ONNX 加速模型推理
1.安装onnx
pip install onnx onnxruntime
2. 加载模型并转存模型为onnx格式,并测试
使用实例为sentence-transformers 预训练模型计算相似度
class Test(object):
def init(self):
# 加载预训练模型
self.tokenizer = AutoTokenizer.from_pretrained("../all-MiniLM-L6-v2")
self.model = AutoModel.from_pretrained("../all-MiniLM-L6-v2")
# 模型设置为推理状态
self.model.eval()
# 转化成onnx模型
self.onnxmodel = self.transfer_onnx(self.model)
def transfer_onnx(self, model):
#随机创建输入数据。因为模型的导出实际上是执行了一次推理过程。在执行的过程中记录使用到的操作。
# 输入数据可拷贝至gpu,在cpu上直接写None就可
inputs = {
'input_ids':
torch.randint(32, [2, 32], dtype=torch.long).to(
None),
'attention_mask':
torch.ones([2, 32],
dtype=torch.long).to(None),
'token_type_ids':
torch.ones([2, 32],
dtype=torch.long).to(None),
}
# 转换后模型存储地址
onnx_model_path = "./temp_turbo_onnx.model"
# 开始转换
with open(onnx_model_path, 'wb') as outf:
torch.onnx.export(
# 原始模型
model=model,
# 输入参数
args=(inputs['input_ids'], inputs['attention_mask'],
inputs['token_type_ids']
),
# 模型输出文件
f=outf,
# 输入参数名
input_names=[
'input_ids', 'attention_mask', 'token_type_ids'
],
# onnx版本
opset_version=11,
# 输出参数名
output_names=['output'],
#dynamic_axes的参数
#是一个字典类型,字典的key就是输入或者输出的名字,
#对应key的value可以是一个字典或者列表,指定了输入或者输出的index以及对应的名字。
#比如想要让输入的index为0的维度表示动态的batch_size那么就指定{0: 'batch_size'}。
#同样的方法可以指定宽高所在的维度输出成动态的。
dynamic_axes={
'input_ids': {0 : 'batch_size', 1: "input_len"},
'attention_mask': {0 : 'batch_size', 1: "input_len"},
'token_type_ids': {0 : 'batch_size', 1: "input_len"}
}
#index也可不指定名称,例如:
#dynamic_axes={
# 'input_ids':[0, 1],
# 'attention_mask': [0, 1],
# 'token_type_ids': [0, 1]
}
)
# 加载存储好的onnx格式模型
onnx_model = onnx.load_model(f=onnx_model_path)
onnx_model = onnxruntime.backend.prepare(
model=onnx_model,
device='CPU',
graph_optimization_level=onnxruntime.GraphOptimizationLevel.
ORT_ENABLE_ALL)
return onnx_model
# 使用onnx模型进行预测
def onnx_model_call(self,inputs,
attention_masks= None,
token_type_ids= None,
position_ids=None):
if attention_masks is None:
attention_masks = np.ones(inputs.size(), dtype=np.int64)
else:
attention_masks = attention_masks.cpu().numpy()
if token_type_ids is None:
token_type_ids = np.zeros(inputs.size(), dtype=np.int64)
else:
token_type_ids = token_type_ids.cpu().numpy()
data = [inputs.cpu().numpy(), attention_masks, token_type_ids]
outputs = self.onnxmodel.run(inputs=data)
for idx, item in enumerate(outputs):
outputs[idx] = torch.tensor(item, device='cpu')
return outputs
# sentence-transformer模型需要的计算函数 (自己的模型可不要这部分)
def mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
# 计算相似度测试
def calculate_similarity_by_transformer(self, texts):
# 原始模型的编码
t1 = time.time()
encoded_input = self.tokenizer(texts, padding=True, truncation=True, max_length=128, return_tensors='pt')
embeddings1 = self.model(**encoded_input)
sentence_embeddings = self.mean_pooling(embeddings1, encoded_input['attention_mask'])
t2 = time.time()
print('sentence encoder time==',t2-t1)
# onnx模型编码
t3 = time.time()
encoded_input = self.tokenizer(texts, padding=True, truncation=True, max_length=128, return_tensors='pt')
embeddings2 = self.onnx_model_call(encoded_input['input_ids'], token_type_ids=encoded_input['token_type_ids'],
attention_masks=encoded_input['attention_mask'])
sentence_embeddings2 = self.mean_pooling(embeddings2, encoded_input['attention_mask'])
t4 = time.time()
print('onnx encoder time==', t4 - t3)
# 原始模型编码后计算相似度
cos_sim1 = util.cos_sim(embeddings, embeddings)
print('cos1===',cos_sim1[0])
# onnx 模型编码后计算相似度
cos_sim = util.cos_sim(sentence_embeddings2, sentence_embeddings2)
print('cos2===',cos_sim[0])
3. 测试结果
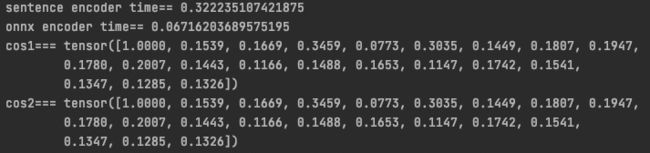
结果一致,速度在cpu上有几倍的提升(gpu上待测试)
参考链接
torch.onnx — PyTorch master documentation