torchvision工具包之torchvision.datasets以及torch.utils.DataLoader的使用
一、torchvision工具包(计算机视觉工具包)中包含3个主要模块:
1.torchvision.datasets:常用的数据集的dataset实现。
2.torchvision.transforms:常用的图像处理方法。
3.torchvision.model:常用的模型预训练。
torchvision.datasets包含的数据集有:MINIST、COCO、CIFAR10 and CIFAR100、LSUN Classification、ImageFolder、Imagenet-12、STL10。
torchvision.datasets中所有封装的数据集都是torch.utils.data.Dataset的子类,它们都实现了__getitem__ 和 __len__方法,因此,它们都可以用torch.utils.data.DataLoader进行数据加载。
__getitem__(index):
参数:index索引
返回:元组tuple(image,target),其中target是列表类型,包含了对图片image的描述。
二、torch.utils.data.DataLoader数据加载器
1.DataLoader完整参数
class torch.utils.data.DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None) DataLoader在数据集上提供单进程或多进程的迭代器
几个关键的参数意思:
--shuffle:设置为True的时候,每个epoch都会打乱数据集
--collate_fn:如何取样本的,我们可以定义自己的函数来准确的实现想要的功能
--drop_last:告诉如何处理数据集长度除以batch_size余下的数据。True就抛弃,否则保留
--pin_memory:锁页内存
主机中的内存,有两种存在方式,一是锁页,二是不锁页,锁页内存存放的内容在任何情况下都不会与主机的虚拟内存进行交换(注:虚拟内存就是硬盘),而不锁页内存在主机内存不足时,数据会存放在虚拟内存中。显卡中的显存全部是锁页内存,当计算机的内存充足的时候,可以设置pin_memory=True。当系统卡住,或者交换内存使用过多的时候,设置pin_memory=False。因为pin_memory与电脑硬件性能有关,pytorch开发者不能确保每一个炼丹玩家都有高端设备,因此pin_memory默认为False。
2.例子
import torch
import torch.utils.data as Data
"""
批训练,把数据变成一小批一小批数据进行训练。
DataLoader就是用来包装所使用的数据,每次抛出一批数据
"""
x = torch.linspace(1,10,10)
y = torch.linspace(10,1,10)
z = torch.linspace(1,10,10)
batch_size = 5
# 把数据放在数据库中
torch_dataset = Data.TensorDataset(x,y,z)
loader = Data.DataLoader(dataset=torch_dataset,batch_size=batch_size,shuffle=True,num_workers=2,)
def show_batch():
for epoch in range(3):
print("epoch",epoch)
for step,(batch_x,batch_y,batch_a) in enumerate(loader):
# training
print("steop:{}, batch_x:{}, batch_y:{},batch_z:{}".format(step, batch_x, batch_y,batch_a))
if __name__ == '__main__':
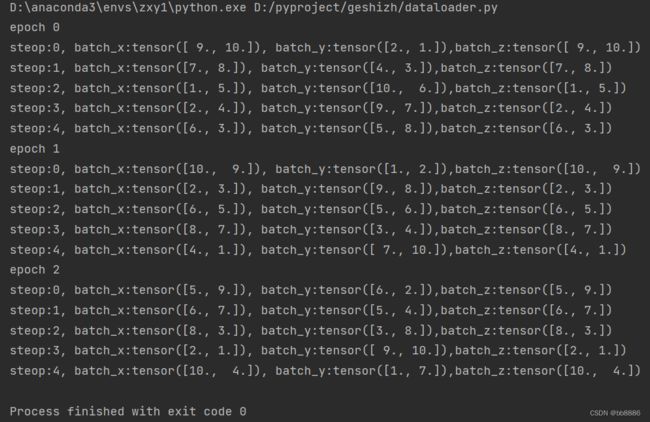
show_batch()运行结果
处理COCO等数据集时,过程如下:
# 1.COCO2014类里通过__getitem__方法得到train_dateset=(image,filename,emb),target形式
train_dataset = COCO2014(args.data, phase='train', annonymize=annonymize, inp_name=args.embedding)
# 2.将train_dataset传入DataLoader
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=workers)
#3.加载数据
for i, (input, target) in enumerate(data_loader):
# measure data loading time
self.state['iteration'] = i
self.state['data_time_batch'] = time.time() - end
self.state['data_time'].add(self.state['data_time_batch'])self.state['input'] = input
self.state['target'] = target