【SFFAI分享】郑武:CIA-SSD:自信的IoU可知的单阶点云物体检测器【附PPT与视频资料】

随着激光雷达在机器人,无人车的领域的推广应用,三维点云的相关处理技术作为高精地图、高精定位、环境检测等方向的核心模块越来越受到重视。现有的在点云中定位物体的单阶段检测器通常将物体定位和类别分类视为分开的任务,因此定位精度和分类置信度可能无法很好地对齐。《SFFAI97期三维点云检测专题》我们邀请到了来自香港中文大学的郑武同学,分享他提出的新型检测方法,解决此问题。
关注微信公众号:人工智能前沿讲习
对话框回复"SFFAI97"
入交流群/推荐论文下载/录播视频观看/讲者PPT下载

郑武 香港中文大学二年级博士研究生,本科毕业于清华大学自动化系,主要研究方向是自动驾驶场景下基于点云的三维物体检测。
很高兴在这里和大家分享一下我们最新的工作:CIA-SSD,自信的IoU可知的单阶点云物体检测器,这份工作已经被AAAI 2021接收。这份工作是我和两位本科实习生Weiliang Tang & Sijin Chen,我的师姐Li Jiang,在Chi-WingFu教授的指导下完成的。
论文:https://arxiv.org/abs/2012.03015
代码:https://github.com/Vegeta2020/CIA-SSD
今天的报告主要分为5个部分,分别是背景介绍,研究动机,研究方法,实验结果,以及最后总结。
01、背景介绍
我们这份工作要完成的任务是自动驾驶场景下基于点云的三维物体检测。三维物体检测能够为自动驾驶的车辆提供最基本也是最重要的环境感知信息,包括行驶道路中的其他车辆和人员的相对位置,这可以为车辆行驶的规划和控制提供关键信息,从而确保自身和他人的安全。在图1右边的图片中,我们给出了三维物体检测的样例,大家可以看到RGB图片中的车辆都被三维矩形框精确地框出来,所以获得物体的三维坐标,长宽高和水平面的旋转角,就是我们要完成的三维检测任务。

图 1
目前,三维物体检测仍然是一个具有挑战性的任务。首先体现在检测精度仍然有待提升,目前精度最高的一类方法主要是基于点云的检测器,我们的CIA-SSD也是采用的点云作为输入数据。相比于RGB图片作为感知数据,点云往往更加鲁棒,特别是在雾天或者夜晚,点云依然能够提供精确地物体三维坐标,而RGB图片在这些情形中则很难通过像素确定物体位置。另外,点云的特性使得研究者可以快速地获取物体深度信息,这对于RGB图片来说则是一个难题。所以,相比于基于RGB图片的检测器,采用点云的检测器往往能够获得更高的精度。
我们在图2中对近两年的三维检测器的性能进行了比较。正如二维检测器一样,三维检测器也可以分为单阶和二阶检测器,区别主要在于是否利用第一阶网络生成的region proposal来提取特征,从而对物体的位置和置信度做进一步的refine。
从图2中,大家可以看到,2019年的时候,精度最高的二阶检测器STD大幅领先于当时性能最好的单阶检测器PointPillar。但是进入到2020年,以SA-SSD和3DSSD为代表的单阶检测器在精度上获得大幅提升,并且逐渐逼近了二阶检测器,包括目前最优的二阶检测器PV-RCNN, 3D-CVF,所以单阶和二阶检测器的精度差距在逐渐缩小。
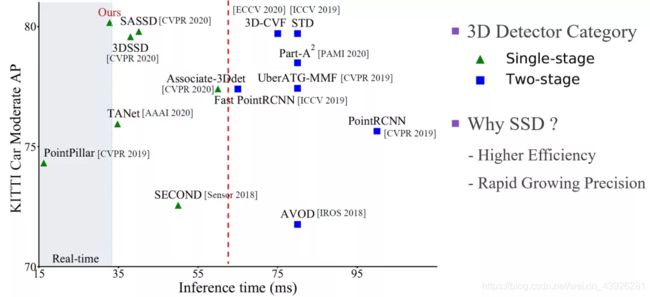
图 2
与此同时,检测速度和精度一样,也是三维检测器的重要衡量指标,因为速度决定了检测器是否能够应用到实际场景中去。由于单阶检测器往往具备更加简单的网络结构,所以它的检测速度往往更高,正如图2中所示,红线左侧都是单阶检测器,右侧都是二阶检测器,所以单阶检测器的推理时间往往更短。
所以,高效率和快速增长的精度这两个优势,驱使我们提出了一个新的单阶检测器CIA-SSD,可以看到,我们的CIA-SSD位于图2的左上角,它在单阶检测器中具备有最高的精度,同时具备有实时检测的速度。
02、研究动机
我们的主要动机是基于检测任务中的一个普遍挑战,即分类置信度和定位精度之间的不对齐问题,或者直接说置信度与real IoU间的不对齐问题,这里的real IoU是指网络预测和真实边界框的IoU。最理想的对齐情形是指confidence和realIoU完全成正比,我们曾经做过一个简单的实验,就是把real IoU作为confidence去测averageprecision,我们发现在KITTI验证集上可以达到90%以上的精度,所以bounding box回归不够准确并不一定是性能无法提升的主要障碍。相反,这个主要障碍是置信度和real IoU之间的不对齐。
图3中展示了一个不对齐的样例,我在每个预测的bounding box旁边给出了confidence和realIoU, 可以看到两个红色框的样本,置信度更高的为0.94的预测样本反而real IoU更低,只有0.81,这就说明了不对齐问题。在图3右边的图中,我们给出了验证集中预测框的IoU和confidence的统计散点图,可以看出,有大量的样本是不对齐的。
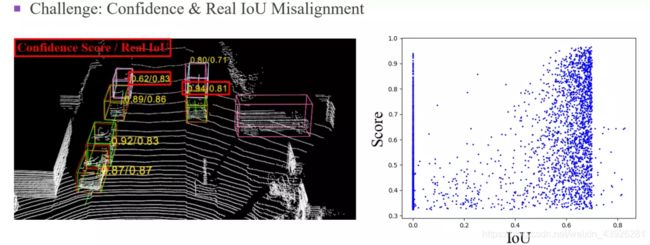
图 3
为了缓解这个不对齐问题,我们提出了IoU可知的置信度校正模块。我们通过利用单阶检测器来预测真实框和预测框之间的IoU,然后用这个预测的IoU来校正已有的分类得分,从而缓解不对齐问题。一般来说,由于软的IoU目标相比于one-hot的分类目标,能够促使网络预测出和定位精度更加一致的置信度,所以用预测的IoU作为置信度成为二阶检测器提升性能的一个重要方法。在二阶检测器中,它们通过提取region proposal的特征,可以预测到非常准确的IoU来作为置信度。但是单阶检测器的特征都是和anchor对齐的,所以很难得到准确的IoU预测值。尽管如此,我们发现基于anchor特征预测的IoU依然是和Real IoU大致成正比的,当我们用一个幂函数对预测IoU进行编码后,这种相关性得到了进一步加强,这个发现为我们在单阶检测器中校正置信度创造了可能性。
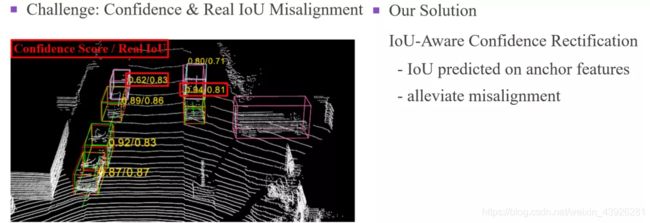
图 4
除此之外,我们还提出了一个轻量的空间语义特征聚合模块。之前的方法中,BEV的特征提取往往都是采用几层直接叠加的卷积层,我们认为这种网络结构虽然可以提取到较好的高层语义特征,但是容易忽略掉浅层的空间特征,导致检测精度无法有效提升。我们知道,空间特征对于精确地定位物体很重要,高层语义特征则对于判断样本的正负性比较重要。因此,我们采用浅层卷积层获取空间特征,再采用高层卷积层获取语义特征,最后则采用attention模块对这两类特征进行融合,从而有效提升检测精度。

图 5
最后,我们提出了距离可变的IoU加权NMS用于后处理,据我们所知,这是第一个考虑深度信息的NMS方法,因为2D检测中是不需要考虑深度信息的,我们提出这个NMS方法,是为了获取更加平滑的回归边界框,并且更有效得移除冗余的边界框,特别是false positive的边界框。
03、研究方法
图6是我们CIA-SSD的pipeline,可以看出,整个框架由5个部分组成,其中part ©-(e)是我们设计的部分。下面我对每个部分分别进行介绍。
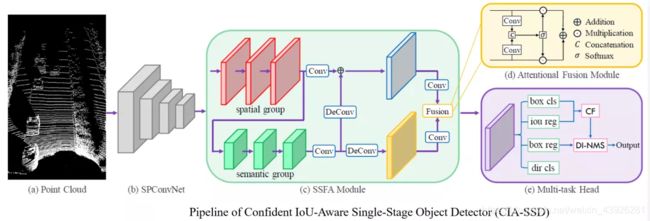
图 6
其中,对于part (a) ,我们遵循常规的设置对点云数据进行预处理,主要包括一些常用的数据增强方法;对于part(b), 我们则采用稀疏卷积层来提取体素的三维特征,具体网络结构可以参考我们的论文。

图 7
接下来我将介绍part©和(d),也就是我们的空间语义特征聚合模块。正如之前所介绍的,在物体检测中,低级空间特征对于回归物体的精确位置很重要,而高级语义特征对于对正样本/负样本的准确分类很重要。因此,在part©中,我们采用两个卷积组,即浅层的空间卷积组(红色标记的)和深层的语义卷积组(绿色标记的)分别来提取这两种特征,其中语义卷积组的特征channel增加为空间卷积组的2倍,但是spatial size则缩小了1/4,这样做的好处是,一方面有利于提取更加抽象的语义特征,另一方面可以降低卷积的计算量。
此后,为了将两种特征进行融合,我们首先用解卷积来恢复语义特征的spatial size, 并和空间特征做逐像素相加,从而丰富空间特征的语义信息,得到了富语义的空间特征(蓝色标记的)。我们同时用另外一层解卷积来恢复语义特征的spatial size,得到放大的语义特征(黄色标记的)。
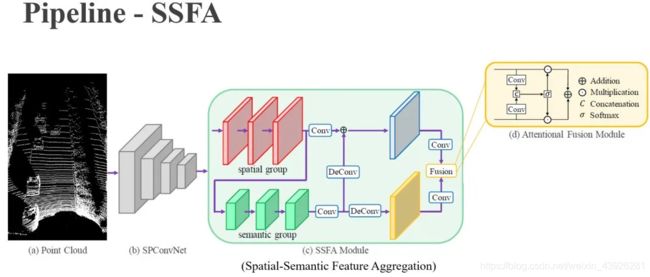
图 8
最后,我们在part(d)中采用attentional fusion来自适应地融合(蓝色的)富语义空间特征和(黄色的)放大的语义特征。我们首先用卷积层分别计算了两个特征的attention mask,这两个卷积层的卷积核是1x1,输出的channel是1,所以可以理解为两个全连接层,它们的计算量也很小。然后,我们对这两个attention mask在每个位置做softmax,从而得到featuremap的两组权重, 这两组权重在每个位置的和都是1。最后我们将这两组权重分别和对应的特征做加权,再将加权的特征逐像素相加,得到最后的BEV特征。
我们说这个空间语义聚合模块是轻量的,是因为相比于SA-SSD的BEV网络结构,计算量大概是60%,虽然我们的卷积层更多,但是绝大部分的channel数量128,而SA-SSD的channel数量都是256,我们只有语义卷积层的channel是256,但是它的spatialsize是SA-SSD的1/4,所以总的计算量只占6成左右。另外,即使相比于SECOND中channel只有128的BEV网络结构,我们增加的复杂度也是很少的。
最后,我想说的是的SSFA模块所提取的BEV特征是非常鲁棒的,对于提升BEV检测性能和小物体检测效果都是明显的,这是论文中没有体现的,所以我在这里补充一下。
Part(e)是一个多任务检测头,它包括有bounding box的正负性分类,bounding box的IoU回归,boundingbox自身的回归,以及bounding box方向的分类。相比于常规的检测器,我们在这里仅仅增加了bounding box的IoU回归。基于这个预测的IoU,我们设计了一个置信度函数来校正分类得分。而基于校正后的置信度,我们进一步设计了DI-NMS来对预测的bounding box进行后处理。接下来,我们将分别介绍置信度校正模块和DI-NMS模块。
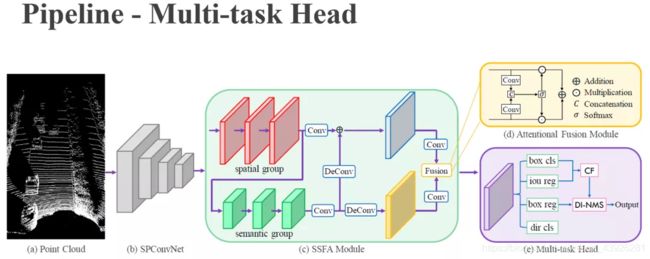
图 9
我们的置信度校正模块称为IoU可知的置信度校正模块。首先,我们对单阶检测器在KITTI验证集上所预测的IoU进行了统计分析,从图10(a)中可以看到,预测的IoU和真实的IoU并不完全匹配,而且当real IoU偏低时,它所对应的预测IoU具有较大的标准差,也就是说它有一个较大的震荡区间,这种现象是容易解释的,比如,当anchor特征能够生成一个非常精准的预测框时,那么它应该包含了足够的位置信息,因而所预测的IoU应该较大并且震荡很小;相反,如果anchor远离检测目标,那么它很难包含充分的物体位置信息,从而容易生成较低的预测IoU,并且这种预测是不准确的,因而容易有较大偏差。
尽管如此,我们还是可以看到real IoU和真实的IoU依然是大致成正比的。为了抑制低IoU预测值的震荡,并增加高IoU和低IoU预测值之间的差距,我们用幂函数对预测的IoU进行编码。正如图10(b)所示,当我们求取预测IoU的四次方时,低IoU预测值的震荡区间变小,并且高IoU和低IoU预测值之间的差距则增大,使得预测IoU和真实IoU之间的相关新更强了。

图 10
当我们直接使用预测IoU或者它的幂函数作为置信度时,相比于采用分类得分作为置信度,精度并不能提升。为了利用预测IoU和真实IoU之间的相关性,我们用预测IoU来校正分类得分:即将预测IoU的多次方和分类得分相乘,来获得校正后的置信度。所以,我们的IoU可知的校正模块实际上就是一个简单的校正函数,称为置信度函数。其中c是分类得分,i是预测的IoU,常数beta是一个超参数。需要注意的是,有一种质疑是我们的校正模块和Focal Loss很像,在这里我们需要澄清,我们的置信度校正只是一个后处理技术,只在测试时使用,并不参与网络训练,并且二者的motivation也完全不同。
最后,我在这里给出不同beta值下的moderate AP和真实IoU与校正后的置信度间的皮尔森相关系数。可以看到,当beta值设为4的时候,皮尔森相关系数达到峰值,对应的精度也达到峰值,证明了我们这个模块的有效性。
总的来说,我们的校正模块非常易于实现,只是在多任务头中添加了一个卷积层来预测IoU,在测试时也只需要做一个乘法和幂函数计算,相比于SA-SSD中的PSWarp校正模块,我们的方法明显是更加简单并且易于实现的。
在我们完成置信度校正后,我们又设计了可变距的IoU加权NMS对预测框进行后处理。我们观察到,近距离的预测框通常比较准确,因为点云非常密集,能够提供非常充分的物体位置信息;而远处的预测框则容易出现偏差,因为点云非常稀疏,特别是在预测框的方向上,容易出现左右摇摆。所以距离是一个影响预测结果的重要因素,因此,为了获得更加平滑的预测框,我们将距离因素sigma考虑进了我们的NMS方法。在我们算法的第8步中,我们设定sigma和物体离原点距离是成正比的,所以,在我们的高斯加权平均中,我们首先选出置信度最高的预测框,在这个预测框离原点较近时,那些同它具有较大IoU的其他预测框将会分配明显较高的权重,这是因为近距离情形下的预测框相对更加准确,所以我们应该给与他们更高的权重;相反,当这个置信度最高的预测框离原点较远时,与之具有不同IoU的其他预测框都会分配相对均匀的权重,因为远距离预测框精度不高,通过这种相对均匀加权有利于获得平滑的结果,特别是对那些方向上出现左右摇摆的预测框非常有效。

图 11
此外,我们还观察到,有一些anchor被错误的激活了,去回归一些与车辆具有相似特征的物体,比如墙壁、花坛等等,因为它们可能具备和汽车相似的棱角和高度特征。但是这些物体和真实的检测目标仍然是有差距的,所以被错误激活的anchor数量通常比较少,因此我们在第7步中求取了一个累加和,在第10步中,我们用一个简单的阈值进行过滤,这种方法就有效的过滤掉了一部分false positives。
这就是我们DI-NMS方法的两个考虑因素和设计方法,在3D NMS领域,我们提出的DI-NMS应该是对3D NMS方法改进的第一次尝试。
我们这里还给出了一个效果说明图,图12原本是比较CIA-SSD和SA-SSD的检测效果,但是也能用来说明我们DI-NMS的效果。第一张图是RGB的正视图,第二张和第三张分别是SA-SSD和CIA-SSD点云检测的侧视图,一方面我们可以看到左边的三个检测框,由于DI-NMS可以获得更加平滑的结果,所以我们所预测的绿色检测框能够和真实的红色框更好的对齐;另一方面,DI-NMS能够有效抑制远距离的False Positive,所以SA-SSD误检到的最右端的绿色检测框,我们的CIA-SSD有效的过滤掉了。

图 12
04、实验结果
我们的实验主要是在KITTI数据集汽车类别上进行的。KITTI数据集是自动驾驶领域三维物体检测的经典数据集,目前它的检测精度仍然有较大的提升空间;汽车类别是KITTI中最重要的检测类别,也是样本数量最大的类别,所以在汽车类别上的检测精度是评估模型的关键尺度。
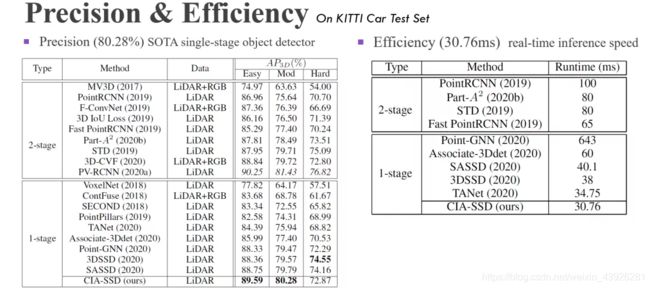
图 13
我们首先给出了在KITTI测试集上汽车类别的Easy/Moderate/HardAP,其中ModerateAP是所有方法的排名尺度。从这张表中,可以看到我们的CIA-SSD成为了state-of-the-art的单阶检测器,它领先于之前的SA-SSD接近0.5个点,并且也超越了除PV-RCNN之外的所有二阶检测器。
除了精度,我们的检测速度也得到了提升。例如,相比于之前精度最高的单阶检测器SA-SSD,我们的推理时间下降了1/4;而相比于之前速度最高的单阶检测器TANet,我们的CIA-SSD仍然更快,并且精度更高。和二阶检测器相比,我们的推理时间至少减少了1/2,并且精度超越了绝大部分的二阶检测器。
这里我们给出了最新的单阶检测器的精度和推理速度的散点图。可以看到,我们的CIA-SSD位于图14的左上方,意味着它同时具备有更高的精度和速度。从速度上来看,仅有CIA-SSD和PointPillar达到了实时检测的速度,也就是超过了30 FPS的阈值。我们的CIA-SSD在速度上仅次于PointPillar,但是在精度上却大幅领先。所以,总的来说,CIA-SSD具备有更高的实用价值。
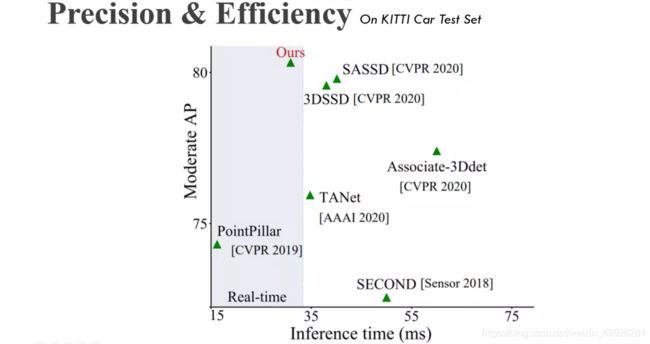
图 14
下面,我们对运行时间做进一步分析。CIA-SSD的运行时间30.76ms,是通过计算模型在整个验证集上运行的总时间,再除以验证集样本数,从而得到单个样本的推理时间。这个单样本的推理时间,包括2.84ms的数据预处理时间,24.33ms的网络推理时间,以及3.59ms的后处理时间。数据预处理时间指的是数据传进网络之前的时间,包括载入数据,数据增强,体素化等等;网络推理时间是指从读入数据到多任务检测头输出结果所耗费的时间;后处理是指从拿到多任务检测头的输出,到产生最终的结果所耗费的时间。

图 15
尽管CIA-SSD和SA-SSD都是建立在SECOND网络基础上,但是CIA-SSD的运行时间相比SA-SSD下降了约1/4。一方面是因为我们的BEV网络,也就是空间语义特征聚合模块复杂度更低;另一方面是因为,我们对代码进行了很多优化,其中效果最明显的地方在于体素化这一部分。
接下来我们介绍消融学习的结果。我们的CIA-SSD主要由3个模块构成,分别是SSFA,CF,和DI-NMS,从表中可以看到,三个模块对精度的增长都有所贡献,证明了三个模块都是非常有效的,特别是其中CF模块,也就是置信度校正,方法非常简单,但是对性能的提升非常明显,所以证明了我们的研究动机和研究方法都是得当的。然后,我们所提出的三个模块都是即插即用的,并且易于实现,所以很容易嵌入到其他框架中,具有较高的可拓展性。
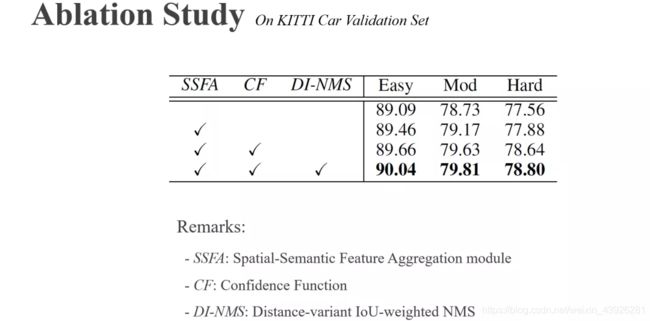
图 16
这里我们给出了一些可视化的检测结果(见图17),一共包括6个场景,每个场景中的红色框是ground truth, 绿色框是CIA-SSD的检测结果。从这些结果中可以看到,我们的CIA-SSD对于近点、远点、不同旋转角和不同物体密度的情形下,都成得到较高的检测精度。

图 17
05、总结
总的来说,我们这份工作的贡献可以分为三点,第一,是我们提出了一种IoU可知的置信度校正模块,这个模块非常高效并易于实现,可以有效提升单阶检测器的精度;第二,我们提出了空间语义特征聚合模块,这是一个轻量的BEV特征提取模块,可以提取鲁棒的BEV特征,提升检测器精度;第三,我们提出了可变距离的IoU加权NMS方法用于后处理,可以获得更加平滑的预测框,并减少False Positive的数量。
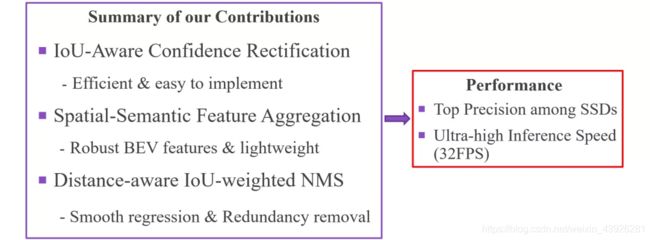
图 18
基于这三点,我们的CIA-SSD在三维单阶点云检测器中获得了最高的精度,并且取得了非常高的推理速度。
