
*:分钟(0-59)
*:小时(0-23)
*:一个月中的第几天(1-31)
*:月份(1-12)
*:星期几(0-6) (星期天为0)
user-name:用户名,用哪个用户执行
command:具体需要指定的命令这条配置需要添加到crontab服务对应的文件中,在配置之前,需要先确认crontab的服务是否正常 查看crontab服务状态:systemctl status crond
看到里面的active说明这个服务是启动的,如果服务没有启动可以使用systemctl start crond 来启动,如 果想要停止 可以使用systemctl stop crond
- 每1分钟执行一次
* * * * * root sh /root/shell/showTime.sh >> /root/shell/showTime.log- 每7分钟执行一次
*/7 * * * * root sh /root/shell/showTime.sh >> /root/shell/showTime.log注意了:
(1)crontab中任务是这样执行的,我们这里设置的7分钟执行一次,那么就会在每个小时的第0、7、 14、21、28…分钟执行,而不是根据你配置好的时候往后推,这个一定要注意了
(2)还有就是这里的间隔时间是7分钟,7分钟无法被60整除,那执行到这个小时的最后一次以后会怎么办 呢?它最后会在第56分钟执行一次,再往后的话继续往后面顺延7分钟吗?不是的,下一次执行就是下一 个小时的0分开始执行了,所以针对这种除不尽的到下一小时就开始重新计算了,不累计。